







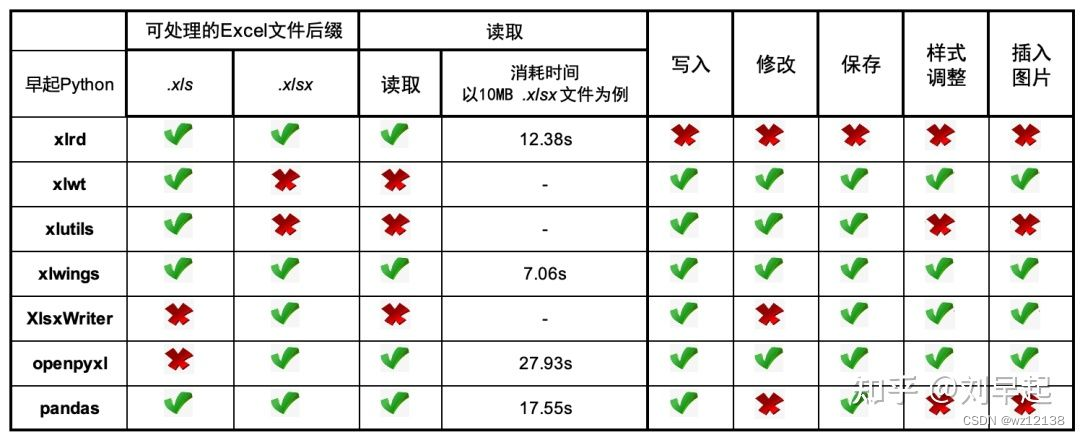
首先借引用一张图直观感受一下(有同学反应如果最新版本得xlrd库可能是不支持读取xlsx文件的,另外xlwt可以写入xlsx文件)这里采用的版本如下

openyxl:可以对xlsx、xlsm文件进行读、写操作,主要对Excel2007年之后的版本(.xlsx),不能读取xls
xlrd:可以对xlsx、xls、xlsm文件进行读操作且效率高
xlwt:主要对xls文件进行写操作且效率高,但是可能存在兼容性问题
1.文件的读取
# xlrd读取
def read_excel():
"""
:return:
"""
# 加载excel文件,获取文件对象
xlrd_workbook = xlrd.open_workbook('test.xlsx')
# 获取所有的sheet名
print(xlrd_workbook.sheet_names())
# 获取sheet对象,返回列表形式,对表格文件操作都是通过sheet对象进行
print(xlrd_workbook.sheets())
xlrd_sheet = xlrd_workbook.sheets()[0]
# 读取当前表格行数,列数
num_rows = xlrd_sheet.nrows
num_cols = xlrd_sheet.ncols
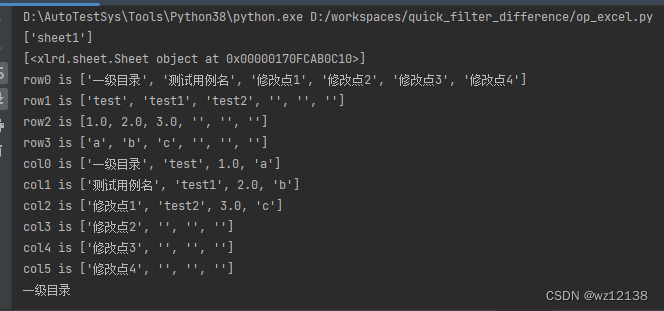
# 遍历sheet1中所有行,列;xlrd读取文件时默认索引从0开始;注意表格是数值类型读取出来是浮点数,
for curr_row in range(num_rows):
row = xlrd_sheet.row_values(curr_row)
print('row{} is {}'.format(curr_row, row))
for curr_col in range(num_cols):
col = xlrd_sheet.col_values(curr_col)
print('col{} is {}'.format(curr_col, col))
# 按索引获取单元格值
cell = xlrd_sheet.cell(0,0).value
print(cell)
# openxyl读取
wb_openxyl = openpyxl.load_workbook('test.xlsx')
# 获取表格对象
sheet_ob = wb_openxyl.worksheets[0]
# 获取表格行和列数
rows_num = sheet_ob.max_row
cols_num = sheet_ob.max_column
print(rows_num)
print(cols_num)
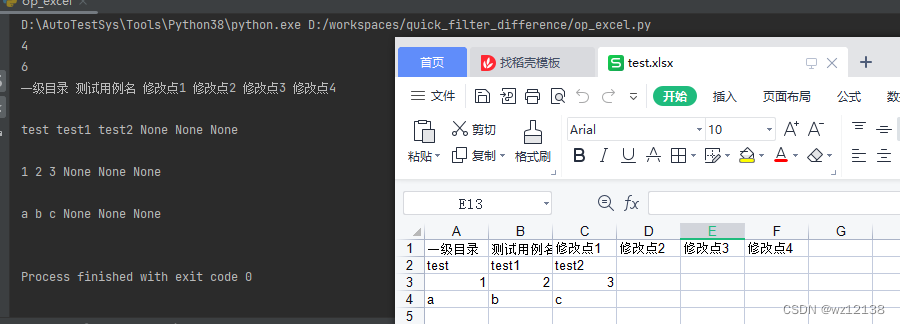
# 按行遍历表格文件;不同于xlrd读取,在openxyl中索引计数从1开始
for i in range(1, rows_num+1):
for j in range(1, cols_num+1):
print(sheet_ob.cell(i,j).value,end=' ')
print('\n')在这里插入代码片
2.文件的写入
openxyl可以直接加载已存在的文件进行操作,而xlwt只能新建文件,因此在通过xlwt写文件时想直接使用已存在的表格数据,可以借助xlutils库复制文件对象进行操作,完成后保存文件
# xlwt写操作
def write_excel():
# 新建表格文件
xlwt_workbook = xlwt.Workbook()
sheet1 = xlwt_workbook.add_sheet('sheet1', cell_overwrite_ok=True)
headings = ['一级目录', '测试用例名', '修改点1', '修改点2', '修改点3', '修改点4', '修改点5']
# 般第一行写我们的目录标签等,索引从0开始
for i in range(len(headings)):
sheet1.write(0, i, headings[i])
row = 1
# 此处数据是列表中嵌套列表方便读取,按行写入(也可按列写入,具体看自己需要)
all_info = [['test', 'test1', 'test2'], [1, 2, 3], ['a', 'b', 'c']]
# 依次写入每一行的每一列数据
for colnum_info in all_info:
for i in range(len(colnum_info)):
sheet1.write(row, i, colnum_info[i])
row += 1
xlwt_workbook.save('test.xls')
time.sleep(5)
# 对现有文件操作,通过xlrd读取表格文件后xlutils复制操作对象,和上面用法按需要来
rd = xlrd.open_workbook(r'E:\Temp\R222.xlsx')
wt = xlutils.copy.copy(rd)
sheets = wt.get_sheet(0)
count = 1
for colnum_info in all_info:
for i in range(len(colnum_info)):
sheets.write(row, i, colnum_info[i])
count += 1
wt.save(r'E:\Temp\new_R222.xlsx')
具体效果不运行了,xlwt的写操作效率比openxyl高很多,结合实际看需操作
# openxyl写入
workbook = openpyxl.Workbook()
workbook.create_sheet('sheet1')
worksheet = workbook.active
headings = ['一级目录', '测试用例名', '修改点1', '修改点2', '修改点3', '修改点4', '修改点5']
for i in range(len(headings)):
worksheet.cell(1, i + 1, headings[i]) # 在openxyl中索引计数从1开始,而在xlwt/xlrd中数据索引从0开始
rows = 2
for colnum_info in all_info:
for i in range(len(colnum_info)):
worksheet.cell(rows, i + 1, colnum_info[i])
rows += 1
workbook.save('change_info.xlsx')
# 或对已存在文件操作
"""
wb = openpyxl.load_workbook(r'E:\Temp\R222.xlsx')
sheet1 = wb.worksheets[0]
rows = 2
for colnum_info in all_info:
for i in range(len(colnum_info)):
sheet1.cell(rows, i + 1, colnum_info[i])
rows += 1
wb.save(r'E:\Temp\R222.xlsx')
"""















 4160
4160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









