









这是我的第二场kaggle竞赛(20th top5% 银牌),其实我觉得还能取得更好的名次的,由于实验室机子有限,还有一些想法都没有实验。不过这次比赛比上次比赛学到了更多东西,下面我将把在这次比赛中的感受和心得分享给大家。

一. 比赛背景及任务介绍
- 背景介绍
参考官方overview。 - 任务介绍
识别每张艺术品中所包含的culture和tag,大部分图片中含有多个标签,因此该比赛是一个multi-label classification的任务。 - 评价指标
f2 score: ( 1 + β 2 ) p r β 2 p + r where p = t p t p + f p , r = t p t p + f n , β = 2 \frac{\left(1+\beta^{2}\right) p r}{\beta^{2} p+r} \text { where } p=\frac{t p}{t p+f p}, \quad r=\frac{t p}{t p+f n}, \beta=2 β2p+r(1+β2)pr where p=tp+fptp,r=tp+fntp,β=2 - 数据集介绍
训练集有109237张,测试集分为两个阶段:第一阶段有7443张,训练好模型所提交的LB分数就是在该测试集上测试的;由于该比赛是一个kernel-only的比赛,即提交的submission必须是经过kaggle上的kernel运行提交的。待比赛提交日期结束后,官方会更新第二阶段的unseen测试集(大小为5.2倍于test1 ),由官方对参赛人员所选的kernel进行测试,得到最终private score. - 数据分析(EDA)
这一步特别重要!!! 为了表达的更清楚点,我想分为以下几点来说明:
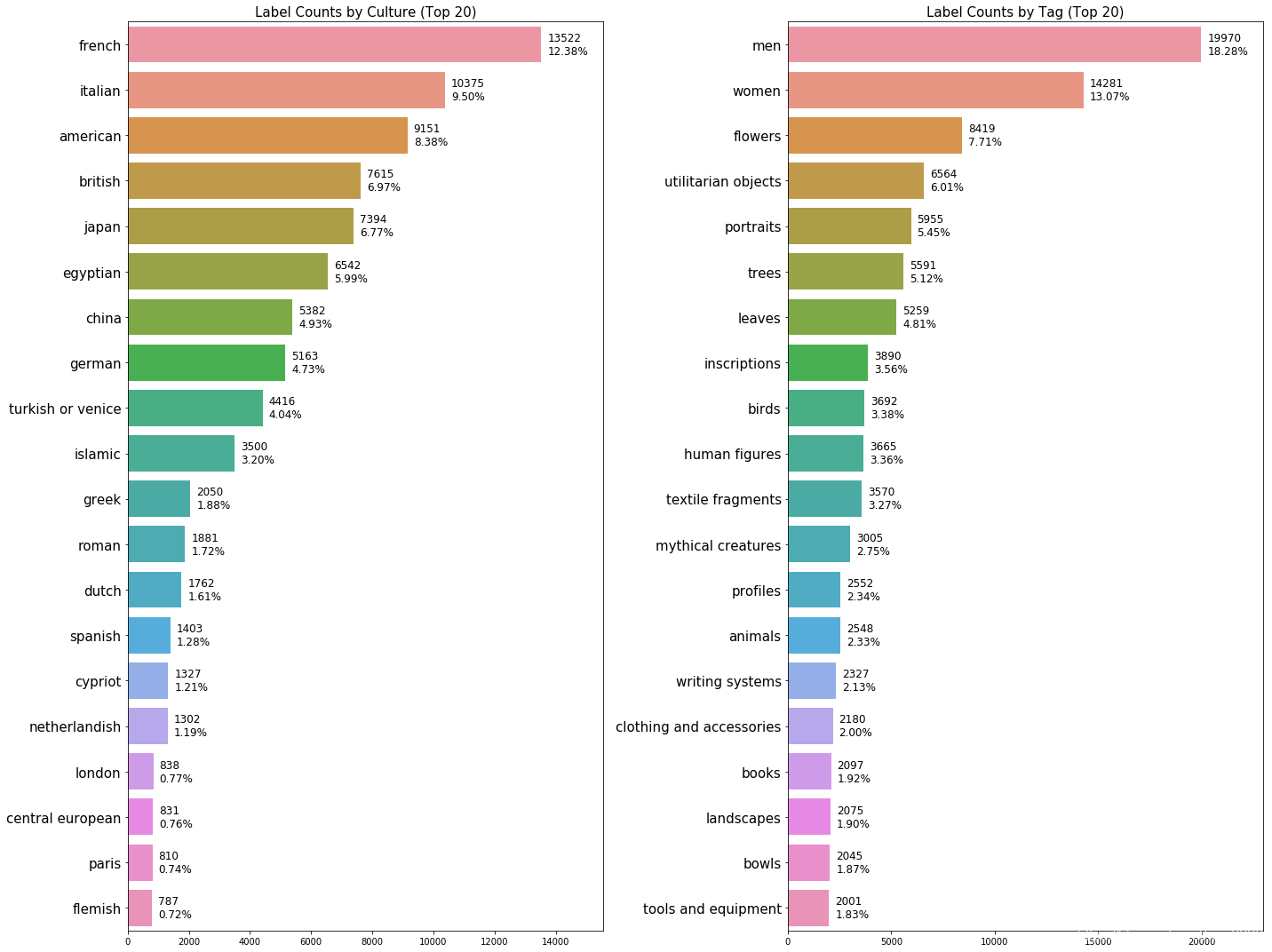
1). 类别总数:1103类,其中culture有398类,tag有705类;下图代表了两类中出现频次较高的标签。

2). 每张图像中所含类别个数:1~11。大多数图像含有2到5个标签,但是有一张图像含有11个标签。。。如下图所示:
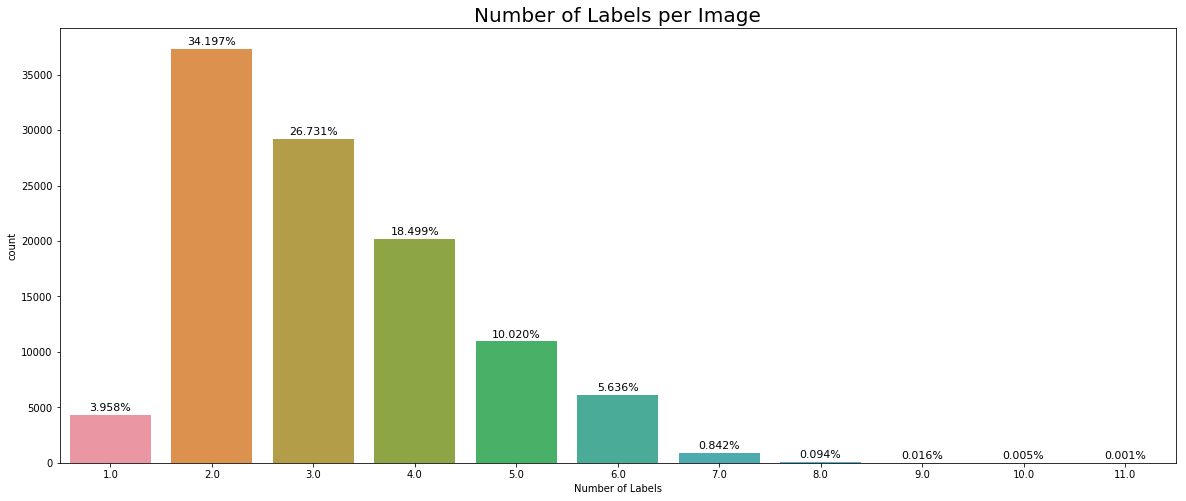
11个标签的奇葩图像:


3). 出现频率较高的一些标签:由下图可以看到,前20th的label中culture和tag分别占了整个数据集的0.72%和1.83%。这就说明大多数label是所出现的次数都是非常少的;
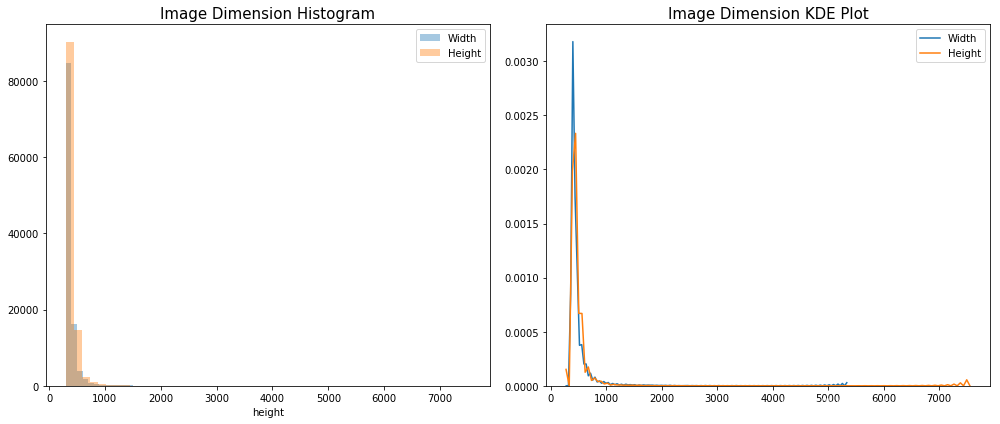
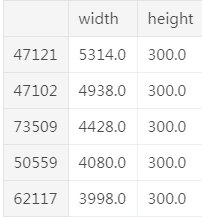
4). 图像尺寸:数据集中图像尺寸分布特别不均衡,由KDE plot可知,width中最大的到5000,height最大的到7000;
下面列一些具体的数据:
下面看一下这些图像长什么样子:

 总结:由以上几点可知,该数据集由于在图像尺寸,图像所含的标签个数以及每种标签所出现的次数差距均较大,因此该数据集也是极度不均衡的,而且由于共有1103类,从而进一步增大了分类的难度。
总结:由以上几点可知,该数据集由于在图像尺寸,图像所含的标签个数以及每种标签所出现的次数差距均较大,因此该数据集也是极度不均衡的,而且由于共有1103类,从而进一步增大了分类的难度。
二. 数据预处理以及数据增强
由第一部分可知,该比赛数据集严重不均衡,所以我们做了一下几方面尝试,以及验证了该方案是否对结果有提升。
- resize_padding_resize: 我们设置了一个阈值aspect_ratio,用来处理那些尺寸极度不均衡的图像。具体的做法是:先判断图像的宽高比,如果大于阈值,则先把短边resize成原来的2倍,然后在把resize后的短边padding到长边的大小,最后在把padding后的图像resize成300*300。具体效果如下:

可以看出,如果直接对原图resize 成300*300,那么出来的图像就会损失太多信息,而且由人看的话,也会把之前的毛笔误认做梳子,所以从理论上来说,这一步应该对结果有提升,但是LB却没有提升,到现在也不知道为啥。。。 - MultScaleCrop:为了增加图像的多尺度性,采用不同的scale因子(1, 0.875, 0.75, 0.66),在原图上随机crop,然后将crop后的图像resize成300*300 。效果:LB与直接在原图上RandomCrop差不多,所以后面训练模型是对训练集的处理采用的是RandomCrop。
- 对测试集进行FiveCrop:在想出这个方案之前,一直用的是CenterCrop对测试集进行预处理,然后在TTA;后面仔细分析了一下,如果该任务是multi-label,如果有的label在图像的边缘,进行CenterCrop的话就有可能会丢失该label的信息,因此,我们做了FiveCrop,如下图所示:
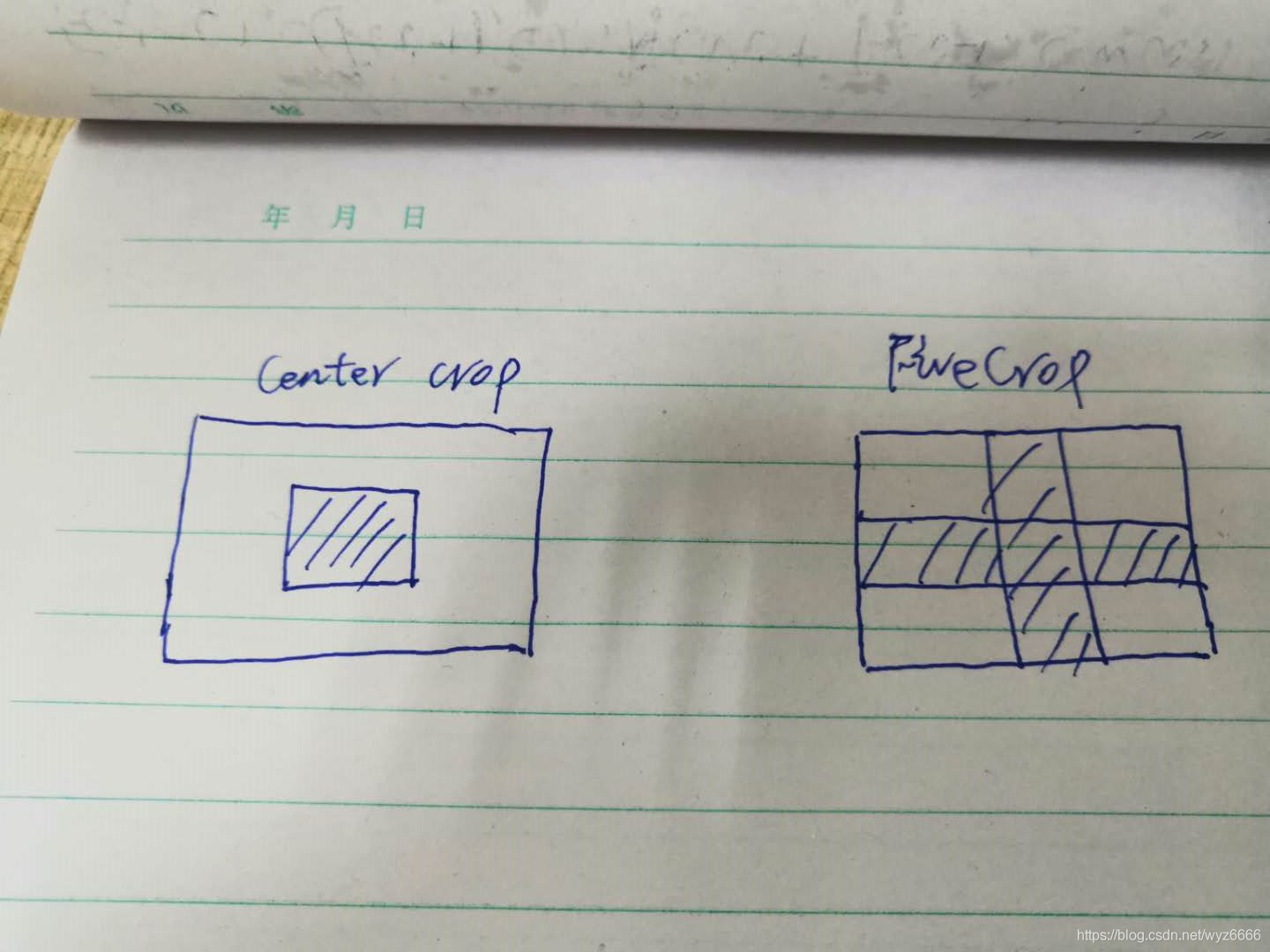
效果:比CenterCrop的LB提升了0.005左右。 - data augment:
训练集:包含了RandomErasing和mix up的增强手段,具体代码如下:
image_transform = Compose([
RandomCrop(dsize),
RandomHorizontalFlip(),
ToTensor(),
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
RandomErasing(probability=0, sh=0.4, r1=0.3)
])
RandomErasing:
class RandomErasing(object):
'''
Class that performs Random Erasing in Random Erasing Data Augmentation by Zhong et al.
-------------------------------------------------------------------------------------
probability: The probability that the operation will be performed.
sl: min erasing area
sh: max erasing area
r1: min aspect ratio
mean: erasing value
usage (only for train data): transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
transforms.RandomErasing(probability = args.p (0), sh = args.sh (0.4), r1 = args.r1 (0.3), ),
])
-------------------------------------------------------------------------------------
'''
def __init__(self, probability=0.5, sl=0.02, sh=0.4, r1=0.3, mean=None):
if mean is None:
mean = [0.485, 0.456, 0.406]
self.probability = probability
self.mean = mean
self.sl = sl
self.sh = sh
self.r1 = r1
def __call__(self, img):
if random.uniform(0, 1) > self.probability:
return img
for attempt in range(100):
area = img.size()[1] * img.size()[2]
target_area = random.uniform(self.sl, self.sh) * area
aspect_ratio = random.uniform(self.r1, 1 / self.r1)
h = int(round(math.sqrt(target_area * aspect_ratio)))
w = int(round(math.sqrt(target_area / aspect_ratio)))
if w < img.size()[2] and h < img.size()[1]:
x1 = random.randint(0, img.size()[1] - h)
y1 = random.randint(0, img.size()[2] - w)
if img.size()[0] == 3:
img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]
img[1, x1:x1 + h, y1:y1 + w] = self.mean[1]
img[2, x1:x1 + h, y1:y1 + w] = self.mean[2]
else:
img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]
return img
return img
mix up:
l = np.random.beta(mixup_alpha, mixup_alpha)
index = torch.randperm(inputs.size(0))
inputs_a, inputs_b = inputs, inputs[index]
targets_a, targets_b = targets, targets[index]
mixed_images = l * inputs_a + (1 - l) * inputs_b
outputs = self.model(mixed_images)
loss = reduce_loss(l * criterion(outputs, targets_a) + (1 - l) * criterion(outputs, targets_b))
测试集:5倍的TTA:采用FiveCrop的预处理手段。
def load_transform_image(item, root, dsize, aspect_ratio, tta_index):
image = load_image(item, root, aspect_ratio)
w, h = image.size
if tta_index==0:
image = F.center_crop(image, dsize)
elif tta_index==1:
i = 0
j = w//2 - dsize//2
image = F.crop(image, i, j, dsize, dsize)
elif tta_index==2:
i = h - dsize
j = w//2 - dsize//2
image = F.crop(image, i, j, dsize, dsize)
elif tta_index==3:
i = h//2 - dsize//2
j = 0
image = F.crop(image, i, j, dsize, dsize)
elif tta_index==4:
i = h//2 - dsize//2
j = w - dsize
image = F.crop(image, i, j, dsize, dsize)
image_transform = Compose([
RandomHorizontalFlip(),
ToTensor(),
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = image_transform(image)
return image
- 列出获奖队的data augment方法:
top1:采用CropIfNedeed + Resize预处理,并对处理后的图像进一步增强。
RandomCropIfNeeded(SIZE * 2, SIZE * 2),
Resize(SIZE, SIZE)
HorizontalFlip(p=0.5),
OneOf([
RandomBrightness(0.1, p=1),
RandomContrast(0.1, p=1),
], p=0.3),
ShiftScaleRotate(shift_limit=0.1, scale_limit=0.0, rotate_limit=15, p=0.3),
IAAAdditiveGaussianNoise(p=0.3),
class RandomCropIfNeeded(RandomCrop):
def __init__(self, height, width, always_apply=False, p=1.0):
super(RandomCrop, self).__init__(always_apply, p)
self.height = height
self.width = width
def apply(self, img, h_start=0, w_start=0, **params):
h, w, _ = img.shape
return F.random_crop(img, min(self.height, h), min(self.width, w), h_start, w_start)
top9:采用了RandomResizedCropV2的预处理。note: 与torchvision提供的RandomResizedCrop接口稍微有点区别,官方的采用的CenterCrop+Resize实现,而作者采用的是RandomCrop+Resize。代码如下:
class RandomResizedCropV2(T.RandomResizedCrop):
@staticmethod
def get_params(img, scale, ratio):
# ...
# fallback
w = min(img.size[0], img.size[1])
i = random.randint(0, img.size[1] - w)
j = random.randint(0, img.size[0] - w)
return i, j, w, w
def train_transform(size):
return T.Compose([
RandomResizedCropV2(size, scale=(0.7, 1.0), ratio=(4/5, 5/4)),
T.RandomHorizontalFlip(),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
RandomErasing(probability=0.3, sh=0.3),
])
def test_transform(size):
return T.Compose([
RandomResizedCropV2(size, scale=(0.7, 1.0), ratio=(4/5, 5/4)),
T.RandomHorizontalFlip(),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
三. 模型选择及设计
首先将训练集分成6折,然后使用第一折的数据进行单模型的训练和验证,从而确定不同种类模型的性能。由于kernel-only的规则,kaggle官方kernel运行时间不能超过九小时,所以就选择的是复杂度适中的模型。但有人实验证明,网络越深,其效果越好。
-
backbone
resnet50, cbam_resnet50,seresnext50,airnext50, resnet101, densenet121,inceptionv3
对这些模型做过测试后,基于运行时间和网络性能选择了最终的三个backbone分别是带有attention机制的 cbam_resnet50,seresnext50,airnext50。 -
backbone的改进-引入multiScale机制
受SSD的启发,我们引入了multiScale机制,即将网络中间层的feature map经过global average pooling后concat到最后的全连接层,这样做能使得feature map得到更好的复用。这一操作使得cv和LB均提高了0.005左右。 -
label correlation-引入图卷积网络GCN
由于该比赛是一个multi-label classification,所以不同类别之间具有一定的相关性,具体的来说,有的类别一旦出现,另一个类别有很大概率也会出现。所以为了让网络能学到这种相关性,我们参考了ML-GCN,然后设计了基于该任务的GCN网络。但是得到的效果却没有提升。我们分析了原因可能是类别基数太大(1103类),而ML-GCN所采用的数据集coco和voc分别是80类和20类,这样生成的adjacent matrix太过于稀疏,我们分别统计了一下三种数据集adjacent matrix的稀疏程度,计算方式是用矩阵中非零值的元素个数(阈值τ设置的0.2)除以矩阵的大小。结果如下:
voc:21 / (20x20) = 5.25%
coco: 311 / (80x80) = 4.86%
imet: 649 / (1103x1103) = 0.05%
因此GCN网络对这种太过于稀疏的adjacent matrix,并不能学到类别间的相关性。 -
Culture and tags separately
由于所有的类别都基于这两大类,所以一个最直观的想法是在用CNN提取完特征后,设立两路的fc层,一路用来识别culture的398类,另一路用来识别tag的705类。然后就能得到两种loss:culture loss和tag loss,将这两种loss加权后就能得到最终的loss。但是效果与单路fc层效果差不多,这也是我没太理解的地方。
四. 训练
由第三部分可知,我们一共选择了三个模型:cbam_resnet50,airnext50和seresnext50进行fine tuning,引入了multiScale机制,并进行6折的交叉验证。在三个模型中,
相同的训练策略有:
- crop的image size:288(试过320的没效果)
- loss function:bce loss(试过focal loss与bce loss性能相当)
- optimizer:Adam
- init_lr:0.0001
- 学习率衰减策略:当验证集的f2 score连续4次都不在提高时,就把学习率衰减为原来的0.2
- fine tuning机制:第一个epoch只训练fc层,之后在将前面的卷积层unfreeze
- 框架:pytorch
不同的训练的策略有:
- batch size: cbam_resnet50(48),airnext50(36),seresnext50(42)
其它的训练策略:
- 采用multi image size的训练技巧,即将image size设置了三种大小:160,228,288。训练细节可以参考我之前的这篇博客,但是效果与直接训练288一样。
- adjust the threshold for each image:有这种想法但是没有实现,能力有限,这里我贴出top6的解决方法。
五. 测试
- 训练完全部的单模型
每种模型训练了6折,一共有3种模型,因此总共有18个模型 - ensemble机制
先分别将每种模型的6折结果进行融合(即对结果取平均),这样就有三种融合后的结果,然后再将这三种结果进行融合(即对结果取平均)便得到了最终的结果。
六. 心得
- 选择合适的baseline模型!!! 一个好的baseline可以进入前top20%;
- 多了解一些训练技巧。可以参考我之前的博客。
- 多了解一些简单实用的package。可以参考我之前的博客。
- 善用模型融合!!!
- 相信自己本地的CV验证集。每天在kaggle的提交次数是有限的,因此要设置好离线验证集,不断探索好的参数,不要过分相信kaggle的线上得分。
- 了解了multi-task任务与multi-label的区别,可参考这里。
七. 其它队好的方案
top1:link。
top4:link。
top6:link。
top9:link。
another a good solution:link。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









