






前言:最近大部分时间都在研究爬虫。公司需要爬取某些网站的数据,动辄千万,亿级页面数据。基于页面量太大。一台机器的爬取效率有限,这时候笔者就想利用多台机器来进行爬取(当然,机器并非越多越好,还要考虑到待爬取网站的服务器性能)。
主要技术栈
- Node.js
- Puppeteer
- MongoDB
- Redis
什么是分布式爬虫
- 单机爬虫,就是说它只能在一台电脑上运行,因为爬虫调度器当中的队列queue都只能在本机上创建的,其他电脑无法访问另外一台电脑上的内存和内容。
- 分布式爬虫实现了多台电脑使用一个共同的爬虫队列,它可以同时将爬虫任务部署到多台电脑上运行,这样可以突破一台机器性能限制,提高爬虫速度。
关于单机爬虫
单机爬虫一般实现如下:
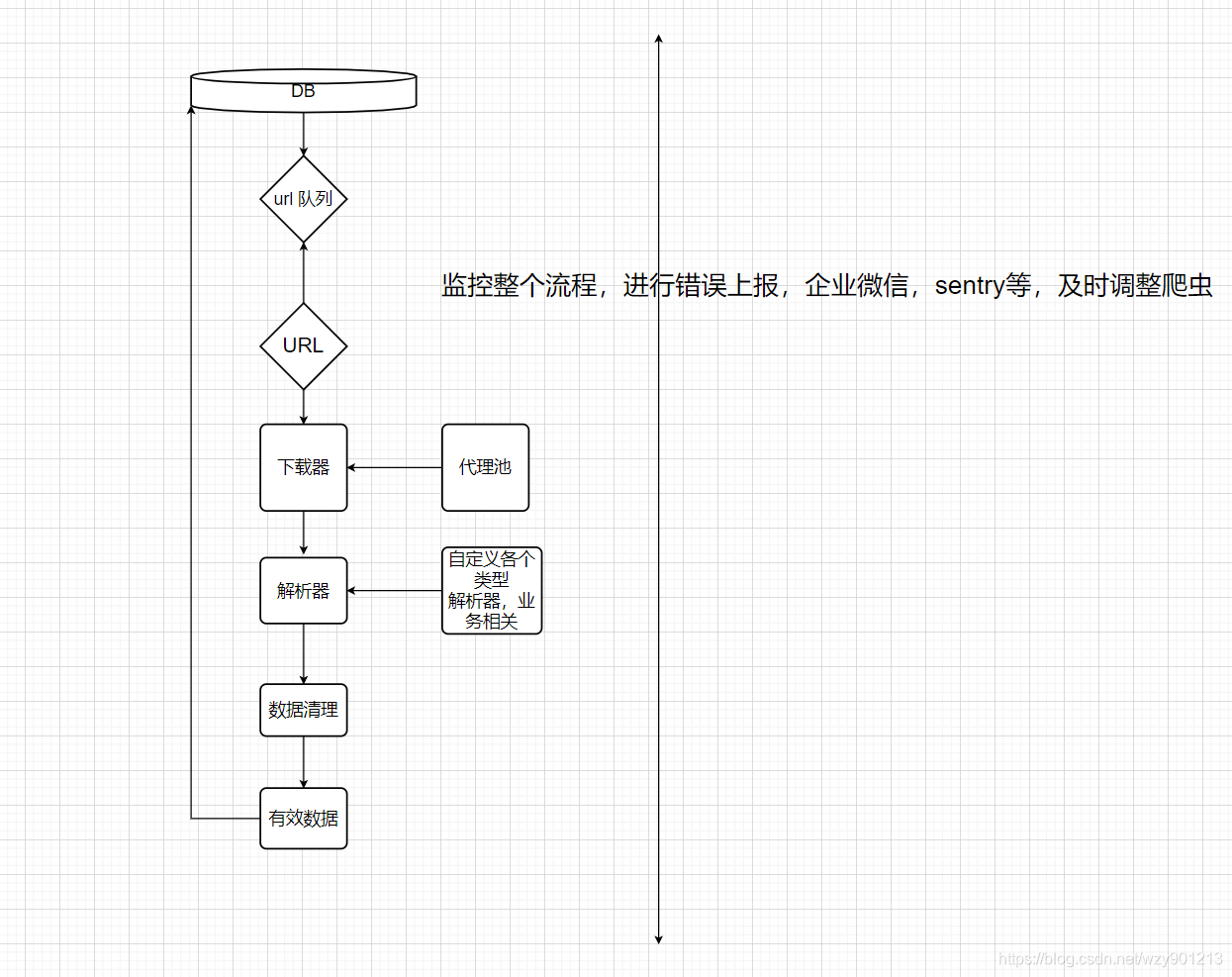
问题描述
如果需要多开机器运行单机爬虫,需要解决数据共享问题,不能同时处理同一个URL。相互处理的数据应该互不影响。所以,我们把其中一台设为Master 端,其他机器为Slaver 端。
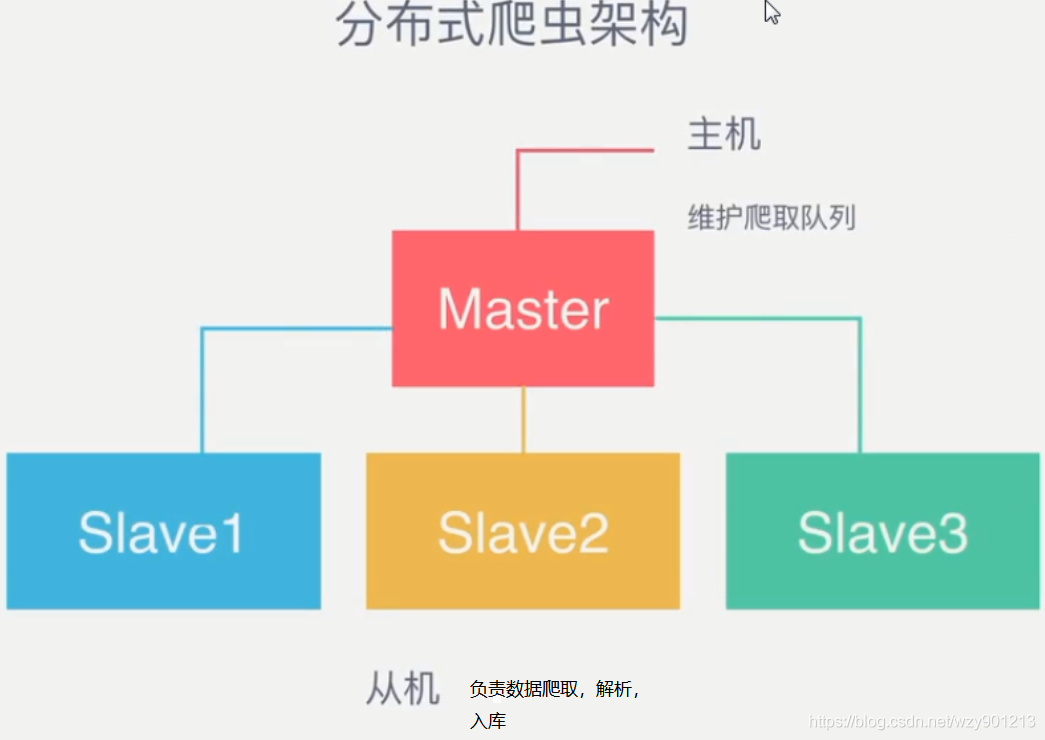
心路历程
所有Slaver端 从Master端 获取数据并进行处理。这里我们可以使用Kafka或者RabbitMQ来实现。但是笔者在研究的过程中发现其他MQ组件过重,太过于专业,例如我们如果用RabbitMQ,Kafka就必须为它搭建一个服务器,同时如果要考虑可用性,就要为服务端建立一个集群,而且在生产如果有问题也需要查找功能。所以笔者选择了使用Redis来做轻量级消息队列 。
Master 端伪代码:
...
const redis_client = redis.createClient( 6379, '127.0.0.1');
redis_client.lpush('MSGQ', JSON.stringify(message), function(err, reply){
if(err){
console.log('lpush message error :' + err);
}else{
console.log('lpush message success');
}
});
Slaver端伪代码:
...
const redis_client = redis.createClient( 6379, '127.0.0.1');
var producer = function() {
while(true){
//brpop 是阻塞式的,don't worry!!!
redis_client.brpop("MSGQ", 0, function(err, re) {
//获取消息,执行爬取任务
crawlData(re);
});
}
};
producer();
在这里,我们的主从都是使用本机来模拟的,当然实际上,主从端分别是不同的机器,从机开启循环不断从Redis里面pop数据,这样每个从机的数据互不干扰,相互隔离,你爬你的数据,我爬我的数据。我们可以开无论多少台机器一起来处理数据。
最终效果
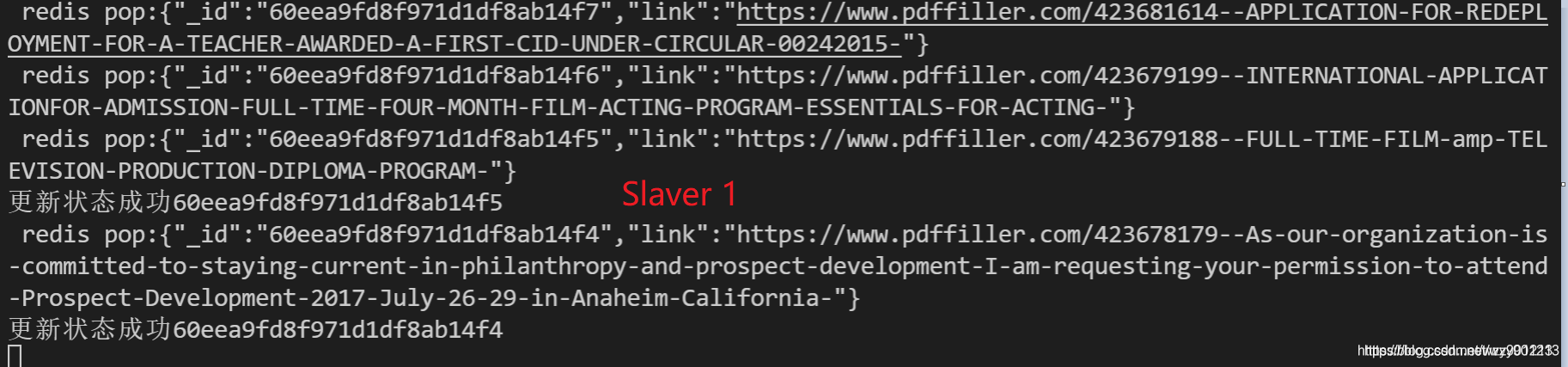
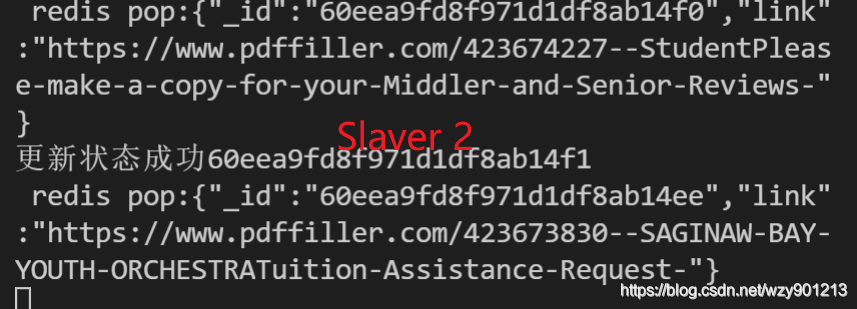
我们打开Redis可视化视图,发现MQ在逐渐被消耗
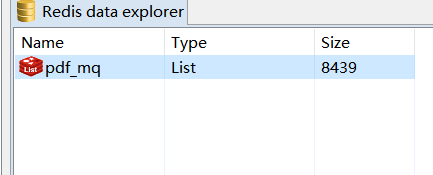 (一段时间后…)
(一段时间后…)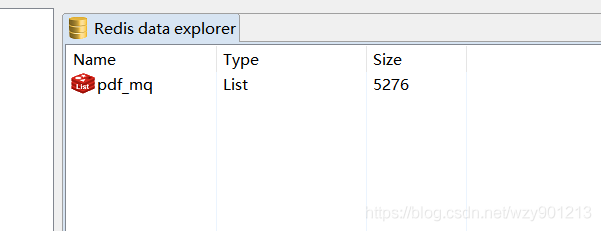
这样我们就可以开多台机器来处理爬虫,加大爬取效率。
总结
最后,我们通过一张图来总结下















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









