







一 k8s java 应用内存限制不生效
回顾:Linux杂谈之java命令 容器环境JVM内存配置最佳实践

namespace负责资源隔离 cgroups负责资源限制 容器JVM最佳实践
Metaspace 是 '非 Heap 内存' 管理空间,那么 Heap 就是'操作'空间隔离: 两个进程完全'隔离'
感知: 使用 docker 的时候会感觉'每个容器启动'的应用之间'互不'干扰
从'文件系统、网络、CPU、内存'这些都能完全'隔离'开来,就像两个运行在'不同的服务器中'的应用
补充: 容器在'宿主机'表现为一个'进程'
++++++++++ "分割线" ++++++++++
限制: CPU、内存、磁盘、带宽等
推荐 JVM 的配置'约等于'容器限制的 '70%~80%'
补充: hpa 设置'不合理' 导致 '频繁重启'① 问题引入
思考: 如果在'java容器'中 未设置JVM相关参数、或设置不合理导致'不生效'
现象: java 应用 limit是8G,- Xms是6G,但是实际检'监测'到服务跑了7g,但是应用'没有被OOM'
补充: 金融容器,执行 'free -m' 看到的内存使用状况和'宿主机'中的保持一致
云原生时代: JVM '内存机制' 和 Kubernetes '内存管理'
'观测'方式: docker stats 和 kubectl top pods -n 观察 '内存'使用
docker stats --no-stream --format \
"table{{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.NetIO}}\t{{.BlockIO}}\t{{.PIDs}}"
-XX:MaxRAMPercentage, -XX:MinRAMPercentage -Xmx, -Xms
细节: jdk '1.8191+ '设置 'Percentage'值时候'不能'为整数,jdk1.10+之后可以'为整数'
1、在191版本'后',-XX:{Min|Max}RAMFraction 被'弃用'
2、引入了-XX:MaxRAMPercentage,其值介于0.0到100.0之间,默认值为'25.0'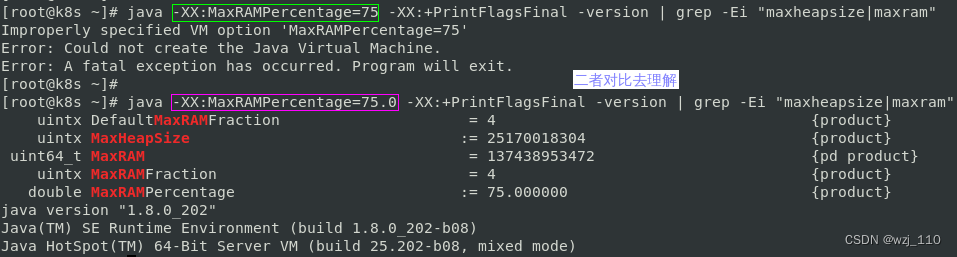
JVM UserContainerSupport 推荐JVM参数设置
-XX:+UseContainerSupport 允许 JVM 从'主机'读取 cgroup 限制
例如: 可用的 CPU 和 RAM,并进行相应的配置
效果: 这样当容器超过'内存限制'时,会抛出'OOM异常',而'不是'杀死容器![]()
选用jdk版本: jdk 8u191+,推荐'1.8.0_202'
核心JVM参数: -XX:UseContainerSupport -XX:MaxRAMPercentage=75.0
补充: jdk8u191+ 为 '适配 docker容器' 新增上面'几个'参数 ③ Java启动一些默认行为
'默认'情况下,JVM '自动'分配的 heap 大小取决于'机器'配置
比如: 我们到一台 '32G' 内存服务器
java -XX:+PrintFlagsFinal -version | grep -Ei "maxheapsize|maxram"
-Xms: 初始'heap'堆内存,会会立刻'被占用',默认为物理内存的 '1/64'
-Xmx: 最大堆内存,或者说'Heap'堆内存的'上限',默认为物理内存的 '1/4'
一个容器内存分配: 'Heap' + '非Heap [MetaSpace]等' + '容器中其它内存'
细节: 需要在最大'堆空间'、'非堆内存'使用量和 'pod 限制'之间取得平衡
补充: 'ES' 要求 -Xms和-Xmn保持'一致'
++++++++++++++ "分割线" ++++++++++++++
1、MaxMetaspaceSize的默认值是'无限制',推荐设置'256M'
2、但可以通过'-XX:MetaspaceSize'和'-XX:MaxMetaspaceSize'来设置初始和最大值
++++++++++++++ "分割线" ++++++++++++++
-XX:InitialRAMPercentage=75.0 -XX:MaxRAMPercentage=75.0 \
-XX:MinRAMPercentage=75.0 -XX:+PrintGCDetails -XX:+PrintGCDateStamps \
-XX:+PrintTenuringDistribution -XX:+PrintHeapAtGC -XX:+PrintReferenceGC \
-XX:+PrintGCApplicationStoppedTime -Xloggc:gc-%t.log \
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=15 -XX:GCLogFileSize=50M
2C4G --> 配置指定 75% ,相当于设置了 -Xms3g -Xms3g

了解'业务代码' + '线上运维环境' --> '最佳定位' --> '运维开发'
-XX:UseContainerSupport -XX:MaxRAMPercentage=75.0 -XX:MinRAMPercentage=75.0
-Xms -Xmn
++++++++++++ '查看容器对应的宿主机PID' ++++++++++++
docker top container_id
docker inspect -f '{{.State.Pid}}' container_id 














 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









