










Architecture: ~ [ ia64 ] ~ [ i386 ] ~ [ arm ] ~ [ ppc ] ~ [ sparc64 ] ~
/*
This file is taken from Linux 2.0.36 kernel source.
Modified in Jun 99 by Nergal.
*/
#include <sys/types.h>
#include <sys/time.h>
#include <netinet/in.h>
#include <netinet/in_systm.h>
#include <netinet/ip.h>
#include <netinet/tcp.h>
#include <arpa/inet.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include "checksum.h"
#include "ip_fragment.h"
#include "tcp.h"
#include "util.h"
#include "nids.h"
#define IP_CE 0x8000 /* Flag: "Congestion" */
#define IP_DF 0x4000 /* Flag: "Don't Fragment" */
#define IP_MF 0x2000 /* Flag: "More Fragments" */
#define IP_OFFSET 0x1FFF /* "Fragment Offset" part */
#define IP_FRAG_TIME (30 * 1000) /* fragment lifetime */
#define UNUSED 314159
#define FREE_READ UNUSED
#define FREE_WRITE UNUSED
#define GFP_ATOMIC UNUSED
#define NETDEBUG(x)
struct sk_buff {
char *data;
int truesize;
};
struct timer_list {
struct timer_list *prev;
struct timer_list *next;
int expires;
void (*function)();
unsigned long data;
// struct ipq *frags;
};
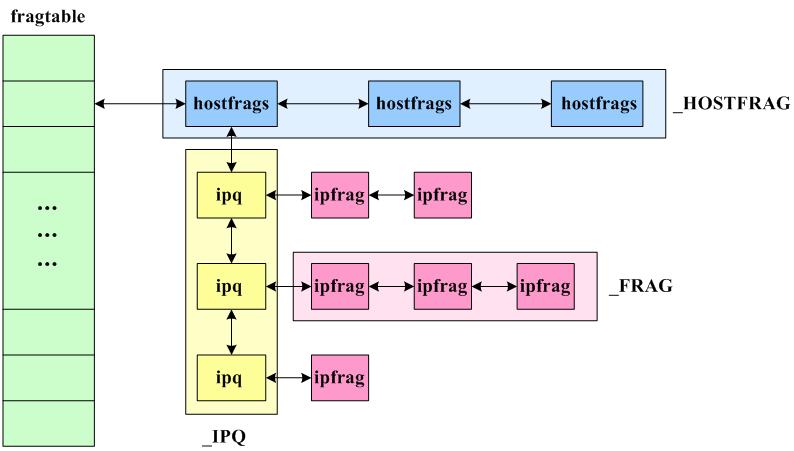
struct hostfrags {
struct ipq *ipqueue;
int ip_frag_mem;
u_int ip;
int hash_index;
struct hostfrags *prev;
struct hostfrags *next;
};
/* Describe an IP fragment. */
struct ipfrag {
int offset; /* offset of fragment in IP datagram */
int end; /* last byte of data in datagram */
int len; /* length of this fragment */
struct sk_buff *skb; /* complete received fragment */
unsigned char *ptr; /* pointer into real fragment data */
struct ipfrag *next; /* linked list pointers */
struct ipfrag *prev;
};
/* Describe an entry in the "incomplete datagrams" queue. */
struct ipq {
unsigned char *mac; /* pointer to MAC header */
struct ip *iph; /* pointer to IP header */
int len; /* total length of original datagram */
short ihlen; /* length of the IP header */
short maclen; /* length of the MAC header */
struct timer_list timer; /* when will this queue expire? */
struct ipfrag *fragments; /* linked list of received fragments */
struct hostfrags *hf;
struct ipq *next; /* linked list pointers */
struct ipq *prev;
// struct device *dev; /* Device - for icmp replies */
};
/*
Fragment cache limits. We will commit 256K at one time. Should we
cross that limit we will prune down to 192K. This should cope with
even the most extreme cases without allowing an attacker to
measurably harm machine performance.
*/
#define IPFRAG_HIGH_THRESH (256*1024)
#define IPFRAG_LOW_THRESH (192*1024)
/*
This fragment handler is a bit of a heap. On the other hand it works
quite happily and handles things quite well.
*/
static struct hostfrags **fragtable;
static struct hostfrags *this_host;
static int numpack = 0;
static int hash_size;
static int timenow;
static unsigned int time0;
static struct timer_list *timer_head = 0, *timer_tail = 0;
#define int_ntoa(x) inet_ntoa(*((struct in_addr *)&x))
static int
jiffies()
{
struct timeval tv;
if (timenow)
return timenow;
gettimeofday(&tv, 0);
timenow = (tv.tv_sec - time0) * 1000 + tv.tv_usec / 1000;
return timenow;
}
/* Memory Tracking Functions */
static void
atomic_sub(int ile, int *co)
{
*co -= ile;
}
static void
atomic_add(int ile, int *co)
{
*co += ile;
}
static void
kfree_skb(struct sk_buff * skb, int type)
{
(void)type;
free(skb);
}
static void
panic(char *str)
{
fprintf(stderr, "%s", str);
exit(1);
}
static void
add_timer(struct timer_list * x)
{
if (timer_tail) {
timer_tail->next = x;
x->prev = timer_tail;
x->next = 0;
timer_tail = x;
}
else {
x->prev = 0;
x->next = 0;
timer_tail = timer_head = x;
}
}
static void
del_timer(struct timer_list * x)
{
if (x->prev)
x->prev->next = x->next;
else
timer_head = x->next;
if (x->next)
x->next->prev = x->prev;
else
timer_tail = x->prev;
}
static void
frag_kfree_skb(struct sk_buff * skb, int type)
{
if (this_host)
atomic_sub(skb->truesize, &this_host->ip_frag_mem);
kfree_skb(skb, type);
}
static void
frag_kfree_s(void *ptr, int len)
{
if (this_host)
atomic_sub(len, &this_host->ip_frag_mem);
free(ptr);
}
static void *
frag_kmalloc(int size, int dummy)
{
void *vp = (void *) malloc(size);
(void)dummy;
if (!vp)
return NULL;
atomic_add(size, &this_host->ip_frag_mem);
return vp;
}
/* Create a new fragment entry. */
static struct ipfrag *
ip_frag_create(int offset, int end, struct sk_buff * skb, unsigned char *ptr)
{
struct ipfrag *fp;
fp = (struct ipfrag *) frag_kmalloc(sizeof(struct ipfrag), GFP_ATOMIC);
if (fp == NULL) {
// NETDEBUG(printk("IP: frag_create: no memory left !/n"));
nids_params.no_mem("ip_frag_create");
return (NULL);
}
memset(fp, 0, sizeof(struct ipfrag));
/* Fill in the structure. */
fp->offset = offset;
fp->end = end;
fp->len = end - offset;
fp->skb = skb;
fp->ptr = ptr;
/* Charge for the SKB as well. */
this_host->ip_frag_mem += skb->truesize;
return (fp);
}
static int
frag_index(struct ip * iph)
{
unsigned int ip = ntohl(iph->ip_dst.s_addr);
return (ip % hash_size);
}
static int
hostfrag_find(struct ip * iph)
{
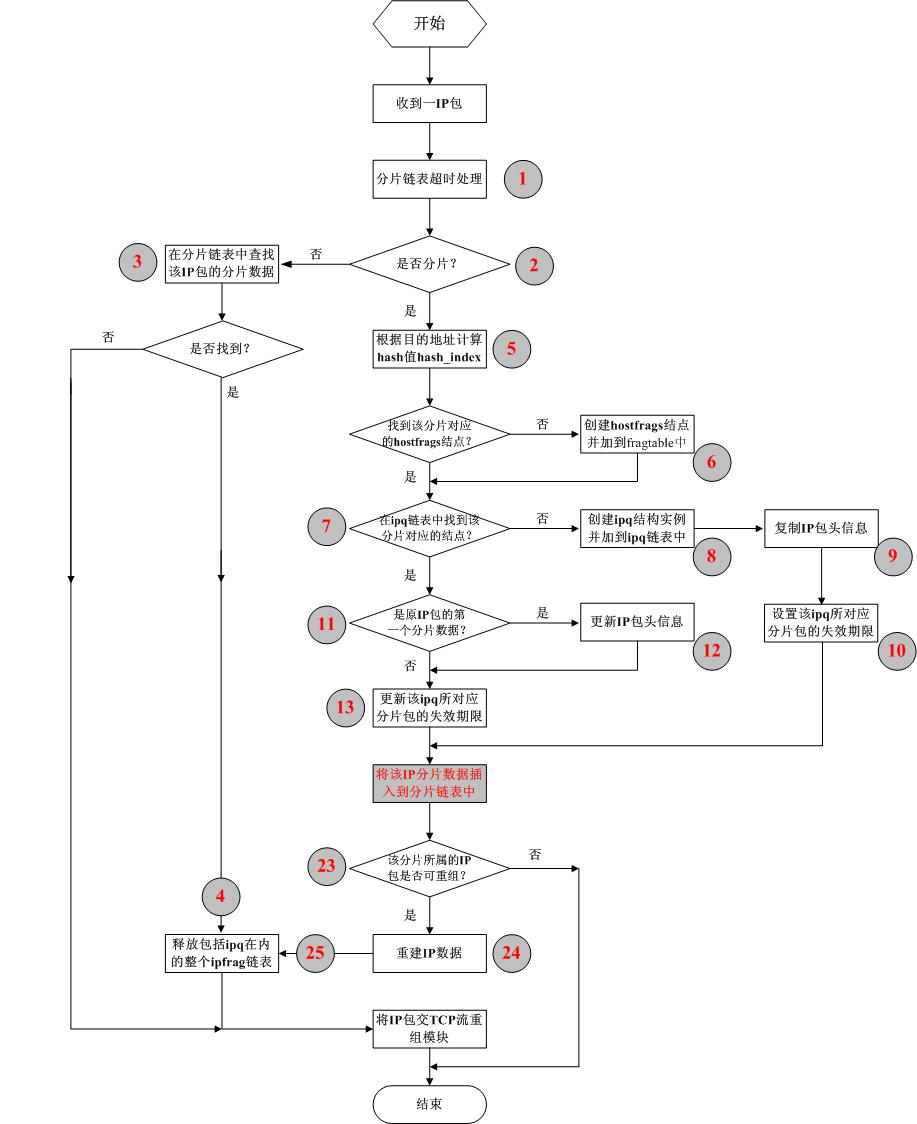
//step_5
//根据目的地址计算hash值hash_index
int hash_index = frag_index(iph);
struct hostfrags *hf;
this_host = 0;
for (hf = fragtable[hash_index]; hf; hf = hf->next)
if (hf->ip == iph->ip_dst.s_addr) {
this_host = hf;
break;
}
if (!this_host)
return 0;
else
return 1;
}
static void
hostfrag_create(struct ip * iph)
{
struct hostfrags *hf = mknew(struct hostfrags);
int hash_index = frag_index(iph);
hf->prev = 0;
hf->next = fragtable[hash_index];
if (hf->next)
hf->next->prev = hf;
fragtable[hash_index] = hf;
hf->ip = iph->ip_dst.s_addr;
hf->ipqueue = 0;
hf->ip_frag_mem = 0;
hf->hash_index = hash_index;
this_host = hf;
}
static void
rmthis_host()
{
int hash_index = this_host->hash_index;
if (this_host->prev) {
this_host->prev->next = this_host->next;
if (this_host->next)
this_host->next->prev = this_host->prev;
}
else {
fragtable[hash_index] = this_host->next;
if (this_host->next)
this_host->next->prev = 0;
}
free(this_host);
this_host = 0;
}
/*
Find the correct entry in the "incomplete datagrams" queue for this
IP datagram, and return the queue entry address if found.
*/
static struct ipq *
ip_find(struct ip * iph)
{
struct ipq *qp;
struct ipq *qplast;
qplast = NULL;
for (qp = this_host->ipqueue; qp != NULL; qplast = qp, qp = qp->next) {
if (iph->ip_id == qp->iph->ip_id &&
iph->ip_src.s_addr == qp->iph->ip_src.s_addr &&
iph->ip_dst.s_addr == qp->iph->ip_dst.s_addr &&
iph->ip_p == qp->iph->ip_p) {
del_timer(&qp->timer); /* So it doesn't vanish on us. The timer will
be reset anyway */
return (qp);
}
}
return (NULL);
}
/*
Remove an entry from the "incomplete datagrams" queue, either
because we completed, reassembled and processed it, or because it
timed out.
*/
static void
ip_free(struct ipq * qp)
{
struct ipfrag *fp;
struct ipfrag *xp;
/* Stop the timer for this entry. */
del_timer(&qp->timer);
/* Remove this entry from the "incomplete datagrams" queue. */
if (qp->prev == NULL) {
this_host->ipqueue = qp->next;
if (this_host->ipqueue != NULL)
this_host->ipqueue->prev = NULL;
else
rmthis_host();
}
else {
qp->prev->next = qp->next;
if (qp->next != NULL)
qp->next->prev = qp->prev;
}
/* Release all fragment data. */
fp = qp->fragments;
while (fp != NULL) {
xp = fp->next;
frag_kfree_skb(fp->skb, FREE_READ);
frag_kfree_s(fp, sizeof(struct ipfrag));
fp = xp;
}
/* Release the IP header. */
frag_kfree_s(qp->iph, 64 + 8);
/* Finally, release the queue descriptor itself. */
frag_kfree_s(qp, sizeof(struct ipq));
}
/* Oops- a fragment queue timed out. Kill it and send an ICMP reply. */
static void
ip_expire(unsigned long arg)
{
struct ipq *qp;
qp = (struct ipq *) arg;
/* Nuke the fragment queue. */
ip_free(qp);
}
/*
Memory limiting on fragments. Evictor trashes the oldest fragment
queue until we are back under the low threshold.
*/
static void
ip_evictor(void)
{
// fprintf(stderr, "ip_evict:numpack=%i/n", numpack);
while (this_host->ip_frag_mem > IPFRAG_LOW_THRESH) {
if (!this_host->ipqueue)
panic("ip_evictor: memcount");
ip_free(this_host->ipqueue);
}
}
/*
Add an entry to the 'ipq' queue for a newly received IP datagram.
We will (hopefully :-) receive all other fragments of this datagram
in time, so we just create a queue for this datagram, in which we
will insert the received fragments at their respective positions.
*/
/*
新建一个ipq结构的实例作为由ipfrag结构组成的双向
链表的头结点,创建成功后首先修改this_host所指向
的ip_frag_mem为ipq结构的大小(其初始值在创建hostfrags
结构时设置为0),设置其成员变量如下:
分配72(64字节的IP包头――IP包头最长为15*4=60字节,
这里分配了64字节――和8字节的ICMP首部数据)字节
内存作为ip包头并使ipq.iph指向其首地址,并将分片数
据中的IP头加8字节数据(可能是ICMP首部数据)复制
到ipq.iph中,
更新this_host-> ip_frag_mem(即this_host-> ip_frag_mem += 72)
使其始终表示现已分配给当前分片包的字节数;
ipq.ihlen设置为实际的IP包头长;
ipq.len和ipq.fragments设置为0;
ipq.hf设置为this_host,即该分片包所属的主机信息;
设置该ipq所对应的IP分片包的失效期限ipq.timer. expires
为当前时间加IP_FRAG_TIME(大约为30秒);
设置ipq.timer.data为该ipq的地址(在系统收到一个IP分片包后
的30秒再没有收到任何和它属于同一IP包的分片数据时,
系统会丢弃那些属于同一个IP包但未完成的IP分片重组
的数据,系统会根据ipq.timer.data来释放资源);
ipq.timer.function指向该ipq失效时的处理函数,该函数用来释放资源;
ipq.timer设置完后将它加入到系统内的时间链表中;
设置ipq.prev和ipq.next为0。
*/
static struct ipq *
ip_create(struct ip * iph)
{
struct ipq *qp;
int ihlen;
qp = (struct ipq *) frag_kmalloc(sizeof(struct ipq), GFP_ATOMIC);
if (qp == NULL) {
// NETDEBUG(printk("IP: create: no memory left !/n"));
nids_params.no_mem("ip_create");
return (NULL);
}
memset(qp, 0, sizeof(struct ipq));
/* Allocate memory for the IP header (plus 8 octets for ICMP). */
ihlen = iph->ip_hl * 4;
qp->iph = (struct ip *) frag_kmalloc(64 + 8, GFP_ATOMIC);
if (qp->iph == NULL) {
//NETDEBUG(printk("IP: create: no memory left !/n"));
nids_params.no_mem("ip_create");
frag_kfree_s(qp, sizeof(struct ipq));
return (NULL);
}
//step_9
//复制IP包头信息
memcpy(qp->iph, iph, ihlen + 8);
qp->len = 0;
qp->ihlen = ihlen;
qp->fragments = NULL;
qp->hf = this_host;
//step_10
//设置该ipq所对应分片包的失效期限
/* Start a timer for this entry. */
qp->timer.expires = jiffies() + IP_FRAG_TIME; /* about 30 seconds */
qp->timer.data = (unsigned long) qp; /* pointer to queue */
qp->timer.function = ip_expire; /* expire function */
add_timer(&qp->timer);
/*
此时,新建的ipq实例已经设置完闭,将ipq加入到this_host
所指向的ipqueue双向链表中(因为this_host也是新建立的,
所以这时该链表中仅有一个ipq链表)。
*/
/* Add this entry to the queue. */
qp->prev = NULL;
qp->next = this_host->ipqueue;
if (qp->next != NULL)
qp->next->prev = qp;
this_host->ipqueue = qp;
return (qp);
}
/* See if a fragment queue is complete. */
static int
ip_done(struct ipq * qp)
{
struct ipfrag *fp;
int offset;
//zeq_final_frag
/* Only possible if we received the final fragment. */
if (qp->len == 0)
return (0);
/* Check all fragment offsets to see if they connect. */
fp = qp->fragments;
offset = 0;
while (fp != NULL) {
if (fp->offset > offset)
return (0); /* fragment(s) missing */
offset = fp->end;
fp = fp->next;
}
/* All fragments are present. */
return (1);
}
/*
Build a new IP datagram from all its fragments.
FIXME: We copy here because we lack an effective way of handling
lists of bits on input. Until the new skb data handling is in I'm
not going to touch this with a bargepole.
*/
static char *
ip_glue(struct ipq * qp)
{
char *skb;
struct ip *iph;
struct ipfrag *fp;
unsigned char *ptr;
int count, len;
/* Allocate a new buffer for the datagram. */
len = qp->ihlen + qp->len;
if (len > 65535) {
// NETDEBUG(printk("Oversized IP packet from %s./n", int_ntoa(qp->iph->ip_src.s_addr)));
nids_params.syslog(NIDS_WARN_IP, NIDS_WARN_IP_OVERSIZED, qp->iph, 0);
ip_free(qp);
return NULL;
}
//zeq_skb_1
//重组的ip 包在这里分配内存
//step_24
//重建IP数据,分配内存
if ((skb = (char *) malloc(len)) == NULL) {
// NETDEBUG(printk("IP: queue_glue: no memory for gluing queue %p/n", qp));
nids_params.no_mem("ip_glue");
ip_free(qp);
return (NULL);
}
/* Fill in the basic details. */
ptr = skb;
memcpy(ptr, ((unsigned char *) qp->iph), qp->ihlen);
ptr += qp->ihlen;
count = 0;
/* Copy the data portions of all fragments into the new buffer. */
fp = qp->fragments;
while (fp != NULL) {
if (fp->len < 0 || fp->offset + qp->ihlen + fp->len > len) {
//NETDEBUG(printk("Invalid fragment list: Fragment over size./n"));
nids_params.syslog(NIDS_WARN_IP, NIDS_WARN_IP_INVLIST, qp->iph, 0);
ip_free(qp);
//kfree_skb(skb, FREE_WRITE);
//ip_statistics.IpReasmFails++;
free(skb);
return NULL;
}
memcpy((ptr + fp->offset), fp->ptr, fp->len);
count += fp->len;
fp = fp->next;
}
/* We glued together all fragments, so remove the queue entry. */
//step_25
//释放包括ipq在内的整个ipfrag链表
ip_free(qp);
/* Done with all fragments. Fixup the new IP header. */
iph = (struct ip *) skb;
iph->ip_off = 0;
iph->ip_len = htons((iph->ip_hl * 4) + count);
// skb->ip_hdr = iph;
//zeq_skb_2
//将重组的ip 包首地址传递给调用函数ip_defrag
return (skb);
}
/* Process an incoming IP datagram fragment. */
static char *
ip_defrag(struct ip *iph, struct sk_buff *skb)
{
struct ipfrag *prev, *next, *tmp;
struct ipfrag *tfp;
struct ipq *qp;
char *skb2;
unsigned char *ptr;
int flags, offset;
int i, ihl, end;
/*
当收到的IP包为分片数据,即标志字段中的MF为1,
首先根据其目的地址计算其hash值hash_index,然后在
fragtable[hash_index] 所指向的hostfrags双向链表中查找该分
片包对应的hostfrags结点
*/
if (!hostfrag_find(iph) && skb)
/*
如果fragtable[hash_index]为空或者没有找到对应的
hostfrags结点,则创建一个新hostfrags结点,之后
将其加入到fragtable[hash_index] 所指向的双向链表
中,并使fragtable[hash_index] 指向刚创建的hostfrags结
点,并设置其成员如下:hostfrags.ip为该分片数
据的目的地址;hostfrags.hash_index为根据目的地
址计算所得的hash值;其余变量设置为0。为
了以后访问该结点方便,设置全局变量this_host
也指向这个新结点。此时该结点对应的ipq链表为空
*/
//step_6
//创建hostfrags结点并加到fragtable中
hostfrag_create(iph);
/* Start by cleaning up the memory. */
if (this_host)
if (this_host->ip_frag_mem > IPFRAG_HIGH_THRESH)
ip_evictor();
/* Find the entry of this IP datagram in the "incomplete datagrams" queue. */
if (this_host)
/*
如果fragtable[hash_index]不为空且在fragtable[hash_index] 所指
向的hostfrags双向链表中找到了该分片包对应的hostfrags结点
(此时this_host指向该结点),则在this_host所对应的ipq链表
中检查是否已经收到和当前IP分片包属于同一个IP包的
分片数据:
*/
//step_7
//在ipq链表中找该分片对应的结点
qp = ip_find(iph);
else
qp = 0;
/* Is this a non-fragmented datagram? */
offset = ntohs(iph->ip_off);
flags = offset & ~IP_OFFSET;
offset &= IP_OFFSET;
if (((flags & IP_MF) == 0) && (offset == 0)) {
//step_4
//释放包括ipq在内的整个ipfrag链表
if (qp != NULL)
ip_free(qp); /* Fragmented frame replaced by full
unfragmented copy */
return 0;
}
offset <<= 3; /* offset is in 8-byte chunks */
ihl = iph->ip_hl * 4;
/*
If the queue already existed, keep restarting its timer as long as
we still are receiving fragments. Otherwise, create a fresh queue
entry.
*/
if (qp != NULL) {
/* ANK. If the first fragment is received, we should remember the correct
IP header (with options) */
/*
接step_7
如果找到则首先判断该分片是否是原IP包的第一个分片数据
(ip_off是否为0),如果是则根据该IP包头信息重新对该ipq结
点中的ihlen和iph进行赋值,以保持其正确性。(有必要这样?
只修改ip_off不够?)之后更新该ipq对应的时间信息。
*/
//step_11
//是原IP包的第一个分片数据?
if (offset == 0) {
//step_12
//更新IP包头信息
qp->ihlen = ihl;
memcpy(qp->iph, iph, ihl + 8);
}
//step_13
//更新该ipq所对应分片包的失效期限
del_timer(&qp->timer);
qp->timer.expires = jiffies() + IP_FRAG_TIME; /* about 30 seconds */
qp->timer.data = (unsigned long) qp; /* pointer to queue */
qp->timer.function = ip_expire; /* expire function */
add_timer(&qp->timer);
}
else {
/* If we failed to create it, then discard the frame. */
/*
接step_7
如果没找到则新建一个ipq结构的实例,
设置其变量后将它加入到this_host对应的ipq链表中
(ipq.timer设置完后将其加入到系统内的时间链表中);
*/
//step_8
//创建ipq结构实例并加到ipq链表中
if ((qp = ip_create(iph)) == NULL) {
kfree_skb(skb, FREE_READ);
return NULL;
}
}
/*
至此,保存IP分片数据的ipfrag结构链表的头结点已经找
到或建立,下一步将该IP分片数据插入到分片链表中。
*/
/* Attempt to construct an oversize packet. */
if (ntohs(iph->ip_len) + (int) offset > 65535) {
// NETDEBUG(printk("Oversized packet received from %s/n", int_ntoa(iph->ip_src.s_addr)));
nids_params.syslog(NIDS_WARN_IP, NIDS_WARN_IP_OVERSIZED, iph, 0);
kfree_skb(skb, FREE_READ);
return NULL;
}
/* Determine the position of this fragment. */
end = offset + ntohs(iph->ip_len) - ihl;
/* Point into the IP datagram 'data' part. */
ptr = skb->data + ihl;
//zeq_final_frag
/* Is this the final fragment? */
if ((flags & IP_MF) == 0)
qp->len = end;
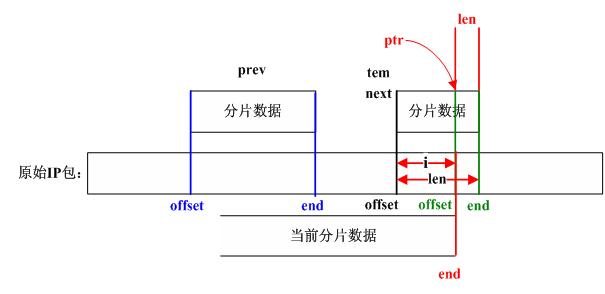
/*
Find out which fragments are in front and at the back of us in the
chain of fragments so far. We must know where to put this
fragment, right?
*/
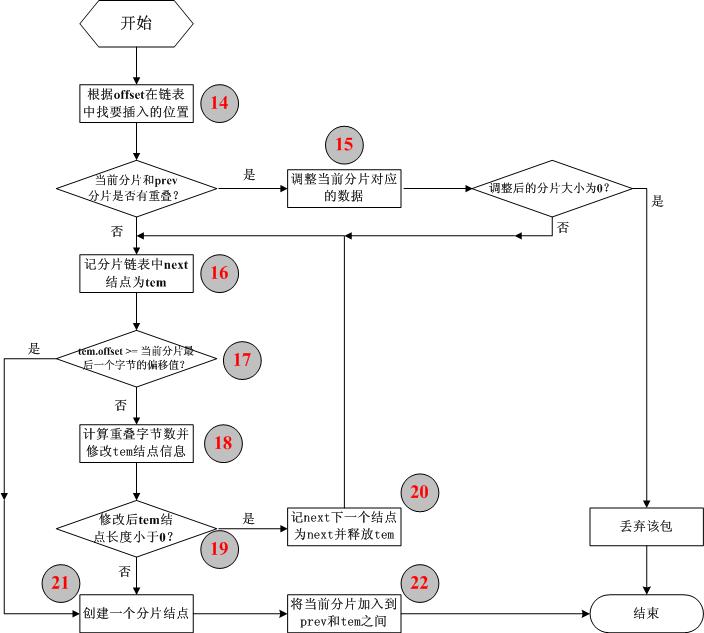
/*
ipfrag链表中结点根据offset由小到大排序,
在插入时首先找到该分片应插入的位置,
即在链表中找到这样两个相连的结点(prev和next):
prev->offset < offset 且next->offset >= offset,
其中offset为该IP分片在原IP包中的偏移(当链表中
第一个结点的offset 大于或等于当前分片包的offset
时prev指针设置为0,next指向第一个结点;当链表
所有结点的offset都小于分片包的offset时,prev指向
链表中最后一个结点,next指针为0)。
*/
//step_14
//根据offset在链表中找要插入的位置
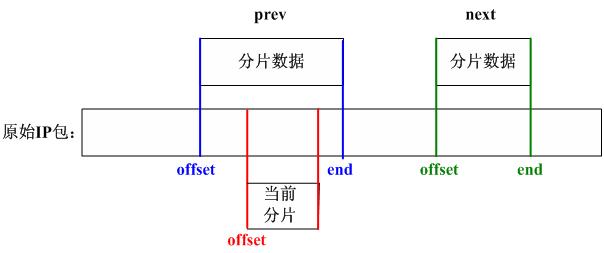
prev = NULL;
for (next = qp->fragments; next != NULL; next = next->next) {
if (next->offset >= offset)
break; /* bingo! */
prev = next;
}
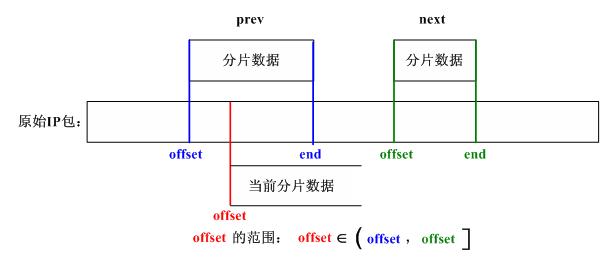
/*
We found where to put this one. Check for overlap with preceding
fragment, and, if needed, align things so that any overlaps are
eliminated.
*/
/*
先检查当前分片数据和prev所指向的分片数据是否有重叠:
*/
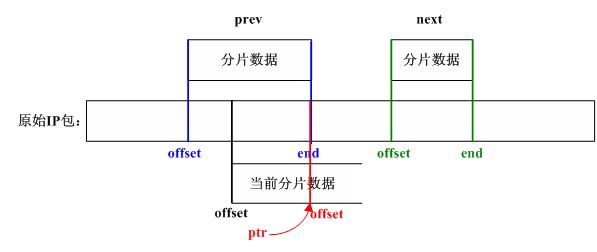
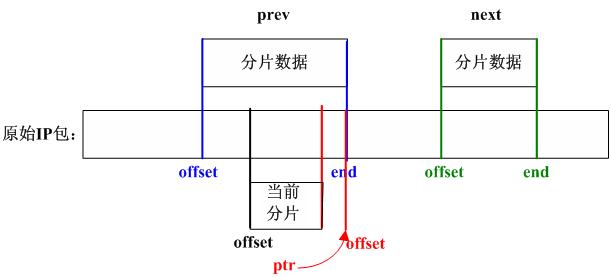
if (prev != NULL && offset < prev->end) {
//step_15
//调整当前分片对应的数据
nids_params.syslog(NIDS_WARN_IP, NIDS_WARN_IP_OVERLAP, iph, 0);
i = prev->end - offset;
offset += i; /* ptr into datagram */
ptr += i; /* ptr into fragment data */
}
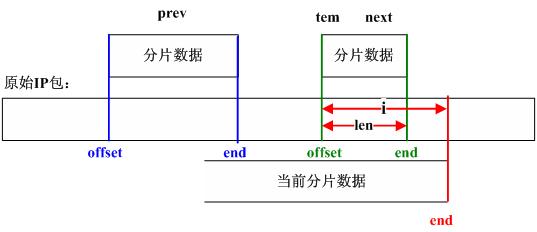
/*
Look for overlap with succeeding segments.
If we can merge fragments, do it.
*/
for (tmp = next; tmp != NULL; tmp = tfp) {
//step_16
//记分片链表中next结点为tem
tfp = tmp->next;
//step_17
//tem.offset >= 当前分片最后一个字节的偏移值?
if (tmp->offset >= end)
break; /* no overlaps at all */
nids_params.syslog(NIDS_WARN_IP, NIDS_WARN_IP_OVERLAP, iph, 0);
//step_18
//计算重叠字节数并修改tem结点信息
i = end - next->offset; /* overlap is 'i' bytes */
tmp->len -= i; /* so reduce size of */
tmp->offset += i; /* next fragment */
tmp->ptr += i;
/*
If we get a frag size of <= 0, remove it and the packet that it
goes with. We never throw the new frag away, so the frag being
dumped has always been charged for.
*/
//step_19
//修改后tem结点长度小于0?
if (tmp->len <= 0) {
//step_20
//记next下一个结点为next并释放tem
if (tmp->prev != NULL)
tmp->prev->next = tmp->next;
else
qp->fragments = tmp->next;
if (tmp->next != NULL)
tmp->next->prev = tmp->prev;
next = tfp; /* We have killed the original next frame */
frag_kfree_skb(tmp->skb, FREE_READ);
frag_kfree_s(tmp, sizeof(struct ipfrag));
}
}
/* Insert this fragment in the chain of fragments. */
//step_21
//创建一个分片结点
tfp = NULL;
tfp = ip_frag_create(offset, end, skb, ptr);
/*
No memory to save the fragment - so throw the lot. If we failed
the frag_create we haven't charged the queue.
*/
if (!tfp) {
nids_params.no_mem("ip_defrag");
kfree_skb(skb, FREE_READ);
return NULL;
}
//step_22
//将当前分片加入到prev和tem之间
/* From now on our buffer is charged to the queues. */
tfp->prev = prev;
tfp->next = next;
if (prev != NULL)
prev->next = tfp;
else
qp->fragments = tfp;
if (next != NULL)
next->prev = tfp;
/*
OK, so we inserted this new fragment into the chain. Check if we
now have a full IP datagram which we can bump up to the IP
layer...
*/
//step_23
//该分片所属的IP包是否可重组?
if (ip_done(qp)) {
skb2 = ip_glue(qp); /* glue together the fragments */
//zeq_skb_3
//继续将重建的ip 包首地址返回给调用函数ip_defrag_stub
return (skb2);
}
return (NULL);
}
int
ip_defrag_stub(struct ip *iph, struct ip **defrag)
{
int offset, flags, tot_len;
struct sk_buff *skb;
numpack++;
//step_1
//分片链表超时处理
timenow = 0;
while (timer_head && timer_head->expires < jiffies()) {
this_host = ((struct ipq *) (timer_head->data))->hf;
timer_head->function(timer_head->data);
}
offset = ntohs(iph->ip_off);
flags = offset & ~IP_OFFSET;
offset &= IP_OFFSET;
//step_2
//是否分片?
if (((flags & IP_MF) == 0) && (offset == 0)) {
/*
由于IP协议簇的复杂性(如TCP的超时重传机制),
在目的端可能会在先收到一个IP包分片数据后又
收到该IP包完整样式,即未分片的完整IP包。
因此,当系统收到一个IP包后,如果IP包没有被
分片,首先在IP分片链表中检查是否已经收到
一些该IP包的分片数据,如果有则用此完整的
数据包代替已经收到的分片数据,即释放IP分
片链表中的对应的数据,之后将该IP包交TCP数
据流重组模块。
*/
//step_3
//在分片链表中查找该IP包的分片数据
ip_defrag(iph, 0);
return IPF_NOTF;
}
tot_len = ntohs(iph->ip_len);
skb = (struct sk_buff *) malloc(tot_len + sizeof(struct sk_buff));
skb->data = (char *) (skb + 1);
memcpy(skb->data, iph, tot_len);
skb->truesize = tot_len + 16 + nids_params.dev_addon;
skb->truesize = (skb->truesize + 15) & ~15;
skb->truesize += nids_params.sk_buff_size;
//zeq_skb_4
//如果此时ip_defrag返回的指针不为0,即已经重建了ip 包
//则通过二重指针defrag 将新建IP 包的首地址传递给调用
//函数gen_ip_frag_proc
if ((*defrag = (struct ip *)ip_defrag((struct ip *) (skb->data), skb)))
return IPF_NEW;
return IPF_ISF;
}
void
ip_frag_init(int n)
{
struct timeval tv;
gettimeofday(&tv, 0);
time0 = tv.tv_sec;
fragtable = (struct hostfrags **) calloc(n, sizeof(struct hostfrags *));
if (!fragtable)
nids_params.no_mem("ip_frag_init");
hash_size = n;
}
void
ip_frag_exit(void)
{
if (fragtable) {
free(fragtable);
fragtable = NULL;
}
/* FIXME: do we need to free anything else? */
}














 9675
9675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









