






注:本博文是对Aapo Kyrola的论文:GraphChi : Large-Scale Graph Computation on Just a PC的部分理解,如有不对之处,欢迎及时提出。
问题的重要性
图作为一种关系的抽象可以应用于很多场合,例如社交网络,网页之间的联系,生物蛋白之间的相互作用。从现实场景抽象出来的图中一般蕴含着许多有用的信息,很有挖掘价值。然而这些图的规模通常都很大导致普通的算法无法适用。于是设计一种能够进行处理,计算和挖掘大型图信息的系统成为当前研究面临的挑战。
问题可能的解决方案
–基于分布式系统
当前可以通过分布式系统对规模达到上亿条边的图进行计算处理。然而不足的是,虽然分布式资源现在很容易获得,但针对图计算的分布式算法并不多。开发图计算的分布式算法可以说是件很困难的事情,因为基于现存的框架,首先要面临的是有效的图分割方法,这一点的难度并不亚于问题本身,并且有些图由于自身的拓扑根本就不能分割。其次从开发着角度看,优化分布式算法和调试bug也不是一件简单的事情。假设开发出来了,从用户角度看,他们不得不忍受在管理分布式系统时出现的各种可能的不可预见的错误。
–基于廉价的PC机
开发基于分布式的图处理系统从而解决大型图计算问题从上述来看并不是一朝一夕的事情。因此能不能只在廉价的单台机器上实现。可能的方法有:
1. 扩充主存
因为处理大规模的图可能需要上百G的内存,全部放在内存中处理对电脑的其他性能要求也很高。这与采用廉价的PC机的初衷不相符合。
2. 使用辅存
使用辅存是可行的选择,但必须运用恰当的技巧才不影响计算的效率。可能的方案有:
- 使用SSD作为扩展的主存
SSD具有良好的随机读和连续写的能力,很多研究提出利用SSD,其中最具代表的是SSDAlloc技术。SSDAlloc将SSD作为堆空间使用,通过一些新奇的方法能够实现对象层次的缓存,从而增加连续的写。不幸的是,在大型图中一方面处理的对象往往是顶点或边,它们通常很小但数量很多;另一方面很多图算法中读和写的次数基本相等。因此导致这种方案效率并不高。 - 利用图的局部性
很多从现实中抽象出来的图都具有局部性,例如相同领域的网页更会聚集在一起、地理上靠近的用户在社交网络中会形成社区等等。然而,现实中的图的局部性的局限性是,即使是在局部里也往往会有大量的边。而且一方面因为这种方案依赖图的拓扑结构,因此可能不适用很多其他结构的图,另一方面基于局部性的算法有时开销会很大,甚至不可能实现。 - 改变图在辅存的存储方式
改变图存储方式的方法有一种是在辅存中存图的邻接表信息,即CSR:行邻接表 和 CSC:列邻接表。但种方法会导致随机读或写的出现。例如现有一条边(u,v)和边上的权重x。更改顶点u上的值位y,但当对顶点更新时,它需要更新后的入边值y。因此或者在CSR存储模式下当读v时,同时读入y,这会导致随机读;或者在CSC下当更新x至y时,写入边中,这会导致随机写。若采用这种方式,当对整个图中的每条边更新时,将会导致o(E)个随机读或o(E)个随机写。改变图存储的另一种方法是对图进行压缩,值得指出的是在最好的图压缩算法里,一条边仅需4bit,这听起来很诱人,然而我们往往不得不为每条边和每个顶点维护相应的压缩信息,这有时候花费的空间开销更大。
并行滑动窗口技术(BSW)
上述各种方案的不高效或不可行,促使Aapo Kyrola提出了一种并行滑动窗口的技术(BSW)。该技术将图存于辅存(SSD或者磁盘)中,只需要很少次数的非连续读写辅存便可以实现每秒达百万次的图更新计算,并且支持异步计算模型。BSW对图的处理分成三个步骤:
(1) 将整个图的一个子图从辅存中调入主存
在BSW的方法里,图G中的顶点集合V被分成P个不相交的intervals。每个interval都有一个shard相对应。若一条边的尾部结点在某个interval中,则这条边被存入该interval关联的shard中,例如边(3,4)将会存入4所在的interval的shard中。同一个shard内部的边按照头结点升序排列。关于interval的数量,应该取的一方面使得shard之间的边数较均匀,另一方面使得每个shard都能完整的存入主存中。具体的如下图所示:
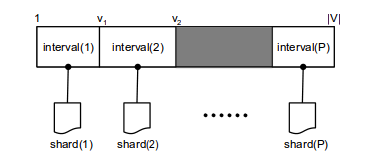
所谓图的一个子图,是由interval中的顶点以及它们所关联的出边和入边组成。因此调入主存的过程分为两步:首先将interval(p)中的结点和shard(p)中的边全部调入主存,此时还缺少这些顶点关联的出边。由于shard中的边是按照头结点顺序存储,所以这些出边在其他shard中都是连续存放的。因此其次是从剩下的P-1个shard中读取出边。从整个调入的过程可以看出共需要P次非连续的读操作。具体如图所示:
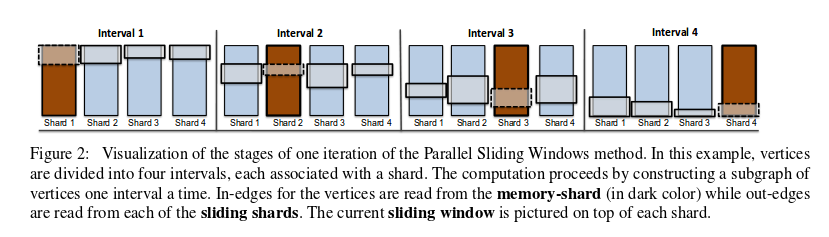
(2) 对调入主存中的子图,由用户自定义的update_function进行更新
当interval(p)中结点构成的子图完全调入主存后,便可以调用用户自定义的更新函数,对其中的每一个结点执行并行更新操作(由此可看出该更新是以结点为中心的),直到满足某种结束条件。具体的更新函数框架如下:

由于更新的过程是并行的,可能存在同时相邻的结点更新同一条边的情况。此时为了数据的一致性,可采取若是边的两个结点均在interval(p)中,则按边的顺序更新;若头结点不在当前interval(p)中则可以安全的并行执行
(3) 将更新后的子图写回
在写回的时候,由于调入时是整块在主存中缓冲,且更新时是通过指针直接作用于内存地址。因此,可以直接将更新的部分写回辅存,将原数据覆盖。要指出的是,当一条边只有一个方向的更新时,将会更加方便。
具体例子:
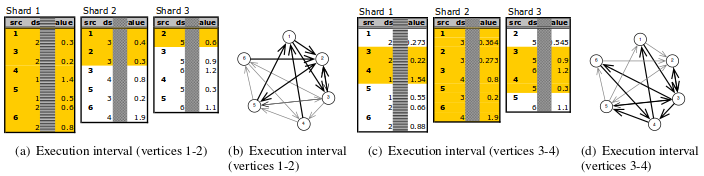
在这个例子中共有6个结点,每两个为一个interval,共分成三个interval:1-2,3-4,5-6。图中的(a)展示了最初的三个shard的内容。假设PSW从第一个interval开始执行,首先调入相对应的子图(如图中(b)所示),从(a)中很容易看出1-2结点对应的出边在shard2和shard3中均是连续存放的。当继续执行第二个interval时,对应的子图如图中(d)所示。此时从图(c) 可以看出,shard1和shard3刚好指向的就是要读入的内容。
I/O开销分析
假设算法的I/O的开销是以执行过程中从辅存调入主存的block的数量计算。该算法的一个上限是总的读写数除以shard的数量加上非连续读写的次数。又因为当需要对每条边的两个方向进行更新时,需要分别读两次,写两次,而且已知每个interval需要P个非连续读,所以P个interval共需要P的平方个读。当只需要对每条边的一个方向进行更新时,只需要读写各一次。因此综上可得该算法的I/O开销范围为:
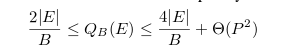















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









