






spark
一,spark的介绍
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。

二,spark的特点
运行速度快:
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中。

Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群来验证解决问题的方法。
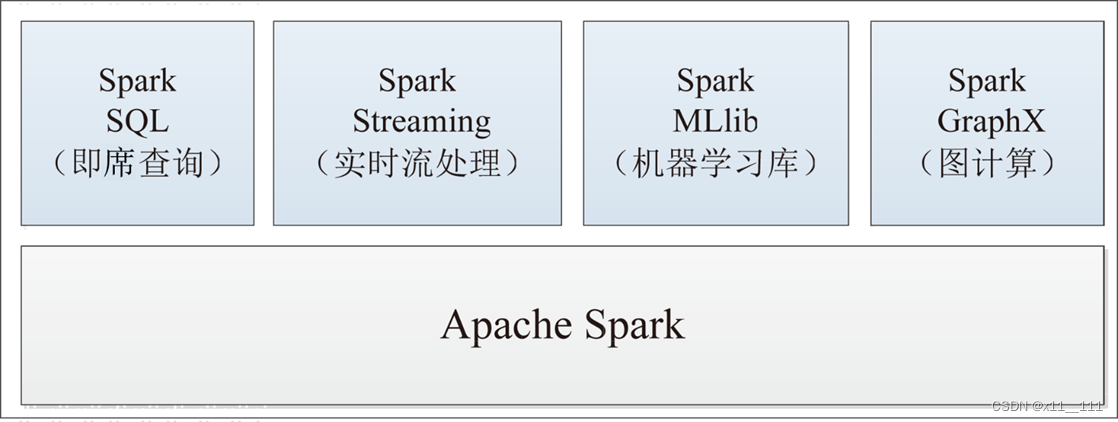
Spark提供了统一的解决方案。Spark可以用于,交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。减少了开发和维护的人力成本和部署平台的物力成本。
用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。
代码简洁:
spark支持使用Scala,python等语言编写代码。Scala和python的代码相对Java简洁,所以spark中一般都是用Scala和python编写应用程序。
三,认识spark的生态圈
Spark Core:Spark的核心,提供底层框架及核心支持。
BlinkDB:一个用于在海量数据上进行交互式SQL查询的大规模并行查询引擎,允许用户通过权衡数据精度缩短查询响应时间,数据的精度将被控制在允许的误差范围内。
Spark SQL:可以执行SQL查询,支持基本的SQL语法和HiveQL语法,可读取的数据源包括Hive、HDFS、关系数据库(如MySQL)等。
Spark Streaming:可以进行实时数据流式计算。
MLBase:是Spark生态圈的一部分,专注于机器学习领域,学习门槛较低。MLBase由4部分组成:MLlib、MLI、ML Optimizer和MLRuntime。
Spark GraphX:图计算的应用在很多情况下处理的数据量都是很庞大的。如果用户需要自行编写相关的图计算算法,并且在集群中应用,难度是非常大的。而使用GraphX即可解决这个问题,因为它内置了许多与图相关的算法,如在移动社交关系分析中可使用图计算相关算法进行处理和分析。
SparkR:AMPLab发布的一个R语言开发包,使得R语言编写的程序不只可以在单机运行,也可以作为Spark的作业运行在集群上,极大地提升了R语言的数据处理能力。

Scala
一,Scala的介绍
Scala是Scalable Language的缩写,是一种多范式的编程语言,由洛桑联邦理工学院的马丁·奥德斯在2001年基于Funnel的工作开始设计,设计初衷是想集成面向对象编程和函数式编程的各种特性。Scala 是一种纯粹的面向对象的语言,每个值都是对象。Scala也是一种函数式语言,因此函数可以当成值使用。由于Scala整合了面向对象编程和函数式编程的特性,因此Scala相对于Java、C#、C++等其他语言更加简洁。Scala源代码会被编译成Java字节码,因此Scala可以运行于Java虚拟机(Java Virtual Machine,JVM)之上,并可以调用现有的Java类库。
二,scala的特性
面向对象
Scala中的每个值都是一个对象,包括基本数据类型(即布尔值、数字等)在内,连函数也是对象。 类可以被子类化,而且Scala 还提供了基于 mixin 的组合( mixin-based composition )。
类抽象机制的扩展有两种途径:一种途径是子类继承,另一种途径是灵活的混入机制。这两种途径能避免多重继承 的种种问题。
函数式编程
Scala也是一种函数式语言,其函数也能当成值来使用。 Scala 提供了轻量级的语法用以定义匿名函数,支持高阶函数,允许嵌套多层函数,并支持柯里化。Scala 的 case class 及其内置的模式匹配相当于函数式编程语言中常用的代数类型。
更进一步,程序员可以利用Scala的模式匹配,编写类似正则表达式的代码处理XML 数据
静态类型
cala具备类型系统,通过编译时检查,保证代码的安全性和一致性。类型系统具体支持以下特性:1,泛型类 2,协变和逆变标注 3,类型参数的上下限约束 4,把类别和抽象类型作为对象成员 5,复合类型 6,引用自己时显式指定类型 7,视图 8,多态方法
可扩展
Scala的设计秉承一项事实,即在实践中,某个领域特定的应用程序开发往往需要特定于该领域的语言扩展。 Scala提供了许多独特的语言机制,可以以库的形式轻易无缝添加新的语言结构:
1,任何方法可用作前缀或后缀操作符 2,可以根据预期类型自动构造闭包。














 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









