







词典搜索的数据结构
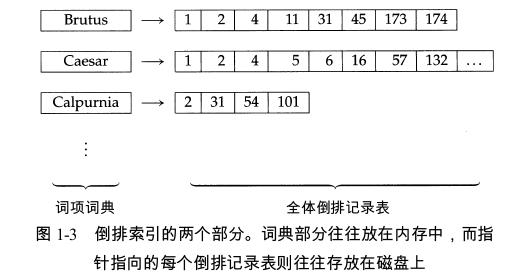
如上图,倒排索引记录表构建好了。对于查询请求“Brutus”,我们首要任务是确定查询词项“Brutus”是否在词典的词项词汇表中,如果在,则返回该词项对应的倒排记录表的指针。词汇表的查找操作往往采用一种称为词典(dictionary)的经典数据结构,并且主要有两大类解决方法:哈希表方式和搜索树方式
哈希表方式
每个词项通过哈希函数映射成一个整数,映射函数的目标空间需要足够大,以减少哈希结果冲突的可能性。查询时,对于每个查询项分别进行哈希操作,并解决存在的冲突,最后返回每个查询词项对于的倒排记录表的指针
优点:在哈希表的定位速度快于树中的定位速度
缺点:(1)没办法处理词项的微小变形(2)不支持前缀搜索(3)如果词汇表不断增大,需要定期对所有词项重新哈希
搜索树方式(二叉树以及B树)
优点:支持前缀查询
缺点:搜索速度略低于哈希表方式:O(logM),其中M是词汇表大小,即所有词项的数目。O(logM)仅仅对平衡树成立
通配符查询
B树结构词典通配符查询处理
- 对mon*的查询操作,通过遍历B树
- 对*mon的查询操作,通过遍历反向B树
轮排索引
基本思想:
- 在字符集中引入一个新的符号$,用于标识词项结束
- 将每个通配查询旋转,使*出现在末尾
- 将每个旋转后的结果放在词典(B树)中。即对词典中的词项词汇表再进行一层索引
拼写校正
用途:
- 纠正待索引文档。在IR领域,我们主要对OCR处理后的文档进行拼写校正处理。(OCR=optical character recognition,光学字符识别)。IR领域的做法是:不改变文档
- 纠正用户查询
方法:
- 编辑距离
- k-garm重合度方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









