







本文提出了一种用于红外小目标检测的增强特征学习网络(EFLNet),通过自适应阈值焦点损失(ATFL)、归一化高斯 Wasserstein 距离(NWD)和动态头机制,有效解决了目标背景不平衡、边界框回归敏感和特征丢失问题,显著提升了检测性能。
一、EFLNet论文介绍

论文地址:
https://arxiv.org/pdf/2307.14723
该文档提出了一种用于红外小目标检测的增强特征学习网络(EFLNet),通过自适应阈值焦点损失(ATFL)、归一化高斯Wasserstein距离(NWD)和动态头机制,有效解决了目标背景不平衡、边界框回归敏感和特征丢失问题,显著提升了检测性能。
背景与挑战
- 红外小目标检测难点:目标占比极小(仅几个像素)、背景复杂、信噪比低,导致传统方法(如滤波器、低秩分解)在复杂场景下性能不足。
- 深度学习方法局限:现有基于分割的方法依赖像素级处理,计算量大且无法直接评估检测性能;基于检测的方法受限于目标背景不平衡、IoU对小目标敏感及特征丢失问题。
方法创新
- 自适应阈值焦点损失(ATFL)
- 目标背景解耦:通过阈值0.5区分难易样本,对易分类的背景样本降低损失权重,对难分类的目标样本增加权重。
- 自适应超参数:根据训练进度动态调整γ和η,减少手动调参成本,提升训练效率。
- 归一化高斯Wasserstein距离(NWD)
- 高斯分布建模:将边界框表示为二维高斯分布,均值为框中心,协方差矩阵由宽高决定。
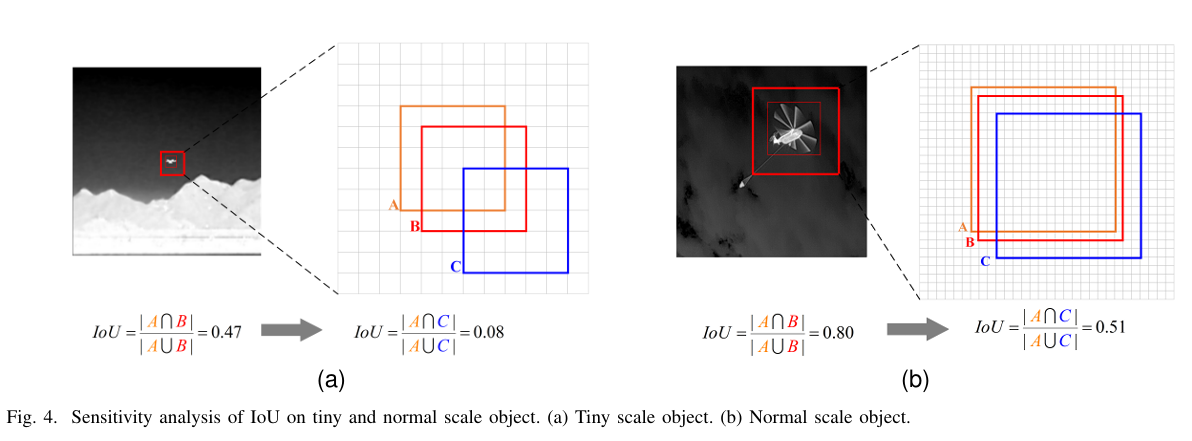
- Wasserstein距离计算:通过计算两个高斯分布的二阶Wasserstein距离,并归一化为0-1范围,解决IoU对小目标位置偏差敏感的问题。
- 动态头机制
- 多尺度特征融合:通过尺度感知、空间感知和任务感知注意力,自适应学习不同语义层的重要性,增强浅层特征对小目标的关注。
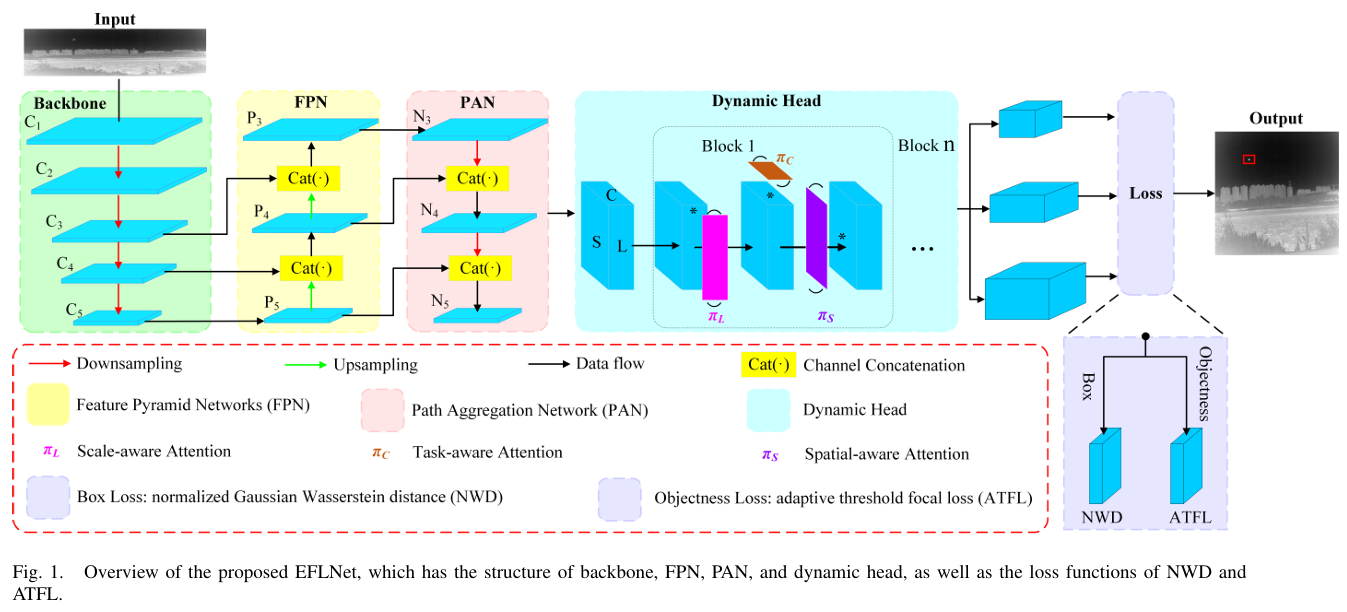
应用模块
- 网络架构
- 骨干网络:采用FPN和PAN融合多尺度特征。
- 动态头:集成三种注意力机制,优化特征融合。
- 损失函数
- ATFL:处理样本不平衡。
- NWD:优化边界框回归。
实验结果
- 数据集
- NUAA-SIRST、NUDT-SIRST、IRSTD-1k,包含分割和边界框标注。
- 评估指标
- Precision、Recall、F1-score。
- 定量结果
- EFLNet在三个数据集上均优于现有SOTA方法,如在NUAA-SIRST上F1达0.870,NUDT-SIRST上达0.947,IRSTD-1k上达0.843。
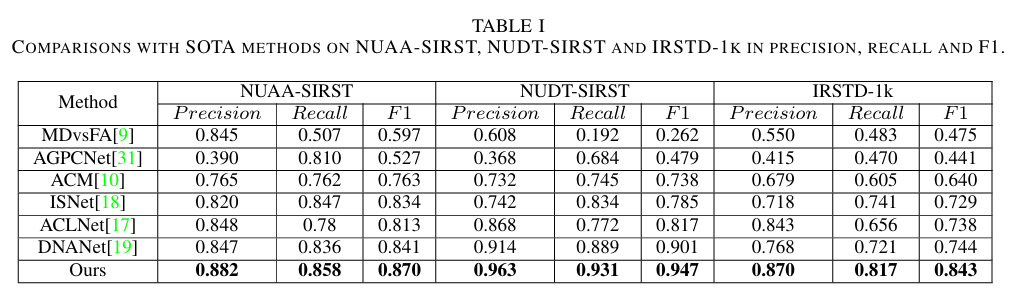
- 消融实验
- ATFL:自适应超参数显著优于固定参数,λ=3.5时性能最佳。
- NWD:参数C=11时效果最优,缓解模型收敛困难。
- 动态头:4个模块时性能最佳,提升特征学习能力。
结论
- 贡献:提出EFLNet解决红外小目标检测的三大挑战,ATFL和NWD分别优化样本平衡和边界框回归,动态头增强特征学习。
- 应用价值:在公开数据集上实现SOTA性能,并提供边界框标注数据集,推动红外小目标检测从分割转向检测任务。
二、加入实验部分
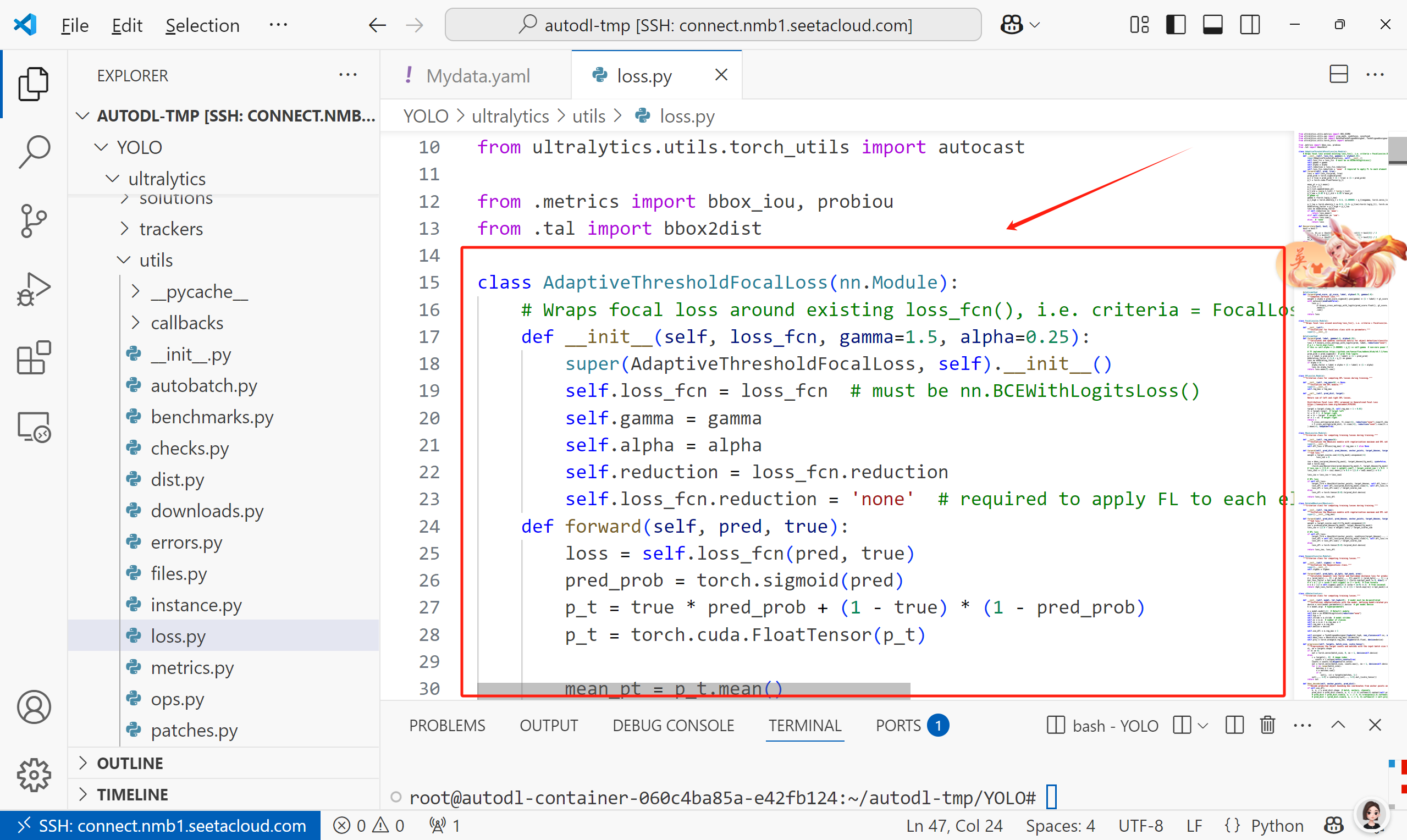
2.1 修改:./ultralytics/utils/loss.py
加入以下代码:
class AdaptiveThresholdFocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(AdaptiveThresholdFocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred)
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
p_t = torch.cuda.FloatTensor(p_t)
mean_pt = p_t.mean()
p_t_list = []
p_t_list.append(mean_pt)
p_t_old = sum(p_t_list) / len(p_t_list)
p_t_new = 0.05 * p_t_old + 0.95 * mean_pt
# gamma =2
gamma = -torch.log(p_t_new)
p_t_high = torch.where(p_t > 0.5, (1.000001 - p_t)**gamma, torch.zeros_like(p_t))
p_t_low = torch.where(p_t <= 0.5, (1.5- p_t)**(-torch.log(p_t)), torch.zeros_like(p_t))
modulating_factor = p_t_high + p_t_low
loss *= modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
2.2 修改:class v8DetectionLoss:
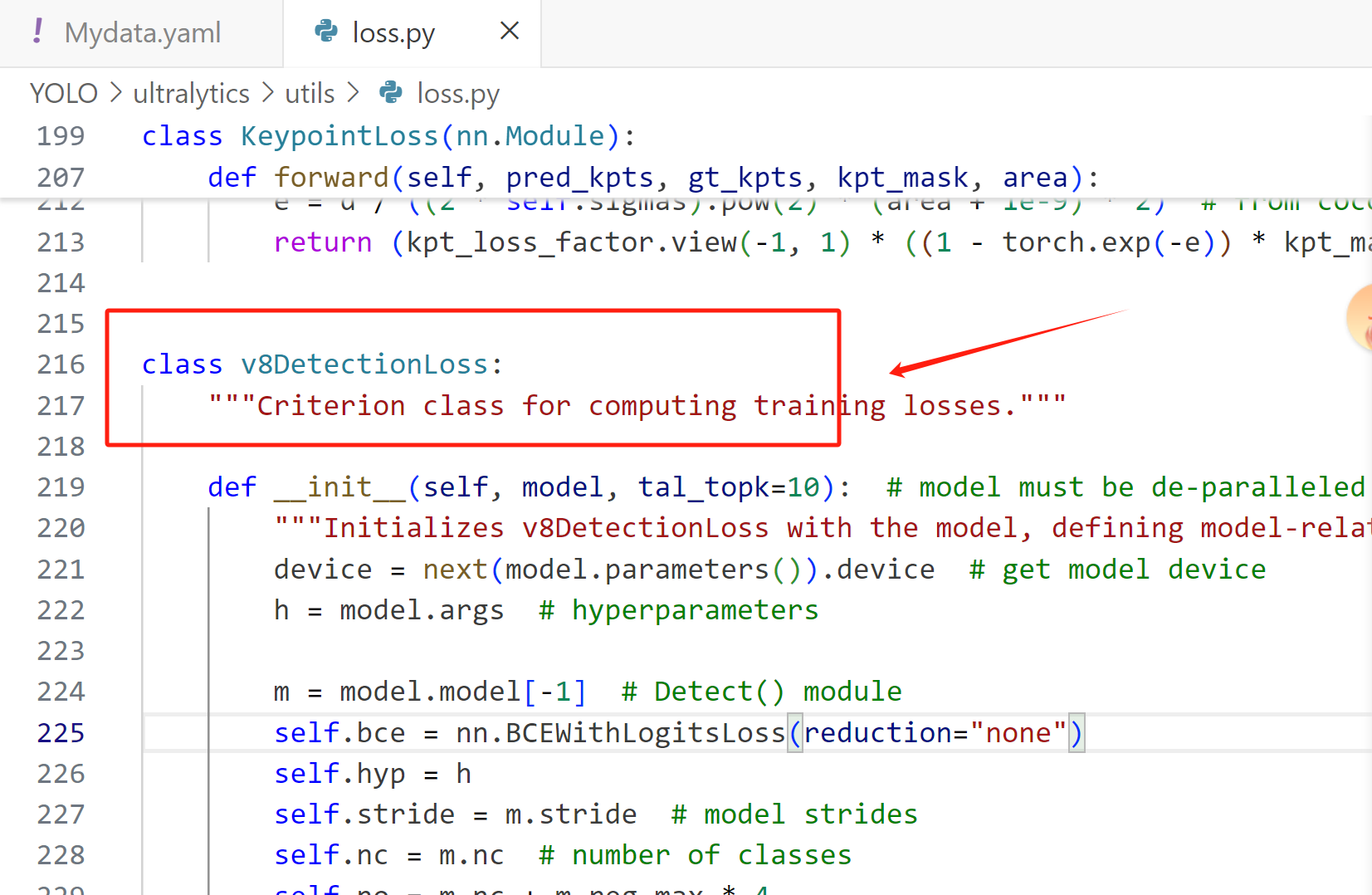
最开始的原始结果为:
self.bce = nn.BCEWithLogitsLoss(reduction="none")
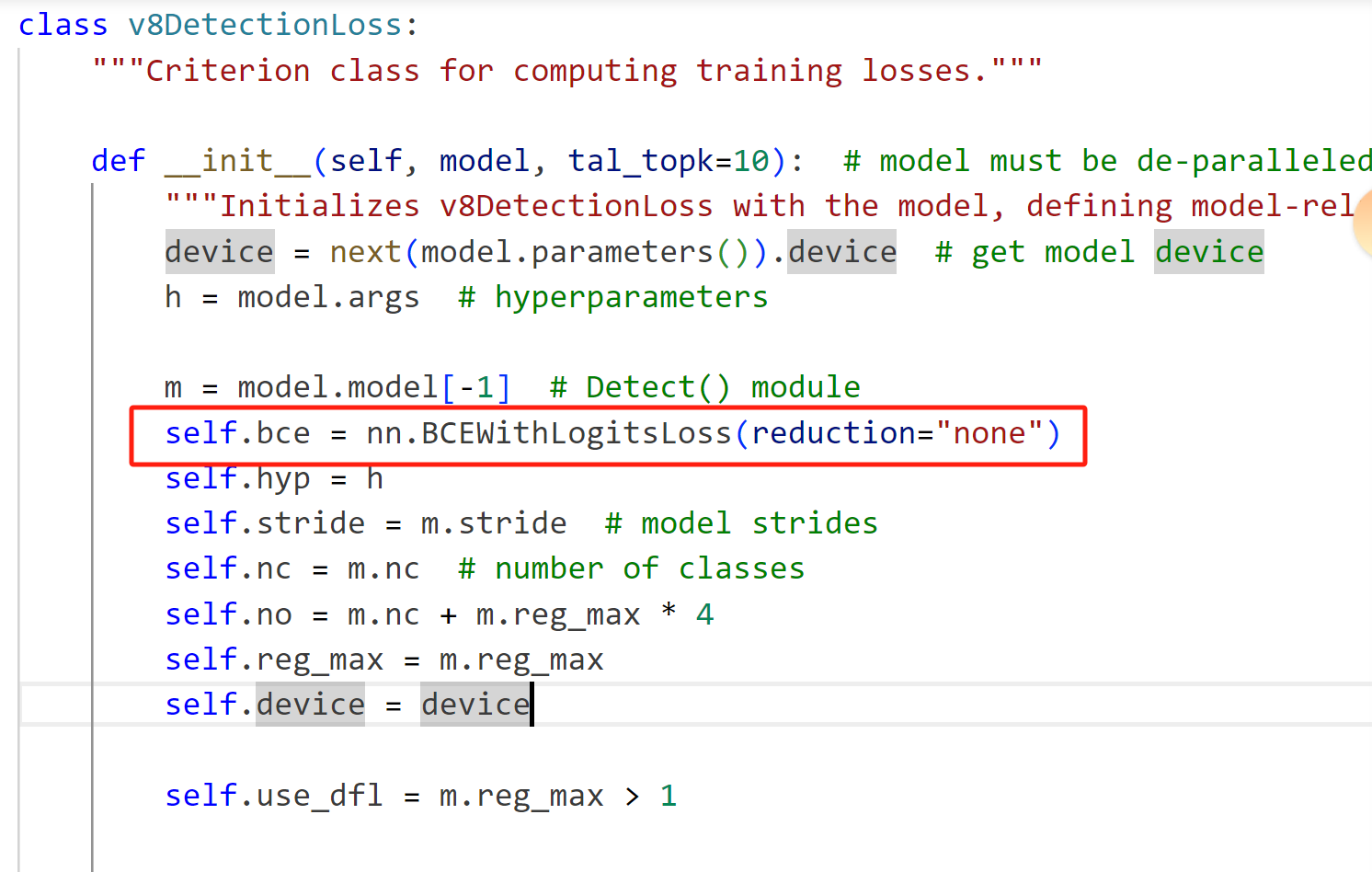
修改为:
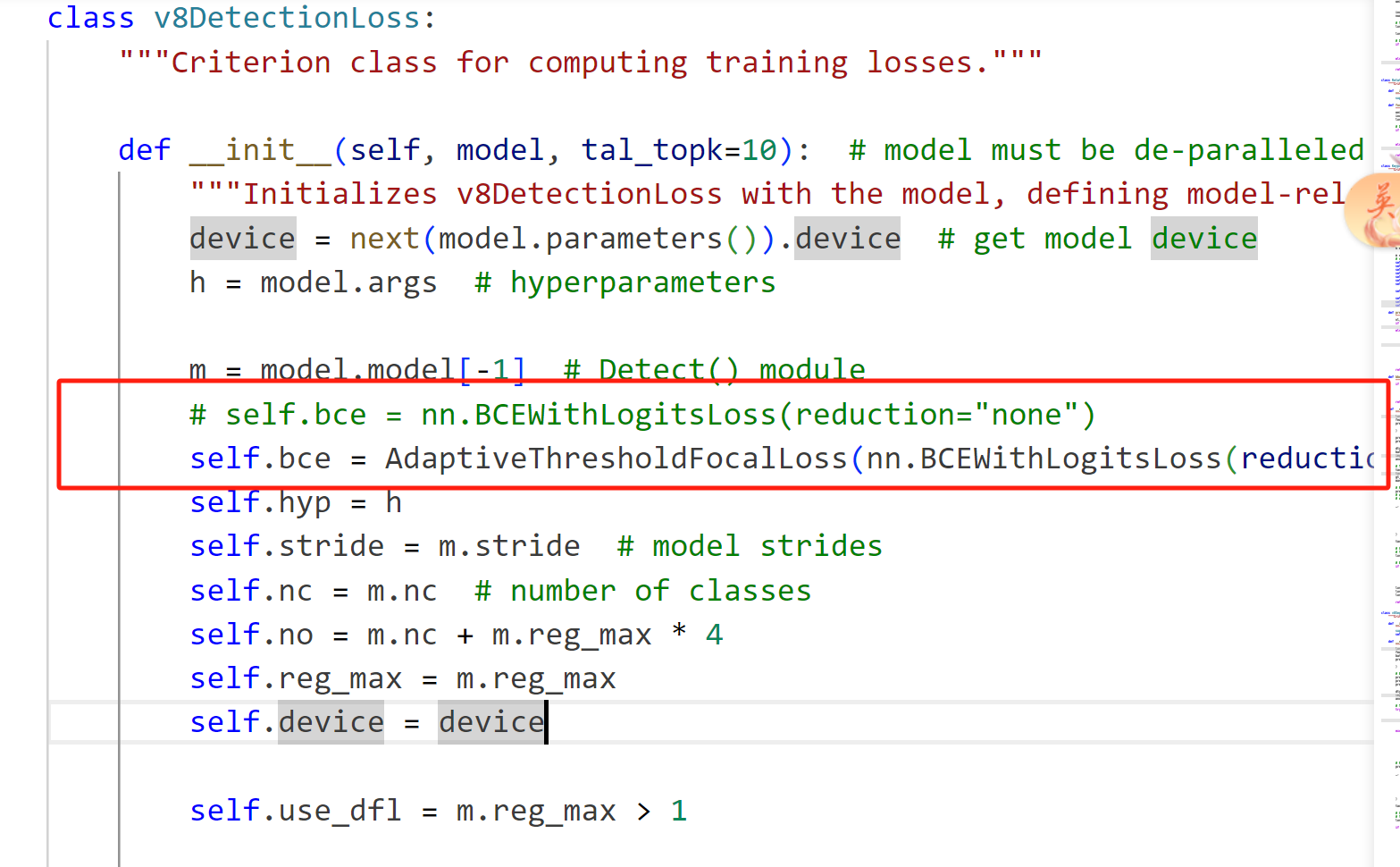
self.bce = AdaptiveThresholdFocalLoss(nn.BCEWithLogitsLoss(reduction="none"))
2.4 修改:_call_(self, preds, batch):
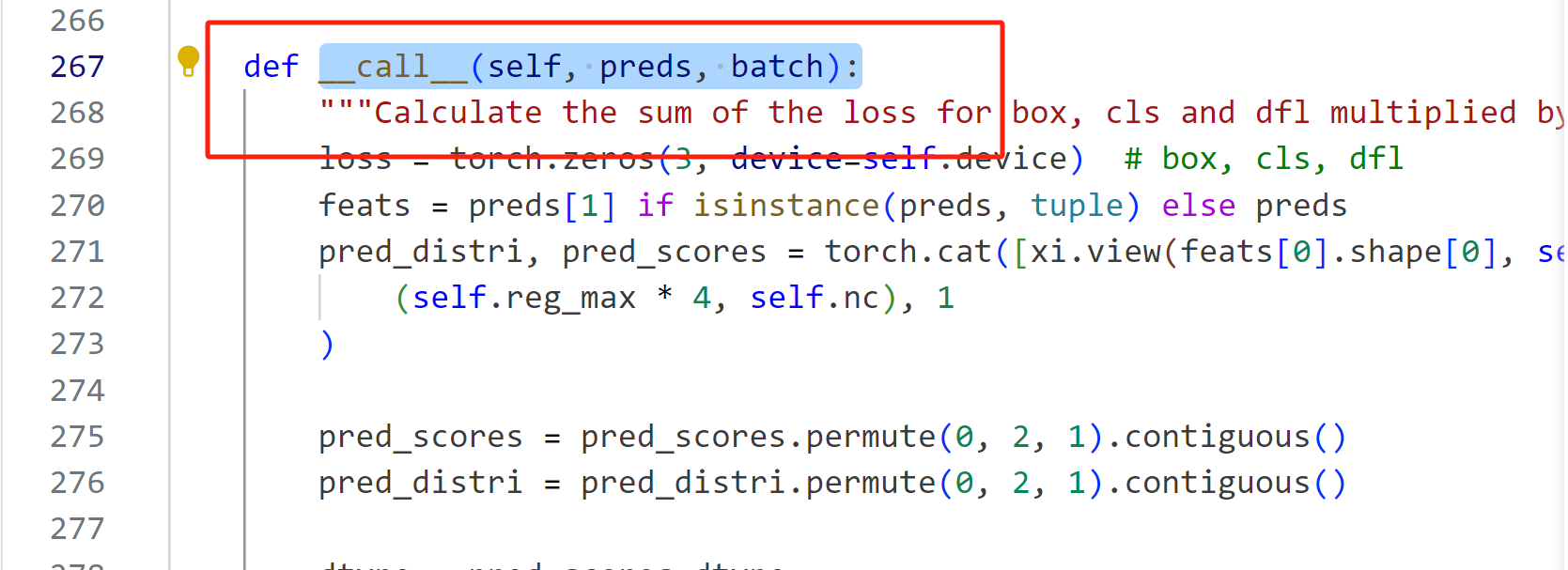
最初的代码为:
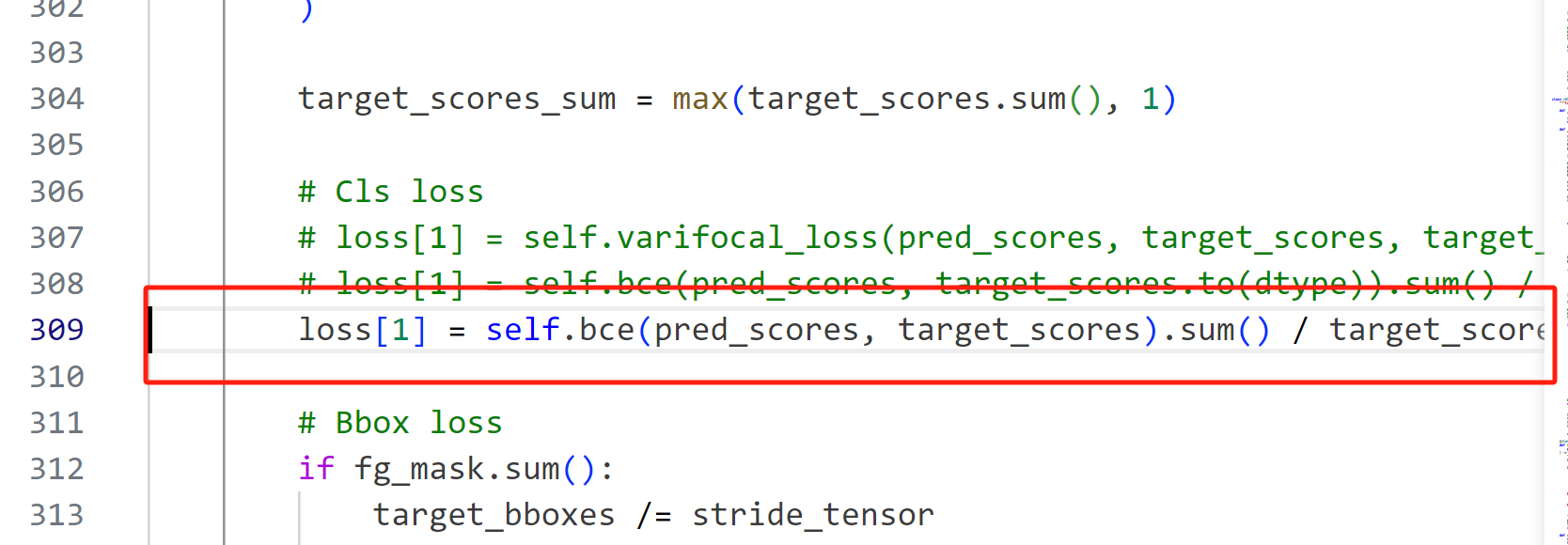
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE

修改为:
#loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
loss[1] = self.bce(pred_scores, target_scores).sum() / target_scores_sum # BCE
接下来运行起来即可,还是epochs=5尝试:
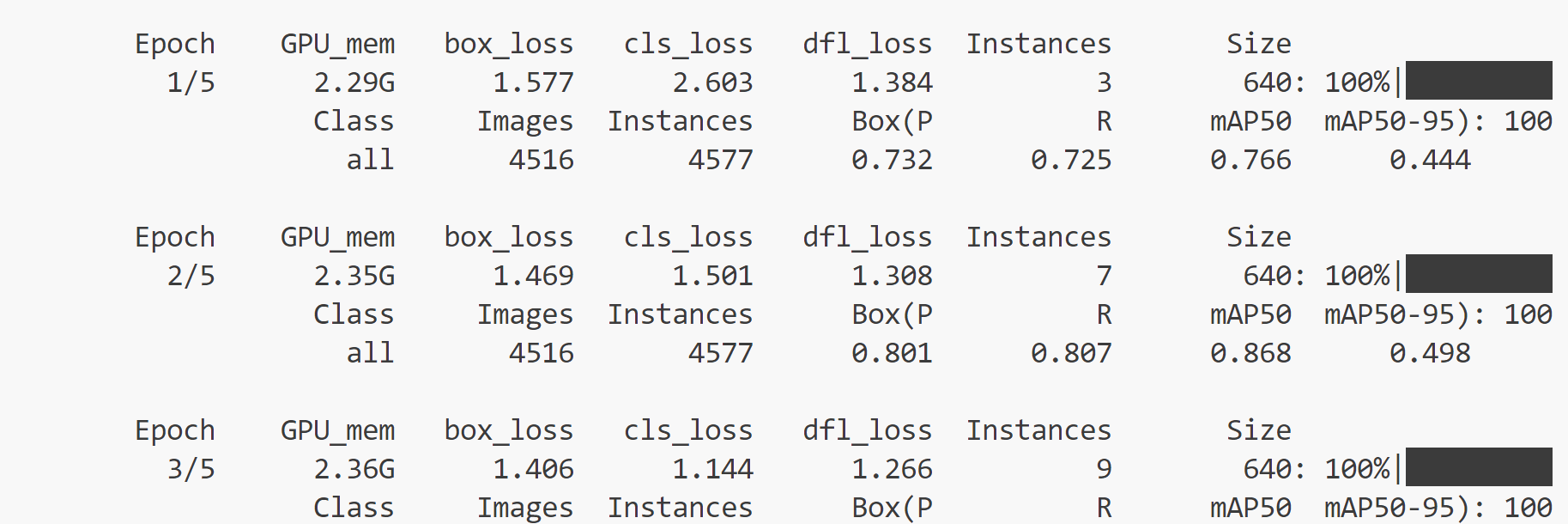
稳定运行!


















 8095
8095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











