







第一章 绪论
基本术语
-
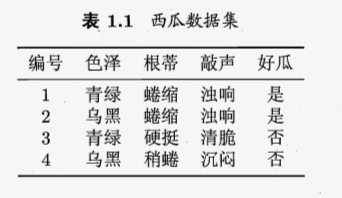
D={X1,X2,X3,…,Xm}表示包含m个示例的数据集。第一个示例X1={xi1,xi2,…,xid}是d维样本空间X重的一个向量,Xij是Xi在第j个属性上的取值,例如第三个西瓜在第一个属性上的取值为青绿。
-
预测模型:我们欲预测的是离散值,例如判断西瓜只有好和坏之分(0,1)
-
回归模型:我们欲预测的是连续值,例如西瓜的成熟度0.95,0.37
-
监督学习:训练数据集有标记信息,代表是分类和回归
-
无监督学习:训练数据集没有标记信息,代表是聚类
-
泛化能力:机器学习学得的模型适用于新样本的能力
归纳偏好
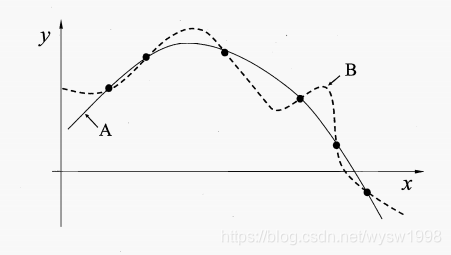
- 假设点分布在平面上(如图所示),有无数条线可以穿过这些数据点,根据Occam’ razor(奥卡姆剃刀)原则:若有多个假设与观察一致,则选最简单的那个,那我们假设平缓为最简单,那么就应该选择A曲线。
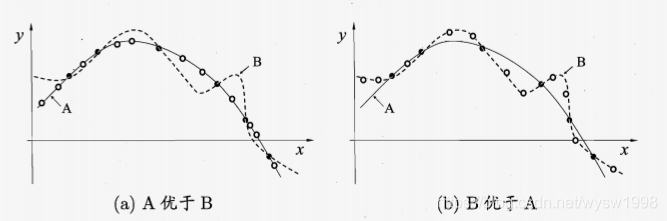
- 归纳偏好对应了学习算法本身所做出的关于“什么样的模型更好”的假设,我们很难说适用于一个数据的模型就一定适用于另外一个数据,这是显而易见的。
- 通过对总误差的求解我们发现,总误差与学习算法无关
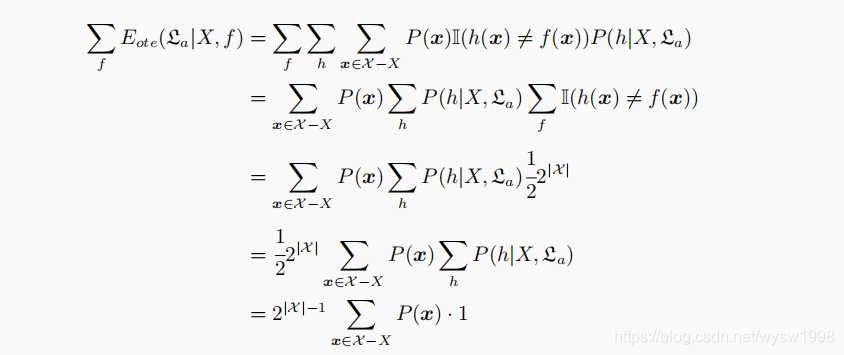

- No Free Lunch Theorem (NFL定理):在所有问题出现的机会相同、或所有问题同等重要的前提下,无论学习算法Ea多聪明,学习算法Eb多笨拙,它们的期望性能都相同的。NFL定理最重要的寓意是告诉我们脱离具体问题空谈最优学习算法是毫无意义的。














 2070
2070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









