









Java8 Stream流式编程
简介
Java8中stream是用于对集合迭代器的增强,使之能供完成更高效的聚合操作(例如过滤、排序、统计分组等)或者大批量数据操作。此外,stream与lambda表达式结合后编码效率将会大大提高,并且可以提高可读性。
首先来看一个简单的场景,准备工作如下,编写了一个person类:
public class Person {
/**
* 姓
*/
private String lastname;
/**
* 名
*/
private String name;
private Integer age;
private String sex;
private String address;
// 省略了构造函数、getter和setter方法以及toString()方法,读者可使用idea生成
}
接下来看看我们的一些需求:
- 假如我们要寻找以"王"为姓的人,那么我们该如何做呢?传统方法就是for循环遍历判断,然后加入结果集,但是这里如果用到stream的话,可以一行代码搞定(详细代码稍后列出)
- 假如我们要根据性别统计用户的平均年龄,那么我们该如何做呢?传统方法:首先就是根据不同的性别进行分组,然乎对两个分组求平均值,stream也可以一行代码搞定。
说的这么神奇,来看看具体的代码吧:
public class LearnStream {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
LearnStream learnStream = new LearnStream();
List<Person> ps = learnStream.searchLastname("王");
ps.forEach(person -> System.out.println(person.toString()));
List<Person> personList = learnStream.searchByParams(person -> person.getLastname().equals("王") && person.getAge() > 22);
personList.forEach(p -> System.out.println(p.toString()));
Map<String, Double> average = learnStream.average();
average.forEach((k, v) -> System.out.println(k + ":" + v));
}
/**
* 查找以lastname为姓的人
* @param lastname
*/
public List<Person> searchLastname(String lastname) {
List<Person> results = persons.stream()
.filter(person -> person.getLastname().equals(lastname))
.collect(Collectors.toList());
return results;
}
/**
* 自定义lambda表达式参数
* @param predicate
* @return
*/
public List<Person> searchByParams(Predicate<? super Person> predicate) {
List<Person> collect = persons.stream().filter(predicate).collect(Collectors.toList());
return collect;
}
/**
* 统计男性或女性的平均年龄
* @return
*/
public Map<String, Double> average() {
// groupingBy按照某个属性分组
Map<String, List<Person>> collect = persons.stream().collect(Collectors.groupingBy(person -> person.getSex()));
// 先分组,然后在分组内按照某个属性计算其平均值
Map<String, Double> res = persons.stream()
.collect(Collectors.groupingBy(person -> person.getSex(), // 基于性别分组
Collectors.averagingDouble(persons -> persons.getAge()))); // 基于年龄求分组平均值
return res;
}
}
代码的运行结果如下:

通过上面的案例是不是可以发现,stream的代码其实很简单,一行搞定我们的需求,比传统的方法要高效很多。
stream出现背景
像这种遍历的方式,我们有没有更简单的实现方法呢?答案肯定是有的,通常情况下,我们的数据是存储在数据库中,当我们使用SQL语句查询数据的时候直接做好处理比在Java程序中写这些代码要简单的多。上面的需求可以通过如下SQL语句实现:
# 获取所有姓王的用户
select * from person where lastname='王';
# 根据性别统计平均年龄
select p.sex, average(p.age) from person as p group by sex;
通过一个sql语句就能实现我们上面Java代码中的功能,而且简单易懂,效率也比较高。
在传统的JavaEE项目中数据源单一且集中,像上面的需求我们可以通过SQL语句进行计算。但是现在互联网项目的数据源多样化,包括:关系数据库、NoSQL、Redis、mongodb、ElasticSerach等。此时,我们需要从各种数据源中聚集数据并进行统计,在stream出现之前,使用传统的for循环遍历非常繁琐,stream出现之后,这种局面就改变了。
Stream大大简化了我们的开发,结合lambda表达式更是效率神器。
lambda表达式
lambda表达式也可以称为闭包,它是推动Java8发布的最重要新特性,lambda允许把函数作为一个方法参数传递给方法。
在Java8之前,如果我们新创建一个线程对象,需要使用匿名内部类传递我们要执行的任务,在Java8我们可以使用lambda简化这种操作,例如:
public static void main(String[] args) {
// 匿名内部类
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("使用匿名内部类");
}
}).start();
// lambda表达式
new Thread(() -> System.out.println("使用lambda")).start();
}
从上面的代码中,我们可以看出lambda的简洁,比匿名内部类少写了很多代码(其实它的底层原理还是匿名内部类)。可以看看编译后的字节码(只包含lambda表达式的代码),从中可以发现它底层还是使用了匿名内部类:

函数式接口
上述的这种直接使用lambda是如何实现的呢?我们来看看Runnable的源码:

它是一个接口,而且它被注解@FunctionalInterface标注,这证明它是一个函数式接口,通过函数式接口我们可以使用lambda表达式来进行编码。
那么什么是函数式接口呢?它必须满足如下条件:
- 函数式接口只能包含一个方法(想想也对,我们使用lambda表达式不会指定实现哪个方法,所以只能有一个方法,然后lambda表达式就是对这个方法的实现)
- 可以包含多个默认方法(默认方法相当于已经实现的方法,默认方法不会影响lambda表达式对接口方法的实现)
- Object类下的方法不计算在内,例如:toString()、equals()、hashCode()等方法。
满足上述条件的接口就是函数式接口,那么@FunctionalInterface注解的作用是什么呢?
其实只要满足上述条件,没有@FunctionalInterface注解标注也是函数式接口,该注解的作用就是帮我们辨别一个接口是否是函数式接口,如果不是的话,在编译阶段就会报错。
例如:
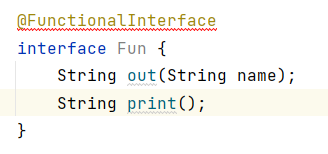
上面这个接口就不是函数式接口,idea会很智能的提示我们编码错误。
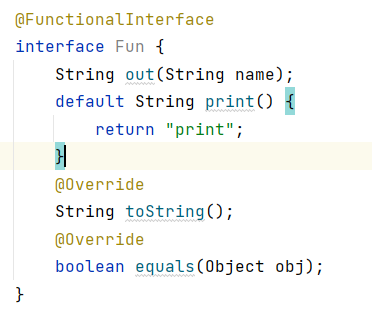
当我们为部分方法提供默认实现,让接口中的方法只有一个时,这个函数式接口就成立了。
函数式接口是lambda表达式的前提,我们需要先编写函数式接口才能继续使用lambda表达式。
编写lambda表达式
在编写lambda之前,我们需要先编写一个函数式接口,如下:
@FunctionalInterface
public interface Function {
/**
* 输出姓名和年龄
* @param name
* @param age
* @return
*/
void print(String name, int age);
}
然后根据函数式接口传递参数,并且使用lambda表达式实现函数式接口:
public class MyLambda {
public static void main(String[] args) {
print((name, age) -> System.out.println(String.format("name: %s, age: %s", name, age)));
}
public static void print(Function function) {
function.print("王大", 23);
}
}
来看看运行结果:
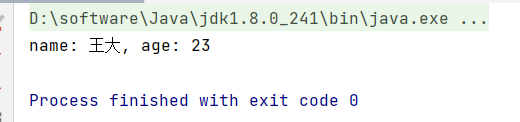
这里的lambda表达式就相当于函数式接口的实现类,我们对函数式接口的方法调用的最终实现就是这个lambda表达式的内容,这里就是将我们传入的姓名和年龄转换为一个固定的格式,然后输出。
当lambda表达式没有参数时,可以直接以print(() -> System.out.println())这种形式书写,以空括号开始即可;如果lambda表达式只有一个参数的话,可以省略括号,例如print(name -> System.out.println(name)),这里的参数可以带类型,也可以不带,看个人习惯;而且使用lambda表达式也可以省略return语句。
lambda表达式的特性:
- 单行表达式,如果有返回值可以省略return,如上面的代码所示
- 代码块
print((name, age) -> {
String format = String.format("name: %s, age: %s", name, age);
System.out.println(format);
});
在多行表达式中,如果有返回值不能省略return
- 方法引用,我们可以将lambda表达式的实现逻辑封装成一个方法,然后直接在lambda表达式函数中调用封装好的方法,称为方法引用,方法引用包括静态方法引用和动态方法引用
public class MyLambda {
public static void main(String[] args) {
// 静态方法引用
print(MyLambda::format);
// 普通方法引用
print(new MyLambda()::f);
}
public static void format(String name, int age) {
System.out.println(String.format("name: %s, age: %s", name, age));
}
public void f(String name, int age) {
System.out.println(String.format("name: %s, age: %s", name, age));
}
public static void print(Function function) {
function.print("王大", 23);
}
}
Stream执行机制
Stream的执行机制就是首先通过数据源生成Stream,然后对这个Stream进行我们需要的操作,例如分组、排序、过滤等,然后采集结果输出最终的数据。
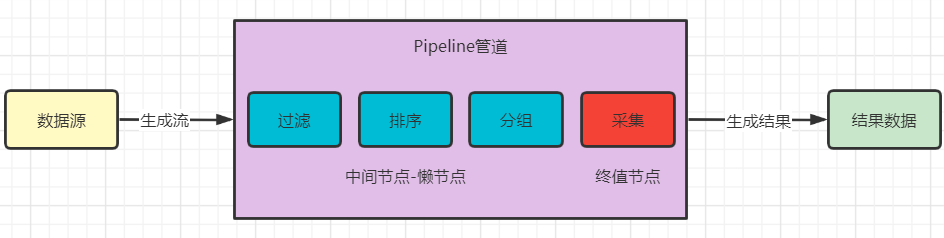
Stream特性
流的特性有哪些呢?
- stream不存储数据
- stream不改变源数据
- stream不可重复使用
首先我们来看看流的产生方式:
persons.stream(); // List<Person> persons = new ArrayList<>();
Arrays.stream(new int[] {1, 2, 3, 4, 5, 6});
Stream.of(1, 2, 3, 4);
接下来可以看看stream是不可重复使用的,当我们使用一次流之后,再重复使用时会报错,例如:
public class StreamFeatures {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
Stream<Person> stream = persons.stream();
Stream<Person> first = stream.filter(person -> person.getLastname().equals("王"));
Stream<Person> second = stream.filter(person -> person.getAge() > 21);
}
}
运行结果如下:

当我们重复使用stream这个流时,就会报IllegalStateException异常,提示我们stream已经被操作过。
为什么stream流不能重复使用呢?因为流是串联起来的,从Stream的执行机制我们可以发现,stream是经过管道操作,刚开始产生的stream会作为输入进行下一次的操作,stream只能顺序执行,不能对同一stream进行不同的操作。所以当我们对stream进行两次不同的操作时会发生异常。
从最初的stream执行机制图中,我们可以发现,stream流在执行的过程中包括中间节点和终值节点;这些不同的节点就代表了不同的操作,对同一stream的所有操作组合在一起就变成了管道,管道中包含如下操作:
- Intermediate(中间操作):调用中间操作方法会产生一个新的stream流,通过连续执行多个操作就组成了Stream中的执行管道,需要注意的是这些管道被添加后并不会真正执行,只有等到调用终值操作后才会执行
- Terminal(终值操作):在调用该方法后会执行之前所有的中间操作,获取返回结果,并结束对流的使用
- Short-circuiting:对于一个 intermediate 操作,如果它接受的是一个无限大(infinite/unbounded)的 Stream,但返回一个有限的新 Stream;对于一个 terminal 操作,如果它接受的是一个无限大的 Stream,但能在有限的时间计算出结果
此外,数据源在stream流中的传递过程是一个一个进行的,就是从第一个数据源开始传递,经过不同的操作,产生不同的结果,例如:
public class StreamFeatures {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
// 上一个节点的操作可以影响下一个节点
persons.stream()
.peek(person -> System.out.println(person.getName())) // peek可以执行一个函数,相当于中间节点
.peek(person -> System.out.println(person.getAge()))
.toArray();
}}
上述代码的执行结果就是名字和年龄交替打印,这就证明了数据源里面的数据是一条条的传递的:
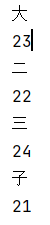
stream流在执行过程中,上一个节点的操作会影响下一个节点,影响方式包括:
- 过滤
- 转换:当我们使用map后,会将person类转变成person类对应的属性或者其他的值等,而且转换后会影响后续操作
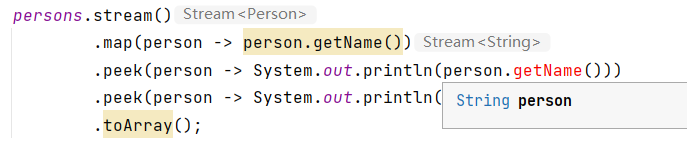
- 去重
首先看看未去重的版本:

加上distinct函数对stream流进行去重的结果:
我们可以对其进行调试,看看IDEA强大的调试功能:


从上面的调试过程可以看出对Stream流的每一步操作。
Stream实践
常见的流操作的分类如下:
Intermediate
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
Terminal
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
Short-circuiting
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
当我们对Stream进行操作时,往往会产生中间结果,这些中间结果就是Optional包装类,所以我们先来了解一下Optional的具体作用。
Optional
Optional通过泛型来包装不同的值,这个值可能为null,也可能不为null,它相当于一个可选值的包装类。
在实际开发中,我们如果使用Optional来包装一个可能的null值的话,可以帮助我们减少大量的if else判断,首先来看看Optional包含哪些方法。
public final class Optional<T> {
// 创造一个包含空值的Optional
private static final Optional<?> EMPTY = new Optional<>();
// Optional包装的值
private final T value;
// 私有构造函数,不对外公开,构造一个包含空值的Optional
private Optional() {
this.value = null;
}
// 暴露给用户使用的静态方法,用于构造一个包含空值的Optional
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
// 私有构造函数,构造一个包含非空值的Optional
private Optional(T value) {
this.value = Objects.requireNonNull(value);
}
// 静态方法,构造一个包含非空值的Optional
public static <T> Optional<T> of(T value) {
return new Optional<>(value);
}
// 静态方法,根据传入的参数是否为空选择创建不同的Optional
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
// 获取Optional包装的值
public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
// 判断Optional包装的值是否为空
public boolean isPresent() {
return value != null;
}
// 如果Optional包装的值不为空,对其进行操作
public void ifPresent(Consumer<? super T> consumer) {
if (value != null)
consumer.accept(value);
}
// 过滤
public Optional<T> filter(Predicate<? super T> predicate) {
Objects.requireNonNull(predicate);
if (!isPresent())
return this;
else
return predicate.test(value) ? this : empty();
}
// 将一个值转换为另一个值
public<U> Optional<U> map(Function<? super T, ? extends U> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Optional.ofNullable(mapper.apply(value));
}
}
// map()只有当值不被包裹时才进行转换,而flatmap()接受一个被包裹着的值并且在转换之前对其解包
public<U> Optional<U> flatMap(Function<? super T, Optional<U>> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Objects.requireNonNull(mapper.apply(value));
}
}
// 如果Optional包装的值为空,那么返回我们提供的other值,相当于给一个默认值
public T orElse(T other) {
return value != null ? value : other;
}
// Optional包装的值为空时,会根据我们提供的函数式接口获取对应的值
// 当值存在时,orElse相比于orElseGet,多创建了一个对象
public T orElseGet(Supplier<? extends T> other) {
return value != null ? value : other.get();
}
// Optional包装的值为空时,会根据我们提供的函数式接口抛出异常
public <X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier) throws X {
if (value != null) {
return value;
} else {
throw exceptionSupplier.get();
}
}
// 省略了equals、hashcode、toString方法
}
通过它的这些方法,我们可以可以很简单的对一个可能为null的值进行操作。
Optional的链式编程,可以帮助我们简化开发工作,当然我们要正确使用Optional才能简化我们的开发,否则和直接使用if else是差不多的。
Optional提供了isPresent判断Optional包装的值是否为null,那么我们这样使用就是错误的例子:
public String getName(User user){
Optional<User> u = Optional.ofNullable(user);
if(!u.isPresent()){
return "Unknown";
}else return u.get().name();
}
这样还不如直接使用if else,那么正确的使用方法是什么呢?
public String getName(User user){
return Optional.ofNullable(user).map(u -> u.name).orElse("Unknown");
}
上面这种写法是不是清晰多了,所以我们学会使用Optional的好处是非常多的,这仅仅是冰山一角。
有关Optional的其他用法可以自己去探索哦,有关Optional出现的意义,可以参考知乎的这篇文章:Java 8 中的 Optional 的优点究竟在哪里?
Stream遍历(forEach,findFirst,findAny)
- forEach:用于遍历Stream流的全部元素
- findFirst:寻找stream流的第一个元素,可以和filter一起使用,寻找满足条件的第一个值
- findAny:寻找stream流的任意值,可以和filter一起使用,寻找满足条件的任意一个值
public class StreamFeatures {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
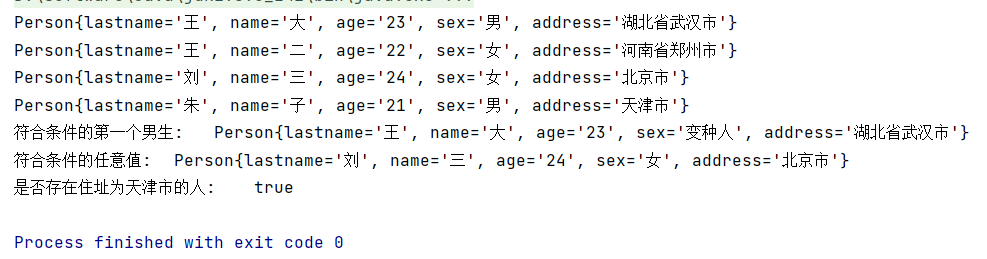
public static void main(String[] args) {
persons.stream().forEach(person -> System.out.println(person));
// filter过滤,findFirst寻找满足条件的第一个结果
Optional<Person> first = persons.stream().filter(person -> person.getSex().equals("男")).findFirst();
// findAny寻找满足条件的任何一个结果
Optional<Person> any = persons.stream().filter(person -> person.getAge() > 23).findAny();
// 判断是否存在满足条件的值
boolean exist = persons.stream().anyMatch(person -> person.getAddress().equals("天津市"));
// ifPresent方法,如果person不为空则对其进行操作,为空则不进行任何操作
first.ifPresent(person -> person.setSex("变种人"));
// 输出结果
System.out.println("符合条件的第一个男生:\t" + first.get());
System.out.println("符合条件的任意值:\t" + any.get());
System.out.println("是否存在住址为天津市的人:\t" + exist);
}
}
运行结果如下:
Stream过滤(filter)
我们可以通过filter对Stream进行过滤,寻找满足我们条件的结果,例如:
public class StreamFeatures {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
persons.stream().filter(person -> person.getSex().equals("男")).forEach(person -> System.out.println(person));
}
}
运行结果如下:

在实际的使用场景中,过滤操作非常有用。
Stream求极值(max,min,count)
- max,min:根据我们给定的排序规则分别求stream流中包含元素的最大最小值
- count:计算stream流中元素的个数,结合filter使用可以计算满足条件的元素个数
public class LearnStream {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
// 根据给定的排序规则选择最大值
// 求min的操作也是一样的,根据给定的排序规则选择最小值
Person person = persons.stream().max((p1, p2) -> {
if (p1.getAge() > p2.getAge()) {
return 1;
} else {
return -1;
}
}).get();
System.out.println(person);
// 求stream流中元素的个数
System.out.println("男员工的数量:" + persons.stream().filter(person1 -> person1.getSex().equals("男")).count());
}
}
运行结果如下:
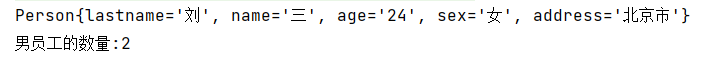
Stream映射(map,flatMap)
- map:通过我们给定的映射规则,将stream中的每个元素都映射成一个新的元素
- flatMap:将流中的每个值都换成另一个流,然后把所有流连接成一个流。
有关map和flatMap的区别可以看这篇博客:java8Stream map和flatmap的区别
public class LearnStream {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
System.out.println("map之前的persons=====");
System.out.println(persons.get(0));
// 修改对象的属性值
List<Person> update = persons.stream().map(person -> {
person.setAge(person.getAge() + 10);
person.setAddress("长沙");
return person;
}).collect(Collectors.toList());
// 改变对象的类型
List<String> collect = persons.stream().map(person -> person.getName()).collect(Collectors.toList());
System.out.println("map之后的persons=====");
System.out.println(update.get(0));
System.out.println(collect.get(0));
}
}
我们在使用map的过程中,可以将对象属性值映射为其他的值,也可以将对象的类型映射为其他的类型。上述代码的运行结果如下:

假设我们要获取[“Hello”,“World”]包含的所有字母,并返回,我们可以用for循环实现,但是使用flatMap实现更简单:
public static void main(String[] args) {
// 创建stream流
Stream<String> stream = Arrays.stream(new String[]{"Hello", "World"});
// 对stream流进行操作
List<String> collect = stream.flatMap(word -> Stream.of(word.split(""))).collect(Collectors.toList());
collect.forEach(w -> System.out.print(w + "\t"));
}
Stream归约操作(reduce)
归约也就是将Stream流中的元素归并为一个值,可以实现对集合求和、求成绩以及求最值的操作。接下来看看究竟如何使用吧。
public static void main(String[] args) {
List<Integer> integers = Arrays.asList(1, 3, 4, 32, 51, 2, 40);
// 求和
Optional<Integer> sum1 = integers.stream().reduce((x, y) -> x + y);
Optional<Integer> sum2 = integers.stream().reduce(Integer::sum);
Integer sum3 = integers.stream().reduce(0, Integer::sum);
// 求乘积
Optional<Integer> mul = integers.stream().reduce((x, y) -> x * y);
// 求最大值
Optional<Integer> max1 = integers.stream().reduce(Integer::max);
Optional<Integer> max2 = integers.stream().reduce((x, y) -> x > y ? x : y);
System.out.println("list和为:" + sum1.get() + "," + sum2.get() + "," + sum3);
System.out.println("list乘积为:" + mul.get());
System.out.println("list最大值为:" + max1.get() + "," + max2.get());
}
运行结果如下:
list和为:133,133,133
list乘积为:1566720
list最大值为:51,51
上述代码是最简单的示范,在实际使用过程中,我们可以根据自己的业务需求,根据不同的属性求对象的最大值最小值或者乘积等等。
Stream之collect
Stream流是不存储数据的,所以在流中的数据处理完成之后,需要将流中的数据重新归并到集合中,这样才能供我们后续的使用。
将流中的数据收集到集合中有如下几种函数,分别是:toList、toSet、toMap,接下来看看这几种方式。
public class LearnStream {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
System.out.println("=====List=====");
List<Person> list = persons.stream().collect(Collectors.toList());
list.forEach(person -> System.out.println(person));
System.out.println("=====Set=====");
Set<Person> set = persons.stream().collect(Collectors.toSet());
set.forEach(person -> System.out.println(person));
System.out.println("=====Map=====");
// toMap的第一个参数为key的产生规则,第二个参数为value的产生规则
Map<String, Person> map = persons.stream().collect(Collectors.toMap(person -> person.getName(), person -> person));
map.forEach((key, val) -> System.out.println(key + ":" + val));
}
通过上述代码可以很轻松的将stream转换为list、set以及map。
此外,我们还可以对Stream进行分区和分组:
- 分区:将stream按照条件分为两个map,比如按照员工年龄是否大于35或者入职年限是否大于10分为两部分
- 分组:将stream分为多个map,例如按照员工的姓进行分组等
public class LearnStream {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
// Collectors.groupingBy按照指定条件分组
Map<String, List<Person>> lastnameMap = persons.stream().collect(Collectors.groupingBy(person -> person.getLastname()));
lastnameMap.forEach((key, value) -> {
System.out.println("员工的姓为:" + key);
value.forEach(person -> System.out.println(person));
});
// Collectors.partitioningBy按照指定条件分区,将stream分为两部分
Map<Boolean, List<Person>> ages = persons.stream().collect(Collectors.partitioningBy(person -> person.getAge() >= 23));
ages.forEach((key, value) -> {
System.out.println("员工年龄是否大于等于23:" + key);
value.forEach(person -> System.out.println(person));
});
}
通过collect我们还可以对数据进行统计工作,主要包括:
- 计数:count
- 平均值:averagingInt、averagingLong、averagingDouble
- 最值:maxBy、minBy
- 求和:summingInt、summingLong、summingDouble
- 统计以上所有:summarizingInt、summarizingLong、summarizingDouble
例如:
public static void main(String[] args) {
List<Integer> list = Arrays.asList(13, 23, 84, 9, 20, 41);
// 求集合的数量
Long count = list.stream().collect(Collectors.counting());
// 求集合的均值,其中Integer::doubleValue是方法调用,通过方法调用给Collectors.averagingDouble提供计算依据
Double average = list.stream().collect(Collectors.averagingDouble(Integer::doubleValue));
// 这里如果是使用的普通对象的话,可以将我们要计算的平均值:年龄、工资等的getter方法传递给该函数,例如:
Double ageAverage = persons.stream().collect(Collectors.averagingInt(Person::getAge));
// 求集合的最大值
Integer max = list.stream().collect(Collectors.maxBy(Integer::compare)).get();
// 求集合的总和
Integer sum = list.stream().collect(Collectors.summingInt(Integer::intValue));
// 求集合的上述所有数据
IntSummaryStatistics intSummaryStatistics = list.stream().collect(Collectors.summarizingInt(Integer::intValue));
System.out.println("集合总数为:" + count);
System.out.println("集合平均值为:" + average);
System.out.println("集合最大值为:" + max);
System.out.println("集合总和为:" + sum);
System.out.println(intSummaryStatistics);
}
通过Collectors的不同函数可以对stream流的数据进行统计,上述代码的运行结果如下:
集合总数为:6
集合平均值为:31.666666666666668
集合最大值为:84
集合总和为:190
IntSummaryStatistics{count=6, sum=190, min=9, average=31.666667, max=84}
遇到其他的业务需求可以在上面的代码之上根据自己的需要做出一定的改变即可。
collect还提供了joining操作,可以根据指定的条件对字符串进行连接操作,例如:
public class LearnStream {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
String join = persons.stream().map(person -> person.getName()).collect(Collectors.joining("==="));
System.out.println("员工的名字连接后的结果为:" + join);
Stream<String> stream = Arrays.stream(new String[]{"h", "e", "l", "l", "o"});
String joining = stream.collect(Collectors.joining("-"));
System.out.println("字符串join的结果:" + joining);
}
}
运行结果如下:
员工的名字连接后的结果为:大===二===三===子字符串join的结果:h-e-l-l-o
最后,collect还提供了reducing归约操作:
public class LearnStream {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
Integer ageSum = persons.stream().collect(Collectors.reducing(0, Person::getAge, Integer::sum));
// 效率更高,先使用map操作,再使用sum
int sum = persons.stream().mapToInt(Person::getAge).sum(); System.out.println(ageSum);
System.out.println(sum);
}
}
例如我们通过collect的归约操作求员工的年龄总和,reducing操作就是将两个值合并成一个值,其中前两个参数是要合并的值,最后一个参数是对前两个参数的操作(加、减、乘、除等)。
Stream之排序
- sorted():不提供排序规则的话,流中元素必须自己实现Comparable接口
- sorted(Comparator<? super T> comparator):根据自定义的排序规则对流中的元素进行排序操作
当我们要对员工按照年龄进行排序时,可以这样做:
public class LearnStream {
private static List<Person> persons = new ArrayList<>();
static {
persons.add(new Person("王", "大", 23, "男", "湖北省武汉市"));
persons.add(new Person("王", "二", 22, "女", "河南省郑州市"));
persons.add(new Person("刘", "三", 24, "女", "北京市"));
persons.add(new Person("朱", "子", 21, "男", "天津市"));
}
public static void main(String[] args) {
List<Person> personList = persons.stream().sorted((p1, p2) -> {
if (p1.getAge() > p2.getAge()) {
return 1;
} else {
return -1;
}
}).collect(Collectors.toList());
for (Person person : personList) {
System.out.println(person);
}
}
}
这样我们最终得到的结果就是根据员工的年龄排序后的list。
Stream之合并、去重
public static void main(String[] args) {
String[] first = new String[] {"hello", "world"};
String[] second = new String[] {"learn", "java", "hello", "world"};
Stream<String> first1 = Stream.of(first);
Stream<String> second1 = Stream.of(second);
// 使用concat进行两个流的合并操作
List<String> collect = Stream.concat(first1, second1).distinct().collect(Collectors.toList());
System.out.println("合并之后的流为:");
collect.forEach(s -> System.out.print(s + "\t"));
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9);
// 使用limit限制操作流中的哪些元素
List<Integer> collect1 = integerStream.limit(5).collect(Collectors.toList());
System.out.println();
System.out.println("limit,限制取stream的前5个元素:");
collect1.forEach(v -> System.out.print(v + "\t"));
Stream<Integer> integerStream1 = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9);
// 使用skip规定跳跃对流中哪些元素的操作
List<Integer> collect2 = integerStream1.skip(5).collect(Collectors.toList());
System.out.println();
System.out.println("skip,跳过stream的前5个元素:");
collect2.forEach(v -> System.out.print(v + "\t"));
}
上述代码的运行效果如下:
合并之后的流为:
hello world learn java
limit,限制取stream的前5个元素:
1 2 3 4 5
skip,跳过stream的前5个元素:
6 7 8 9
Stream之anyMatch,allMatch,noneMatch
- anyMatch:判断是否有满足条件的任意项
- allMatch:判断全部元素是否都满足条件
- noneMatch:判断全部元素是否都不满足条件
例如:
public static void main(String[] args) {
String[] first = new String[] {"hello", "world"};
String[] second = new String[] {"learn", "java", "hello", "world"};
Stream<String> first1 = Stream.of(first);
Stream<String> second1 = Stream.of(second);
boolean h = first1.anyMatch(s -> s.startsWith("h"));
boolean l = second1.allMatch(s -> s.startsWith("l"));
boolean w = Stream.of(first).noneMatch(s -> s.startsWith("w"));
System.out.println("anyMatch,是否有满足条件的任意元素:" + h);
System.out.println("allMath,全部元素是否都满足条件:" + l);
System.out.println("noneMatch,是否全部不满足条件:" + w);
}
运行结果如下:
anyMatch,是否有满足条件的任意元素:true
allMath,全部元素是否都满足条件:false
noneMatch,是否全部不满足条件:false
Stream之parallel
parallelStream是并行执行的流,并行就是所有的线程同时执行,充分利用CPU的多核特性,每个核心运行一个线程,可以提高程序的运行效率(并发是同一CPU核心交替的执行线程,由于执行时间很短,给人一种同时执行的错觉,这就是并发与并行的区别)。parallelStream通过默认的ForkJoinPool来提高多线程任务的速度。来看一个使用parallelStream的例子:
public static void main(String[] args) {
String[] first = new String[] {"learn", "java", "hello", "world", "redis", "mysql", "mq", "cloud", "nginx"};
System.out.println("parallel stream 打印:");
Stream.of(first).parallel().forEach(s -> System.out.print(s + " "));
System.out.println();
System.out.println("parallel stream 顺序打印:");
Stream.of(first).parallel().forEachOrdered(s -> System.out.print(s + " "));
}
通过使用paraller对Stream进行遍历,来看看它的运行结果:
parallel stream 打印:
mysql redis mq learn nginx cloud java hello world
parallel stream 顺序打印:
learn java hello world redis mysql mq cloud nginx
从上面的运行结果可以看出,使用forEach进行遍历,打印的元素是无序的,因为是并行执行的,所以每个线程运行的先后顺序不一定,所以就出现了乱序;如果想要顺序打印对应的元素,可以使用forEachOrdered,该方法在多线程的运行环境下保证了程序的顺序性。
总结
随着数据来源的多样化(包括sql和nosql数据库),存储数据的不同数据库可能无法支持我们需要的全部操作,那么对数据的处理就落到了编程语言的层面。我们通过使用for循环和if else遍历并处理元素可能需要嵌套多层循环,这时候我们就需要一种工具简化开发操作,因此Stream应运而生,通过Stream可以减少我们的代码量,并且很轻松的就能实现我们的需求。
但是,在使用Stream的过程中,我们要掌握正确的使用方法,否则和使用if else没有太大的差别。本文讲述的这些方法可以覆盖日常的大部分使用,熟练掌握可以提高我们的开发效率。从上面的讲解中可以发现,lambda表达式在stream中可谓是大显身手,所以,掌握lambda表达式也是必须的。
最后再来一句,熟能生巧,我们用的多了,自然就会记住,等会用了才能更好的了解它的原理。















 2620
2620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









