






一、Collection集合接口
Collection是单个集合保存的最大父接口。Collection接口的定义:
(1)历史时间:ArrayList是JDK1.2提供的,Vector是JDK1.0提供的。
(2)处理形式:ArrayList是异步处理,性能更高;Vector是同步处理,性能较低。
(3)数据安全:ArrayList非线程安全,Vector线程安全。
(4)输出形式:ArrayList支持Iterator、ListIterator、foreach;Vector支持Iterator、ListIterator、foreach、Enumeration。
5.子类LinkedList
(1)ArrayList由数组实现;
(2)LinkedList由链表实现。
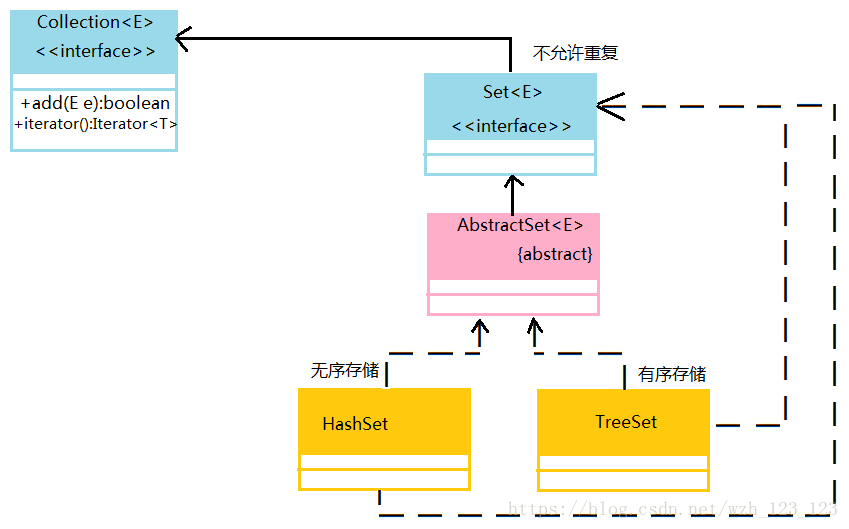
四、Set集合接口
1.Set接口与List接口最大的不同在于Set接口中的内容是不允许重复的。同时,Set接口中没有get()方法。
2.TreeSet排序
利用TreeSet进行对象数组的排序,对象所在的类要实现Comparable接口,并且覆写compareTo()方法。如果使用Comparable接口进行大小关系匹配,所有属性必须全部进行比较操作。
HashSet判断重复元素的方式依靠的是Object类中的两个方法:
(1)hash码:public native int hashCode();
(2)对象比较:public boolean equals(Object obj);
在Java中进行对象比较的操作有两步:第一步要通过一个对象的唯一编码找到一个对象的信息,第二步当编码匹配之后再调用equals()方法进行内容的比较。
(1)HashSet:无序存储,允许null,有且只有一个null;判断重复,需要覆写Object中的hashCode()以及equals()方法;只有两个对象的hashCode()以及equals()方法均返回true才认为两者相等。
(2)TreeSet:有序存储,不允许为null;如果要进行自定义类作为TreeSet存储,该类必须覆写Comparable接口
(3)Comparable:public int compareTo(Object o),类中所有属性都要参与运算
当>0,表示当前对象大于比较对象;
当=0,表示当前对象等于比较对象;
当<0,表示当前对象小于比较对象;
Collection是单个集合保存的最大父接口。Collection接口的定义:
public interface Collection<E> extends Iterable<E>此接口的常用方法如下:
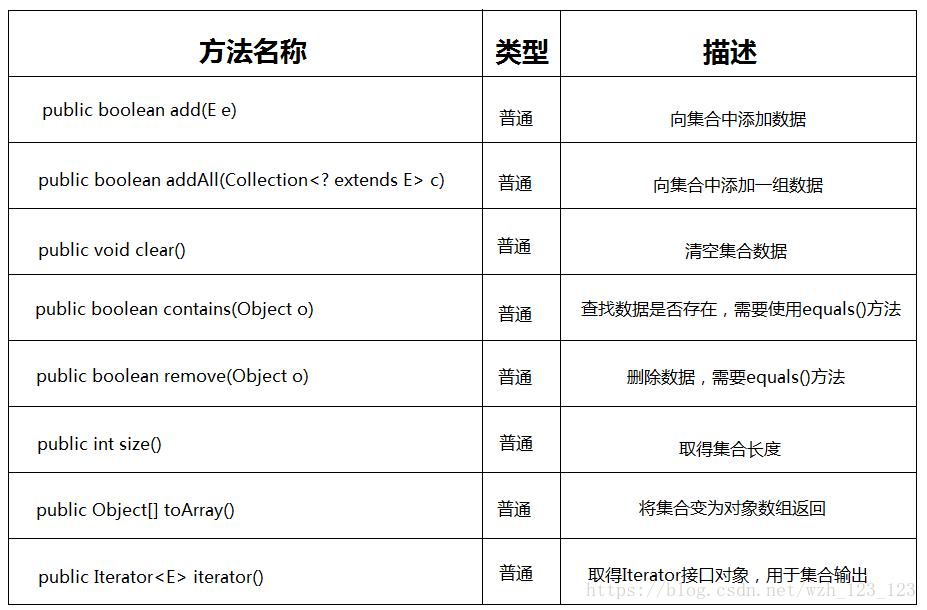
Collection接口定义:
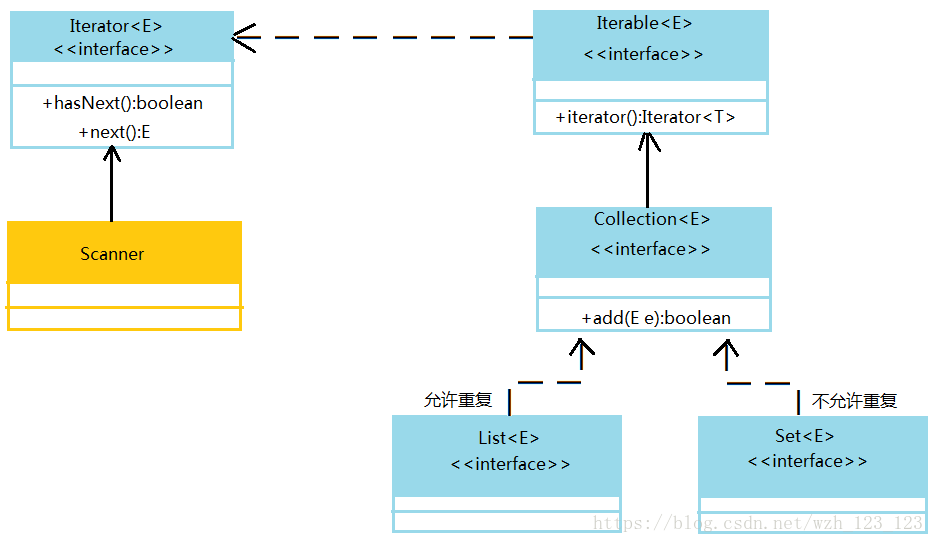
二、List接口
1.List接口中两个重要的扩充方法:
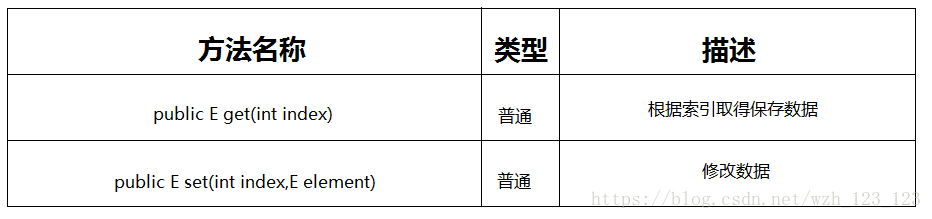
2.List接口下有三个常用子类:ArrayList、Vector、LinkedList
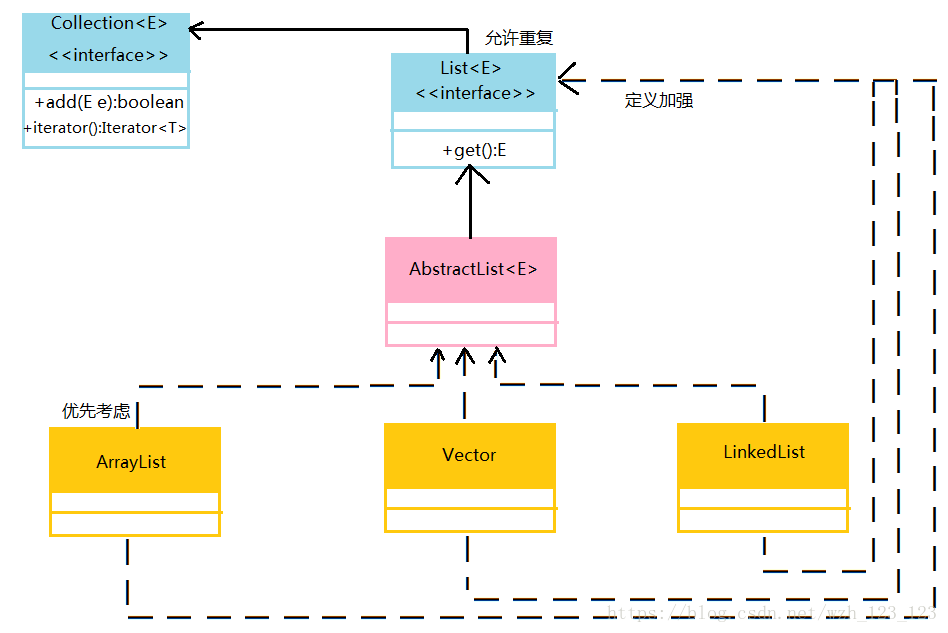
3.ArrayList子类
ArrayList是一个针对于List接口的数组实现。List允许保存重复数据。
如:List的基本操作
public class Test {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
System.out.println(list.size() + "," + list.isEmpty()); //查看list的大小,list是否为空
list.add("hello");
list.add("hello");
list.add("world");
System.out.println(list.size() + "," + list.isEmpty());
System.out.println(list); //打印list
System.out.println(list.remove("hello")); //删除hello
System.out.println(list.contains("ABC")); //查看list是否包含ABC;若包含,返回true;否则,返回false
System.out.println(list.contains("world")); //查看list是否包含world;若包含,返回true;否则,返回false
System.out.println(list); //打印list
//利用get()结合索引取得数据
for(int i = 0;i < list.size();i++) {
System.out.println(list.get(i));
}
}
}如:集合与简单Java类
class Person{
private String name;
private int age;
public Person(String name,int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
public class Test{
public static void main(String[] args) {
List<Person> pList = new ArrayList<>();
pList.add(new Person("小明", 10));
pList.add(new Person("小李", 20));
pList.add(new Person("小王", 30));
//集合类中的contains()、remove()方法需要equals()支持
System.out.println(pList.remove(new Person("小王", 30)));
System.out.println(pList.contains(new Person("小吴", 10)));
for (Person person : pList) {
System.out.println(person);
}
}
}如:使用Vector
public class Test{
public static void main(String[] args) {
List<String> list = new Vector<>();
list.add("A");
list.add("A");
list.add("B");
list.add("C");
System.out.println(list);
list.remove("C");
System.out.println(list);
}
}(1)历史时间:ArrayList是JDK1.2提供的,Vector是JDK1.0提供的。
(2)处理形式:ArrayList是异步处理,性能更高;Vector是同步处理,性能较低。
(3)数据安全:ArrayList非线程安全,Vector线程安全。
(4)输出形式:ArrayList支持Iterator、ListIterator、foreach;Vector支持Iterator、ListIterator、foreach、Enumeration。
5.子类LinkedList
如:使用LinkedList
public class Test{
public static void main(String[] args) {
List<String> list = new LinkedList<>();
list.add("A");
list.add("B");
list.add("C");
System.out.println(list);
list.remove("A");
System.out.println(list);
}
}(1)ArrayList由数组实现;
(2)LinkedList由链表实现。
四、Set集合接口
1.Set接口与List接口最大的不同在于Set接口中的内容是不允许重复的。同时,Set接口中没有get()方法。
在Set子接口中有两个常用子类:HashSet(无序存储)、TreeSet(有序存储)。
如:HashSet使用
public class Test{
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("A");
set.add("A");
set.add("B");
set.add("C");
System.out.println(set); //输出:[A, B, C]
}
}如:TreeSet使用
public class Test{
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("D");
set.add("A");
set.add("B");
set.add("A");
set.add("C");
System.out.println(set); //输出:[A, B, C, D]
}
}2.TreeSet排序
利用TreeSet进行对象数组的排序,对象所在的类要实现Comparable接口,并且覆写compareTo()方法。如果使用Comparable接口进行大小关系匹配,所有属性必须全部进行比较操作。
如:使用TreeSet排序
class Person implements Comparable<Person>{
private String name;
private int age;
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
public Person(String name,int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Person o) {
if(this.age > o.age) {
return 1;
}else if(this.age < o.age) {
return -1;
}else {
return this.name.compareTo(o.name);
}
}
}
public class Test{
public static void main(String[] args) {
Set<Person> set = new TreeSet<>();
set.add(new Person("李四", 10));
set.add(new Person("张三", 10));
set.add(new Person("张三", 10));
set.add(new Person("王五", 5));
System.out.println(set); //输出:[Person [name=王五, age=5], Person [name=张三, age=10], Person [name=李四, age=10]]
}
}HashSet判断重复元素的方式依靠的是Object类中的两个方法:
(1)hash码:public native int hashCode();
(2)对象比较:public boolean equals(Object obj);
在Java中进行对象比较的操作有两步:第一步要通过一个对象的唯一编码找到一个对象的信息,第二步当编码匹配之后再调用equals()方法进行内容的比较。
如:使用hashCode()与equals()消除重复
class Person{
private String name;
private int age;
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
public Person(String name,int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public class Test{
public static void main(String[] args) {
Set<Person> set = new HashSet<>();
set.add(new Person("李四", 10));
set.add(new Person("张三", 10));
set.add(new Person("张三", 10));
set.add(new Person("王五", 5));
System.out.println(set); //输出:[Person [name=李四, age=10], Person [name=张三, age=10], Person [name=王五, age=5]]
}
}(1)HashSet:无序存储,允许null,有且只有一个null;判断重复,需要覆写Object中的hashCode()以及equals()方法;只有两个对象的hashCode()以及equals()方法均返回true才认为两者相等。
(2)TreeSet:有序存储,不允许为null;如果要进行自定义类作为TreeSet存储,该类必须覆写Comparable接口
(3)Comparable:public int compareTo(Object o),类中所有属性都要参与运算
当>0,表示当前对象大于比较对象;
当=0,表示当前对象等于比较对象;
当<0,表示当前对象小于比较对象;














 4602
4602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









