






题目描述:
使用oneMKL工具,对FFT算法进行加速与优化。
1.生成2048*2048个单精度实数作为输入数据
2.实现输入数据的两维Real to complex FFT
3.使用oneMKL FFT进行输入数据的两维Real to complex FFT
4.比较两种算法的性能及正确性。
oneMKL简介:
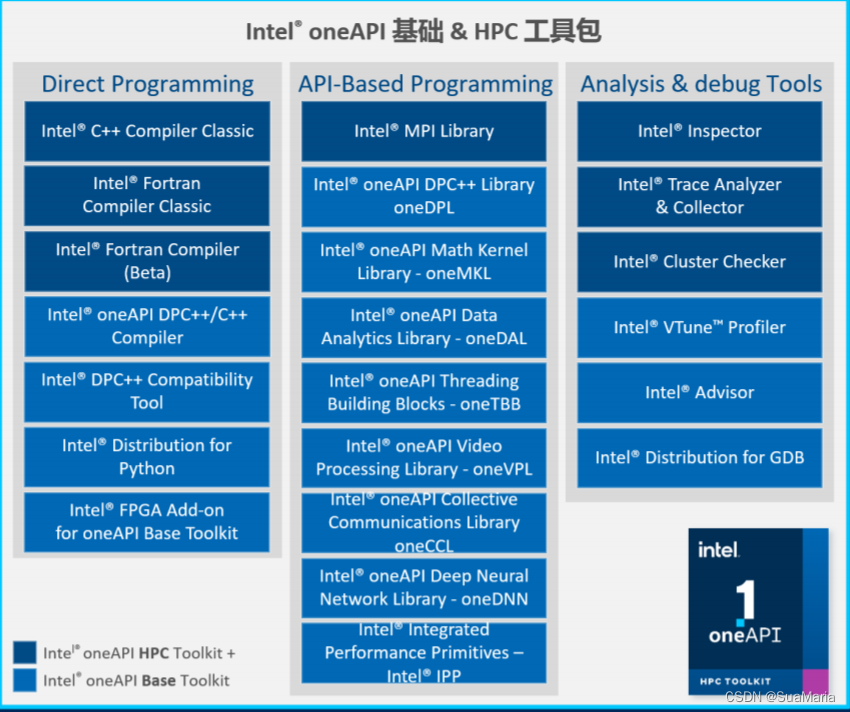
英特尔®oneAPI 数学内核库(Intel® oneAPI Math Kernel Library,简称 oneMKL)是一个开源规范,旨在简化希望创建基于加速器的应用程序和希望支持各种硬 件架构和硬件供应商的开发人员的生活。 oneAPI Base Toolkits 和 HPC Toolkits 的内容如下图所示:
Intel的OneMKL是一种数学核心库,旨在加速高性能计算应用程序的数学运算。它提供了一组数学和线性代数函数,专为使用Intel处理器的系统进行了优化。以下是一些关于Intel OneMKL的主要特点和用途:
-
高性能数学库:OneMKL提供了高度优化的数学函数,包括线性代数、傅立叶变换、随机数生成和特殊函数等。这些函数针对Intel处理器进行了优化,可以实现卓越的性能。
-
跨平台支持:OneMKL支持多种操作系统,包括Windows、Linux和macOS,并且可以与不同编程语言(如C/C++和Fortran)一起使用。
-
并行性支持:OneMKL通过利用多核处理器和向量化指令集来提高性能,从而使开发人员能够充分发挥现代多核处理器的潜力。
-
用途广泛:OneMKL适用于各种领域的应用程序,包括科学计算、工程仿真、深度学习、机器学习和数据分析等。它可以用于加速矩阵运算、信号处理、图像处理等各种数学运算。
-
免费提供:Intel OneMKL通常是免费提供给开发人员和研究人员的,可以与Intel的开发工具套件一起使用。
实现代码:
1.包含头文件
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#include "mkl_vsl.h"
#include "mkl_service.h"
#include "mkl_dfti.h"
#include <fftw3.h>
2.定义函数指针类型:通过typedef语句定义了一个名为FftMethod的函数指针类型,用于表示不同的傅立叶变换方法。
typedef void (*FftMethod)(int, float*, void*);
3.DoFftWithMkl函数:这个函数使用Intel OneMKL库执行傅立叶变换。它设置了一些DFTI(傅立叶变换接口)描述符,包括傅立叶变换的大小、输入和输出数据的设置,然后执行傅立叶变换。
void DoFftWithMkl(int size, float* input, void* output) {
MKL_LONG rs[3] = { 0, size, 1 };
MKL_LONG cs[3] = { 0, size / 2 + 1, 1 };
DFTI_DESCRIPTOR_HANDLE descriptor;
MKL_LONG sizeN[2] = { size, size };
DftiCreateDescriptor(&descriptor, DFTI_SINGLE, DFTI_REAL, 2, sizeN);
DftiSetValue(descriptor, DFTI_PLACEMENT, DFTI_NOT_INPLACE);
DftiSetValue(descriptor, DFTI_CONJUGATE_EVEN_STORAGE, DFTI_COMPLEX_COMPLEX);
DftiSetValue(descriptor, DFTI_INPUT_STRIDES, rs);
DftiSetValue(descriptor, DFTI_OUTPUT_STRIDES, cs);
DftiCommitDescriptor(descriptor);
DftiComputeForward(descriptor, input, (MKL_Complex8*)output);
DftiFreeDescriptor(&descriptor);
}
4.DoFftWithFftw函数:这个函数使用FFTW库执行傅立叶变换。它创建一个FFTW计划,执行傅立叶变换,然后销毁计划。
void DoFftWithFftw(int size, float* input, void* output) {
fftwf_plan plan = fftwf_plan_dft_r2c_2d(size, size, input, (fftwf_complex*)output, FFTW_MEASURE);
fftwf_execute(plan);
fftwf_destroy_plan(plan);
}5.CompareResults函数:这个函数用于比较两个不同库执行的傅立叶变换结果之间的差异。它计算实部和虚部的平均差异,并输出结果匹配与否以及平均差异的信息。
void CompareResults(int size, void* result1, void* result2, float epsilon) {
int match = 1;
double avgDiffReal = 0.0;
double avgDiffImag = 0.0;
for (int i = 0; i < size * (size / 2 + 1); i++) {
float diffReal = fabs(((MKL_Complex8*)result1)[i].real - ((fftwf_complex*)result2)[i][0]);
float diffImag = fabs(((MKL_Complex8*)result1)[i].imag - ((fftwf_complex*)result2)[i][1]);
if (diffReal > epsilon || diffImag > epsilon) {
match = 0;
}
avgDiffReal += diffReal;
avgDiffImag += diffImag;
}
if (match) {
printf("Results match!\n");
}
else {
printf("Results do not match!\n");
}
printf("Average difference (Real): %f\n", avgDiffReal / (size * (size / 2 + 1)));
printf("Average difference (Imag): %f\n", avgDiffImag / (size * (size / 2 + 1)));
}
6.
main函数:主函数包含以下步骤:
- 分配内存并初始化输入数组。
- 声明两个函数指针,分别指向
DoFftWithFftw和DoFftWithMkl。 - 初始化随机数生成器。
- 分配内存以保存两个傅立叶变换的输出结果。
- 使用两个不同的库执行傅立叶变换,并记录执行时间。
- 调用
CompareResults函数比较两个结果的差异。 - 释放分配的内存并结束程序。
int main() {
int size = 2048;
float epsilon = 10 ^ -5;
float* inputArray = (float*)malloc(sizeof(float) * size * size);
FftMethod fftMethod1 = DoFftWithFftw;
FftMethod fftMethod2 = DoFftWithMkl;
VSLStreamStatePtr stream;
vslNewStream(&stream, VSL_BRNG_MT19937, 1);
vsRngUniform(VSL_RNG_METHOD_UNIFORM_STD, stream, size * size, inputArray, 0.0f, 1.0f);
void* output1 = malloc(sizeof(fftwf_complex) * size * (size / 2 + 1));
void* output2 = malloc(sizeof(MKL_Complex8) * size * (size / 2 + 1));
clock_t startTime, endTime;
startTime = clock();
fftMethod1(size, inputArray, output1);
endTime = clock();
printf("Time taken by FFTW: %f seconds\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
startTime = clock();
fftMethod2(size, inputArray, output2);
endTime = clock();
printf("Time taken by INTEL_ONEMKL: %f seconds\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
CompareResults(size, output1, output2, epsilon);
free(inputArray);
free(output1);
free(output2);
return 0;
}
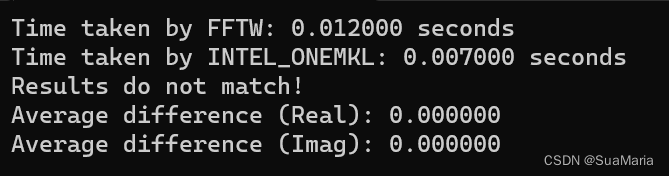
运行结果
oneMKL运算速度比FFTW快,性能更优。
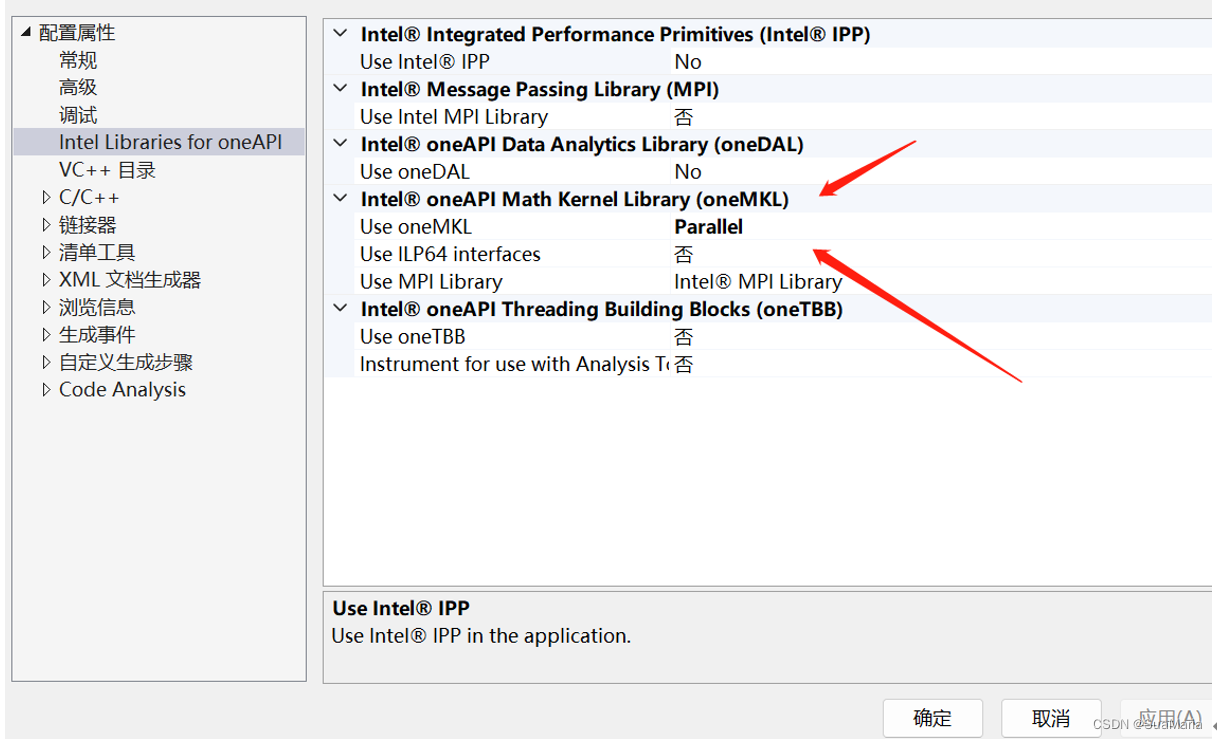
注意事项
在调用oneMKL库进行计算时,请确保正确链接到库,保持Use oneMKL为“Parallel”状态















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









