







Enabling Facebook’s Log Infrastructure with Fluentd
Tweet
About
This post shows how you can replace Scribe with Fluentd.
What is Scribe?

Facebook uses Scribe as its core log aggregation service.. The description of Githubreads, “Scribe is a server for aggregating log data streamed in real time from a large number of servers.”
A network of Scribe servers forms a directed graph. Each server is a node and directed edges represent lines of communication. Usually, Scribe is installed on every node, and logs are collected to one giant “aggregator” node. The collected logs are written into HDFS (Hadoop Distributed File System) and later analyzed by Hadoop MapReduce or Hive.

Scribe is quite popular. In addition to Facebook, Twitter and Zynga use Scribe in production.
Why Fluentd?
Scribe is solid. It has been effectively deployed at several web powerhouses with serious scalability challenges. So, why would you switch to Fluentd? The answer is threefold: 1) Ease of management, 2) Flexibility, and 3) Compatibility.
1) EASE OF MANAGEMENT
Scribe is insanely difficult to install correctly. Not only do you need to build Boost, Thrift, and libhdfs from source, you must pick the correct versions of the software or the build would fail. In constrast, installing and deploying Fluentd is a breeze. It comes with rpm/deb packages maintained by Treasure Data, Inc. (That’s us!). If you use Chef (systems integration framework), you can use thecookbook we have authored, too.
2) FLEXIBILITY
Scribe is fast because it’s written in C++. But C++’s hairiness makes Scribe difficult to modify or extend. On the other hand, Fluentd is written in ~3,000 lines of Ruby, and you can easily customize and extend its behavior. In terms of performance, Scribe definitely beats Fluentd, but Fluentd is quite competent: it supports a multi-process mode and can handle upto 20,000 messages per second on a single host. If that’s not good enough, go ahead and choose Scribe. I hope you don’t get stuck in the versioning hell ;-)
3) COMPATIBILITY
Thanks to its extendable design, Fluentd already has a Scribe plug-in that supports log aggregation via Thrift. This plug-in is 100% compatible with Scribe and can replace an existing instance of Scribe out of the box.
Just to show off Fluentd’s versatility…Fluentd also has a plug-in that can output toHoop, a REST HTTP gateway with full support for HDFS operations. For the list of all the officially supported plug-ins, please check out the Fluent Github repo.
Installation
These plug-ins are assumed to be installed with Fluentd.
deb/rpm packages are by far the easiest way to install all three. Here are the relevant links:
Configuration
This section walks you through how to replace a Scribe-based system with a Fluentd-based system. Don’t worry, it really is a drop-in replacement.
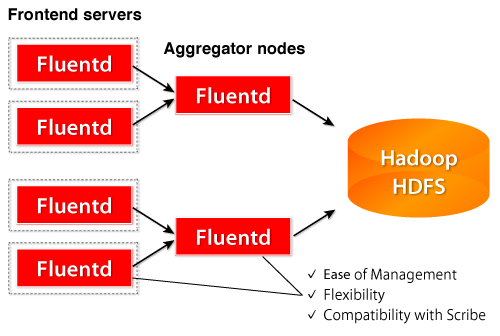
Configuring Fluentd on Front-end Nodes
For front-end nodes, The Scribe Input and Output plug-in are used (see below). If you have multiple aggregator nodes, you can use the [Copy plug-in].(http://fluentd.org/doc/plugin.html#copy)
# Scribe Input
type scribe
port 1463
add_prefix scribe
# Scribe Output
type scribe
host log-aggregator-host
port 1463
field_ref message
Configuring Fluentd on Log-Aggregator Nodes
The aggregator nodes receive the requests from the Scribe Input plug-in, and output to HDFS with the Hoop plugin. The received logs are buffered, and periodically appended to the existing log files on HDFS.
type scribe
port 14631
add_prefix scribe
type hoop
hoop_server hoop-server:14000
path /hoop/%Y%m%d/scribe-%Y%m%d-%H.log
username username
time_slice_wait 30s
flush_interval 5s
output_include_time false
output_include_tag true
output_data_type attr:message
add_newline false
remove_prefix scribe
default_tag unknown
Conclusion
Fluentd brings Facebook-like log aggregation infrastructure to your servers. The only difference is your system is a lot more flexible and does not require an army of engineers to maintain :)
And we’re hiring!
At Treasure Data, we are writing powerful software that makes Big Data accessible. All of your time should go into data analysis, not data management. We are here to help you do that.
We have a number of technical challenges ahead of us. We are small (a team of six) and actively looking for hackers and product managers who want to transform how people analyze Big Data. If you think you are a fit, please let us know. We’d love to talk to you!
Further Readings
- Fluentd Scribe Plugin
- Fluentd Hoop Plugin
- Fluentd Documentation
- Fluentd Plugins List
- Fluentd Source Code
- Tutorial: Store Apache Logs into Amazon S3
- Tutorial: Store Apache Logs into MongoDB
- Tutorial: Fluentd + HDFS: Instant Big Data Collection
Acknowledgement
Satoshi Tagomori is contributing the Hoop & Scribe plug-in for Fluentd. Also, he has ran comprehensive Fluentd benchmarks (in Japanese). Thanks Satoshi!
original link:http://blog.treasure-data.com/post/16034997056/enabling-facebooks-log-infrastructure-with-fluentd















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









