






因工作需要对近几年的英伟达显卡做算力统计,特此记录。所有数据来源来自英伟达针对不同显卡发布的白皮书。
| 显卡架构 | 提出年份 | 性能 | 代表显卡型号 | 功耗 | 备注 |
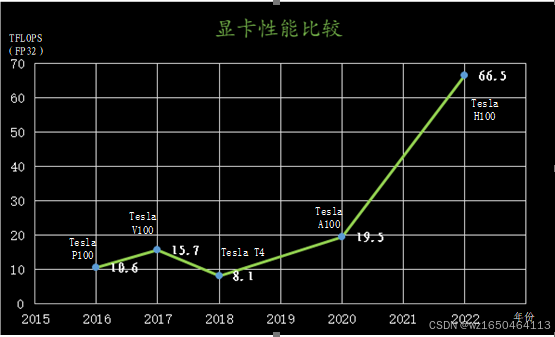
| Pascal | 2016 | 5.3 FP64 10.6FP32 | Tesla P100 | 300W | PCIE版本功耗为250w,性能不变 |
| Volta | 2017 | 7.8 FP64 15.7FP32 | Tesla V100 | 300W | PCIE版本功耗为250w,性能不变 |
| Turning | 2018 | NA FP64 8.1FP32 | Tesla T4 | 75W | 本身已经是PCIE 版本,不支持FP64计算 |
| Ampere | 2020 | 9.7 FP64 19.5FP32 | Tesla A100 | 400W | PCIE版本功耗为300w,性能不变 |
| Hopper | 2022 | 33.5 FP64 66.5FP32 | Tesla H100 | 700W | PCIE版本功耗减半,性能略微降低 |
| Blackwall | 2024 | 未发行 | NA | NA |
4090显卡分析
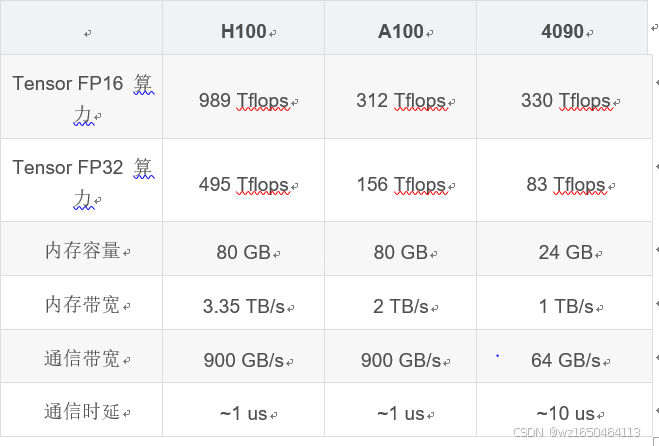
结论:大模型的训练用 4090 是不行的,但推理(inference/serving)用 4090 不仅可行,在性价比上还能比 H100 稍高。4090 如果极致优化,性价比甚至可以达到 H100 的 2 倍。
事实上,H100/A100 和 4090 最大的区别就在通信和内存上,算力差距不大。
4090 单卡训练的性价比这么高,不能用来做大模型训练。从技术上讲,根本原因是大模型训练需要高性能的通信,但 4090 的通信效率太低。
就目前已知的情况来看,GeForce RTX 4090D(国区特供阉割版)和GeForce RTX 4090主要有以下几个方面的区别。
一、CUDA内核和张量内核数量缩水了12.3%;’二、显存方面(包括容量和带宽等)没有缩水;三、无法超频;四、标准运行频率略有区别;五、功耗略有所降低,降低了25W。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









