






温馨提示:
以下介绍方法的测试代码,如果在JDK 8的环境下运行报错,说明该方法可能是JDK 11或JDK 17新增的。
目录
1、filter(Prredicate predicate)
3、mapToXxx(ToXxxFunction mapper)
2、sorted(Comparator comparator)编辑
2.2、toArray(IntFunction generator)[]>
8、anyMatch(Predicate predicate)
9、allMatch(Predicate predicate)
10、noneMatch(Predicate predicate)
6、isPresent(Consumer consumer)
12、orElseThrow(Supplier exceptionSupplier)
13、equals(Object obj)、hashCode()、toString()
一、Stream简介
Java 8新增了Stream、IntStream、LongStream、DoubleStream等流式API,这些API代表多个支持串行和并行聚集操作的元素。前面4个接口中,Stream是一个通用的流接口,而IntStream、LongStream、DoubleStream则代表元素类型为int、long、double的流。
Java 8还为上面的每个流式API 提供了对应的Builder,例如Stream.Builder、IntStream.Builder、LongStream.Builder、DoubleStream.Builder,并可以通过这些Builder来创建对应的流。
【温馨提示】:
以上内容摘抄于《疯狂Java讲义(第六版)》——李刚,第八章。如需了解Stream介绍详情,请阅读Java 8 API的官方文档。
(一)、顺序流(串行流)
顺序流(串行流)是指Stream依次处理数据,处理完一条数据在处理下一条数据,顺序流是默认处理方式,不会利用利用多核处理器的优势。
(二)、并行流
并行流是指stream会把数据拆分为多个部分,并由不同的处理器核心并行处理每个部分的数据。利用多核处理器的优势,通过并行执行操作来提高处理大量数据的性能。
(三)、创建stream
1、使用Stream.Builder创建流
代码如下所示:
Stream.Builder<UserInfo> builder = Stream.builder();
builder.add(new UserInfo(111111L, "张三",20,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0));
builder.add(new UserInfo(222222L, "李四",21,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2));
builder.add(new UserInfo(333333L, "王五",22,"男", LocalDate.of(2000, Month.SEPTEMBER, 7), 58.0, 168.6));
builder.add(new UserInfo(444444L, "赵六",23,"女", LocalDate.of(2002, Month.JUNE, 8), 50.0, 165.0));
builder.add(new UserInfo(555555L, "钱七",24,"男", LocalDate.of(2003, Month.JUNE, 6), 60.0, 169.5));
builder.add(new UserInfo(666666L, "孙八",25,"女", LocalDate.of(2008, Month.DECEMBER, 2), 51.0, 163.5));
builder.add(new UserInfo(777777L, "吴九",26,"男", LocalDate.of(1999, Month.DECEMBER, 5), 58.0, 169.7));
builder.add(new UserInfo(888888L, "周十",28,"女", LocalDate.of(1996, Month.DECEMBER, 9), 53.0, 162.8));
Stream<UserInfo> build = builder.build();2、将集合转换为流
代码如下所示:
// 使用java.util.Arrays工具类创建一个集合,并初始化数据
List<UserInfo> list = Arrays.asList(
new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0),
new UserInfo(222222L, "李四", 21, "女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2),
new UserInfo(333333L, "王五", 22, "男", LocalDate.of(2000, Month.SEPTEMBER, 7), 58.0, 168.6),
new UserInfo(444444L, "赵六", 23, "女", LocalDate.of(2002, Month.JUNE, 8), 50.0, 165.0),
new UserInfo(555555L, "钱七", 24, "男", LocalDate.of(2003, Month.JUNE, 6), 60.0, 169.5),
new UserInfo(666666L, "孙八", 25, "女", LocalDate.of(2008, Month.DECEMBER, 2), 51.0, 163.5),
new UserInfo(777777L, "吴九", 26, "男", LocalDate.of(1999, Month.DECEMBER, 5), 58.0, 169.7),
new UserInfo(888888L, "周十", 28, "女", LocalDate.of(1996, Month.DECEMBER, 9), 53.0, 162.8)
);
// 将集合转换为stream流
Stream<UserInfo> stream = list.stream();3、将数组转换为流
代码如下所示:
// 创建一个UserInfo数组,并初始化元素
UserInfo[] arr = {
new UserInfo(111111L, "张三",20,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0),
new UserInfo(222222L, "李四",21,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2),
new UserInfo(333333L, "王五",22,"男", LocalDate.of(2000, Month.SEPTEMBER, 7), 58.0, 168.6),
new UserInfo(444444L, "赵六",23,"女", LocalDate.of(2002, Month.JUNE, 8), 50.0, 165.0),
new UserInfo(555555L, "钱七",24,"男", LocalDate.of(2003, Month.JUNE, 6), 60.0, 169.5),
new UserInfo(666666L, "孙八",25,"女", LocalDate.of(2008, Month.DECEMBER, 2), 51.0, 163.5),
new UserInfo(777777L, "吴九",26,"男", LocalDate.of(1999, Month.DECEMBER, 5), 58.0, 169.7),
new UserInfo(888888L, "周十",28,"女", LocalDate.of(1996, Month.DECEMBER, 9), 53.0, 162.8)
};
// 将数组转换为Stream流
Stream<UserInfo> stream = Arrays.stream(arr);4、使用Stream.of创建流
使用Stream.of(T... values)的静态方法创建流,代码如下所示:
Stream<UserInfo> stream = Stream.of(
new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0),
new UserInfo(222222L, "李四", 21, "女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2),
new UserInfo(333333L, "王五", 22, "男", LocalDate.of(2000, Month.SEPTEMBER, 7), 58.0, 168.6),
new UserInfo(444444L, "赵六", 23, "女", LocalDate.of(2002, Month.JUNE, 8), 50.0, 165.0),
new UserInfo(555555L, "钱七", 24, "男", LocalDate.of(2003, Month.JUNE, 6), 60.0, 169.5),
new UserInfo(666666L, "孙八", 25, "女", LocalDate.of(2008, Month.DECEMBER, 2), 51.0, 163.5),
new UserInfo(777777L, "吴九", 26, "男", LocalDate.of(1999, Month.DECEMBER, 5), 58.0, 169.7),
new UserInfo(888888L, "周十", 28, "女", LocalDate.of(1996, Month.DECEMBER, 9), 53.0, 162.8)
);5、将集合创建为并行流
【注意事项】:
并行流适用于处理大量数据、复杂的计算或需要并行执行的操作。使用并行流时尽可能考虑线程安全性、线程调度、性能、数据分割、元素执行顺序等因素。
由于使用并行流时需要考虑的因素较多,考虑不完全时可能会影响执行效率,所以数据量较小或操作较简单时,优先考虑顺序流(串行流)。
代码如下所示:
// 使用java.util.Arrays工具类创建一个集合,并初始化数据
List<UserInfo> list = Arrays.asList(
new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0),
new UserInfo(222222L, "李四", 21, "女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2),
new UserInfo(333333L, "王五", 22, "男", LocalDate.of(2000, Month.SEPTEMBER, 7), 58.0, 168.6),
new UserInfo(444444L, "赵六", 23, "女", LocalDate.of(2002, Month.JUNE, 8), 50.0, 165.0),
new UserInfo(555555L, "钱七", 24, "男", LocalDate.of(2003, Month.JUNE, 6), 60.0, 169.5),
new UserInfo(666666L, "孙八", 25, "女", LocalDate.of(2008, Month.DECEMBER, 2), 51.0, 163.5),
new UserInfo(777777L, "吴九", 26, "男", LocalDate.of(1999, Month.DECEMBER, 5), 58.0, 169.7),
new UserInfo(888888L, "周十", 28, "女", LocalDate.of(1996, Month.DECEMBER, 9), 53.0, 162.8)
);
// 将集合创建为并行流
Stream<UserInfo> stream = list.parallelStream();(四)、创建测试对象及数据
创建一个UserInfo类,包括id(主键)、name(姓名)、age(年龄)、sex(性别)、birthday
(出生日期)、weight(体重)、height(身高)等属性。代码如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.Arrays;
import java.util.List;
public class UserInfo {
private Long id; // 主键
private String name; // 姓名
private Integer age; // 年龄
private String sex;//性别
private LocalDate birthday; // 出生日期
private Double weight; //体重
private Double height; // 身高
// 省略了Getter、Setter、toString等方法
public UserInfo(){}
public UserInfo(Long id, String name, Integer age, String sex,
LocalDate birthday, Double weight, Double height) {
this.id = id;
this.name = name;
this.age = age;
this.sex = sex;
this.birthday = birthday;
this.weight = weight;
this.height = height;
}
/**
* 模拟数据库查询得到的数据
* @return List<UserInfo>
*/
public static List<UserInfo> dataList(){
// 通过java.util.Arrays工具类创建一个List集合
return Arrays.asList(
new UserInfo(111111L, "张三",20,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0),
new UserInfo(222222L, "李四",21,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2),
new UserInfo(333333L, "王五",22,"男", LocalDate.of(2000, Month.SEPTEMBER, 7), 58.0, 168.6),
new UserInfo(444444L, "赵六",23,"女", LocalDate.of(2002, Month.JUNE, 8), 50.0, 165.0),
new UserInfo(555555L, "钱七",24,"男", LocalDate.of(2003, Month.JUNE, 6), 60.0, 169.5),
new UserInfo(666666L, "孙八",25,"女", LocalDate.of(2008, Month.DECEMBER, 2), 51.0, 163.5),
new UserInfo(777777L, "吴九",26,"男", LocalDate.of(1999, Month.DECEMBER, 5), 58.0, 169.7),
new UserInfo(888888L, "周十",28,"女", LocalDate.of(1996, Month.DECEMBER, 9), 53.0, 162.8)
);
}
/**
* 将数组转换为Stream流
* @return Stream<UserInfo>
*/
public static Stream<UserInfo> arrByStream(){
UserInfo[] arr = {
new UserInfo(111111L, "张三",23,"女", LocalDate.of(1998, Month.JANUARY, 1), 52.0, 165.8),
new UserInfo(222222L, "李四",21,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 169.8),
new UserInfo(333333L, "王五",24,"女", LocalDate.of(2000, Month.SEPTEMBER, 7), 53.0, 168.6),
new UserInfo(444444L, "赵六",23,"女", LocalDate.of(2002, Month.JUNE, 8), 50.0, 165.0),
new UserInfo(555555L, "钱七",24,"女", LocalDate.of(2003, Month.JUNE, 6), 60.0, 168.6),
new UserInfo(666666L, "孙八",26,"女", LocalDate.of(2008, Month.DECEMBER, 2), 51.0, 163.5),
new UserInfo(777777L, "吴九",26,"女", LocalDate.of(1999, Month.DECEMBER, 5), 48.0, 169.8),
new UserInfo(888888L, "周十",22,"女", LocalDate.of(1996, Month.DECEMBER, 9), 52.0, 165.8)
};
return Arrays.stream(arr);
}
}二、Stream API
Stream提供了大量的方法进行聚集操作,这些方法既可以是“中间的”(intermediate),也可以是”末端的“(terminal)。
中间方法:中间操作允许流保持打开状态,并允许直接额调用后续方法。上面程序中的map()方法就是中间方法。中间方法的返回值是另一个流。
末端方法:末端方法是对流的最终操作。当对某个Stream执行末端方法之后,该流将被“消耗”且不再可用。如:sum()、count()、average()等方法都是末端方法。
【提示】:
简单来说,所谓中间方法,就是指对流调用这些方法后,可继续调用其他方法;
所谓末端方法,就是指对该流调用这些方法后,不能在继续调用其他方法。
流的方法还有如下两个特征:
1、有状态的方法:这种方法会给流增加一些新的属性,比如元素的唯一性、元素的最大数据量、保证元素以排序的方式被处理等。有状态的方法往往需要更大的性能开销。
2、短路方法:短路方法可以尽早结束对流的操作,不必检查所有的元素。
【温馨提示】:
以上内容摘抄于《疯狂Java讲义(第六版)》——李刚,第八章。如需了解Stream介绍详情,请阅读Java 8 API的官方文档。
(一)、Stream常用的中间方法
1、filter(Prredicate predicate)
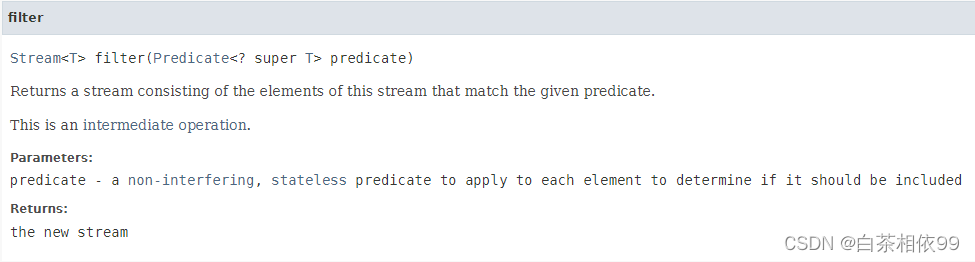
【Java 8 API文档——有道词典翻译】:
返回由该流中与给定谓词匹配的元素组成的流。这是一个中间操作。
参数:谓词——一个非干扰的、无状态的谓词,应用于每个元素,以确定它是否应该被包含
返回:新流
【《疯狂Java讲义(第六版)》——李刚,第八章】:
过滤Stream中所有不符合predicate的元素。
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
List<UserInfo> collect = list.stream().filter(obj -> obj.getAge() > 25).collect(Collectors.toList());
for (UserInfo userInfo : collect) {
System.out.println("过滤年龄大于25的数据:" + userInfo);
}
}
}以上代码运行结果,如下所示:

2、map(Function mapper)

【Java 8 API文档——有道词典翻译】:
返回由将给定函数应用于此流的元素的结果组成的流。这是一个中间操作。
类型参数:R -新流的元素类型参数:Mapper——一个非干扰的、无状态的函数,应用于每个元素
返回:新流
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
List<String> collect = list.stream().map(UserInfo::getName).collect(Collectors.toList());
System.out.println("获取集合中所有的名字:" + collect);
}
}以上代码运行结果,如下所示:

3、mapToXxx(ToXxxFunction mapper)
【《疯狂Java讲义(第六版)》——李刚,第八章】:
使用ToXxxFunction对流中的元素执行一对一的转换,该方法返回的新流中包含了ToXxxFunction转换生成的所有元素。
处理Int类型的数据:

【Java 8 API文档——有道词典翻译】:
返回一个IntStream,由将给定函数应用于此流的元素的结果组成。这是一个中间操作。
参数:Mapper——一个非干扰的、无状态的函数,应用于每个元素
返回:新流
测试代码,如下所示:
import java.util.*;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
int sum = list.stream().mapToInt(UserInfo::getAge).sum();
System.out.println("求所有年龄的总和:" + sum);
}
}以上代码运行结果,如下所示:

处理long类型的数据:
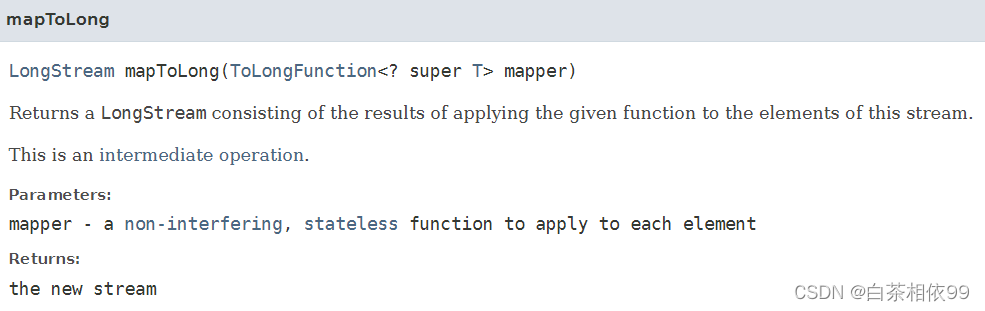
【Java 8 API文档——有道词典翻译】:
返回一个由将给定函数应用于此流元素的结果组成的DoubleStream。这是一个中间操作。
参数:mapper——一个非干扰的、无状态的函数,应用于每个元素
返回:新流
测试代码,如下所示:(此处是将Integer类型转换为Long类型进行求和)
import java.util.*;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
long sum = list.stream().mapToLong(UserInfo::getAge).sum();
System.out.println("求所有年龄的总和:" + sum);
}
}以上代码运行结果,如下所示:

处理double类型的数据:

【Java 8 API文档——有道词典翻译】:
返回一个由将给定函数应用于此流元素的结果组成的DoubleStream。这是一个中间操作。
参数:Mapper——一个非干扰的、无状态的函数,应用于每个元素
返回:新流
测试代码,如下所示:
import java.util.*;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
double sum = list.stream().mapToDouble(UserInfo::getHeight).sum();
System.out.println("求所有身高的总和:" + sum);
}
}以上代码运行结果,如下所示:

4、peek(Consumer action)

【Java 8 API文档——有道词典翻译】:
返回由此流的元素组成的流,并在从结果流中消费元素时对每个元素执行所提供的操作。这是一个中间操作。对于并行流管道,该操作可以在任何时间、在任何线程中被上游操作提供元素。如果操作修改共享状态,它负责提供所需的同步。
API 说明:
该方法的存在主要是为了支持调试,在调试中,当您希望看到元素流过管道中的某个点时:
Stream.of("one", "two", "three", "four") // 过滤字符串长度为3的元素 .filter(e -> e.length() > 3) .peek(e -> System.out.println("Filtered value: " + e)) // 将过滤得到的字符串转换为大写 .map(String::toUpperCase) .peek(e -> System.out.println("Mapped value: " + e)) // 一个收集器,它将所有输入元素按相应顺序收集到List集合中返回 .collect(Collectors.toList());运行API文档中的说明代码,结果如下所示:
参数:Action——当元素从流中被消费时对其执行的非干扰操作
返回:新流
【《疯狂Java讲义(第六版)》——李刚,第八章】:
依次对每个元素执行一些操作,该方法返回的流与原有流包含相同的元素,该方法主要用于调试。

测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
List<Double> collect = list.stream()
// 过滤身高大于168.0的数据
.filter(e -> e.getHeight() > 168.0)
// 控制台查看过滤的结果
.peek(System.out::println)
// 获取过滤数据中的身高
.map(UserInfo::getHeight)
// 控制台查看获取的结果
.peek(System.out::println)
// 一个收集器,它将所有输入元素按相应顺序收集到List集合中返回
.collect(Collectors.toList());
}
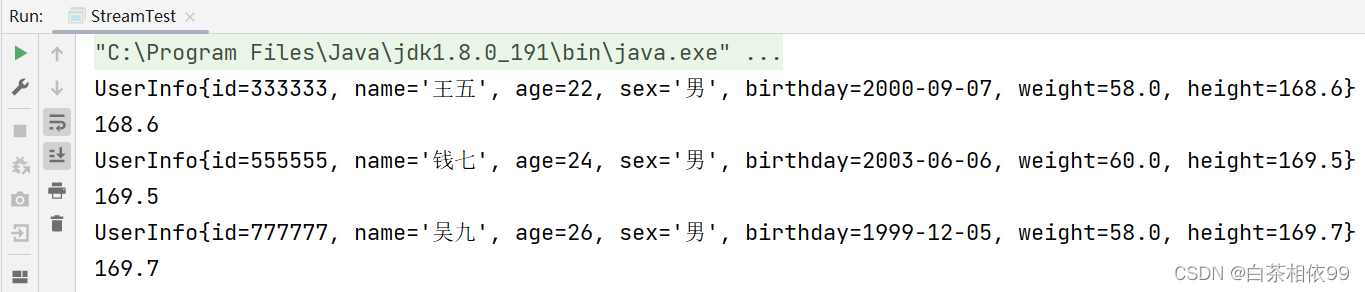
}以上代码运行结果,如下所示:
5、distinct()
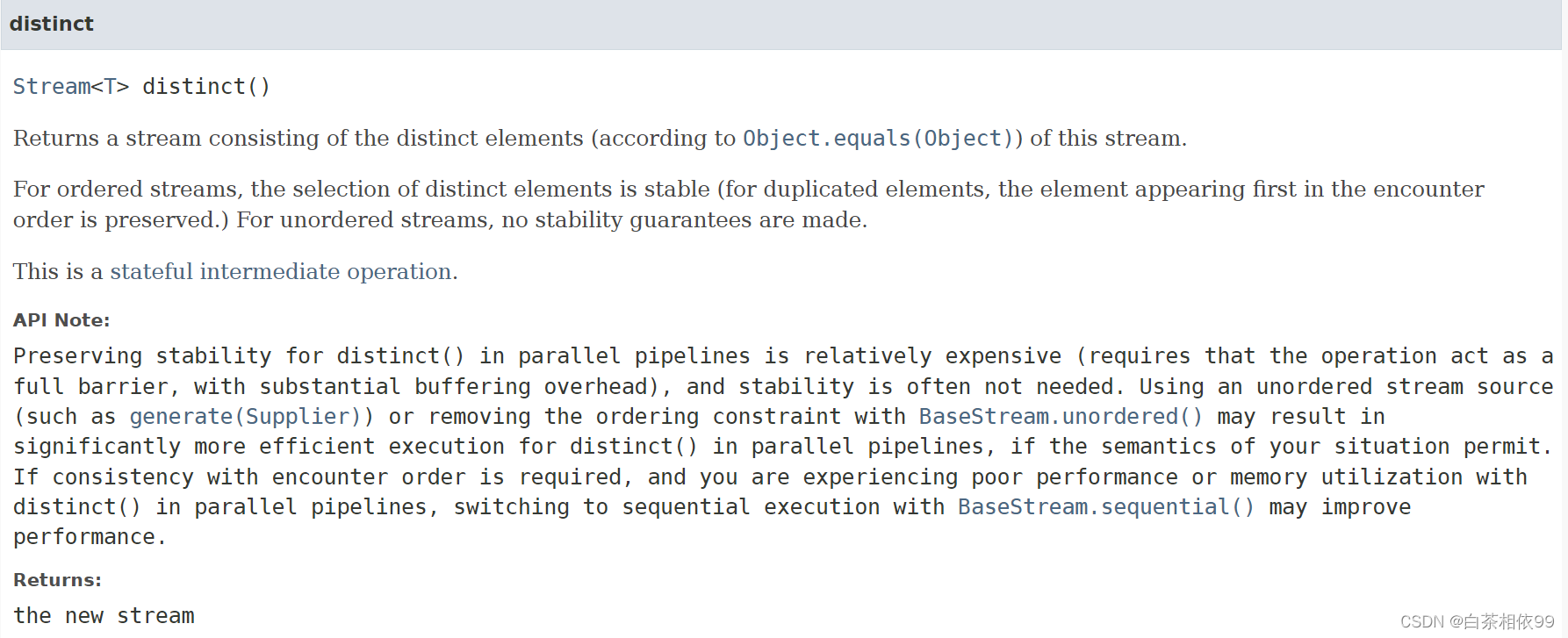
【Java 8 API文档——有道词典翻译】:
返回一个由不同元素组成的流(根据Object.equals (Object))。
对于有序流,不同元素的选择是稳定的(对于重复元素,保留在遇到顺序中最先出现的元素)。对于无序流,不做稳定性保证。
这是一个有状态的中间操作。
API 说明:
在并行管道中保持distinct()的稳定性是相对昂贵的(需要操作作为一个完整的屏障,有大量的缓冲开销),并且稳定性通常是不需要的。如果您的情况语义允许,使用无序流源(例如generate(Supplier))或使用BaseStream.unordered()删除排序约束可能会显著提高并行管道中distinct()的执行效率。如果需要与相遇顺序保持一致,并且您在并行管道中使用distinct()遇到性能差或内存利用率低的问题,则切换到使用BaseStream.sequential()进行顺序执行可能会提高性能。返回:新流
【《疯狂Java讲义(第六版)》——李刚,第八章】:
该方法用于排序流中所有重复的元素(判断元素重复的标准是使用equals()比较,返回true)。这是一个有状态的方法。
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
List<String> collect = list.stream().map(UserInfo::getSex).collect(Collectors.toList());
System.out.println("获取所有的性别:" + collect);
List<String> dis = collect.stream().distinct().collect(Collectors.toList());
System.out.println("去重后的性别:" + dis);
}
}以上代码运行结果,如下所示:

6、排序
1、sorted()

【Java 8 API文档——有道词典翻译】:
返回由此流的元素组成的流,按自然顺序排序。如果此流的元素不具有可比性,则java.lang.ClassCastException可能在终端操作执行时抛出。对于有序流,排序是稳定的。对于无序流,没有稳定性保证。这是一个有状态的中间操作。
返回:新流
【《疯狂Java讲义(第六版)》——李刚,第八章】:
该方法用于保证对该流的后续访问中最大允许访问的元素个数。这是一个有状态的、短路方法。
1、需求:对集合中的对象的属(年龄)进行升序排列
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.arrByStream().collect(Collectors.toList());
// 对年龄进行升序排列
List<Integer> collect = list.stream().map(UserInfo::getAge).sorted().collect(Collectors.toList());
System.out.println("对年龄进行升序排列:" + collect);
}
}以上代码运行结果,如下所示:

2、需求:对集合中的对象的属性(年龄)进行降序排列
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.arrByStream().collect(Collectors.toList());
// 对年龄进行降序排列
List<Integer> collect = list.stream().sorted(Comparator.comparing(UserInfo::getAge).reversed()).map(UserInfo::getAge).collect(Collectors.toList());
System.out.println("对年龄进行降序排列:" + collect);
}
}以上代码运行结果,如下所示:
2、sorted(Comparator comparator)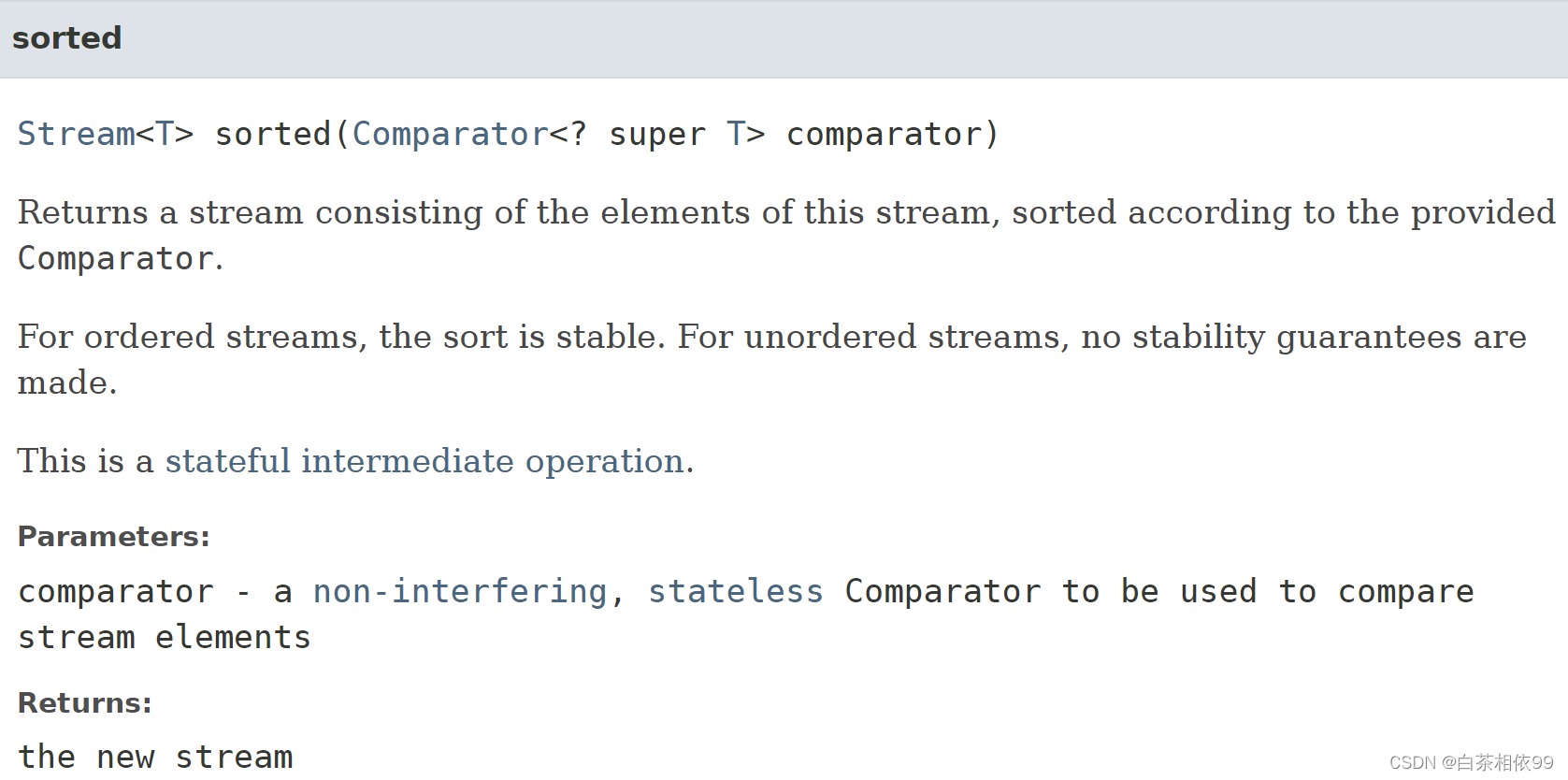
【Java 8 API文档——有道词典翻译】:
返回由此流的元素组成的流,并根据提供的比较器进行排序。对于有序流,排序是稳定的。对于无序流,没有稳定性保证。这是一个有状态的中间操作。
参数:comparator——一个非干扰的、无状态的比较器,用于比较流元素
返回:新流
【《疯狂Java讲义(第六版)》——李刚,第八章】:
该方法用于保证对该流的后续访问中最大允许访问的元素个数。这是一个有状态的、短路方法。
2.1、自然排序
自然排序:是指根据字母顺序或者数字顺序等自然的顺序进行排序。
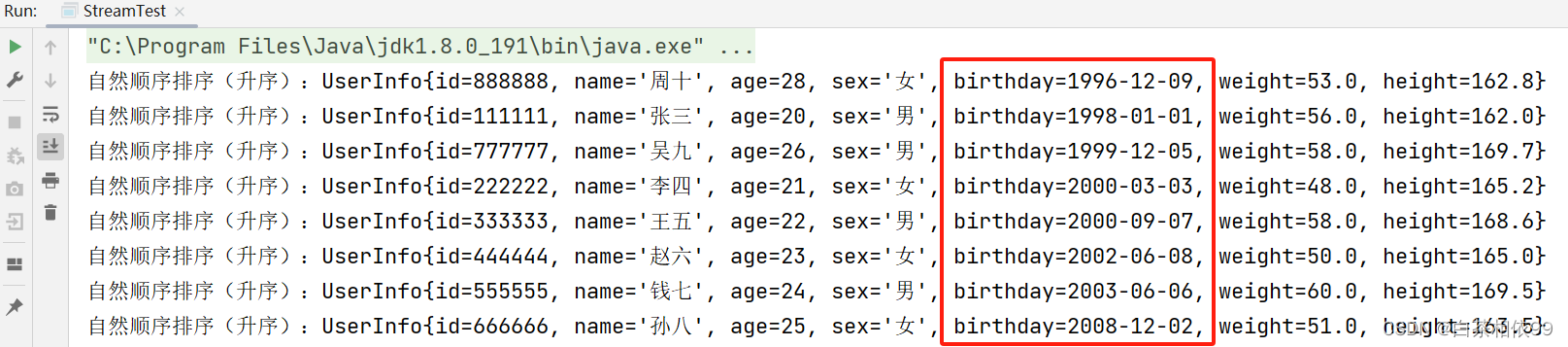
1、需求:根据对象的单个属性(出生日期)自然排序【默认升序排列】
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
// 按照出生日期升序排序【自然排序默认排序(升序)】
List<UserInfo> collect = list.stream().sorted(Comparator.comparing(UserInfo::getBirthday)).collect(Collectors.toList());
for (UserInfo userInfo : collect) {
System.out.println("自然顺序排序(升序):" + userInfo);
}
}
}以上代码运行结果,如下所示:
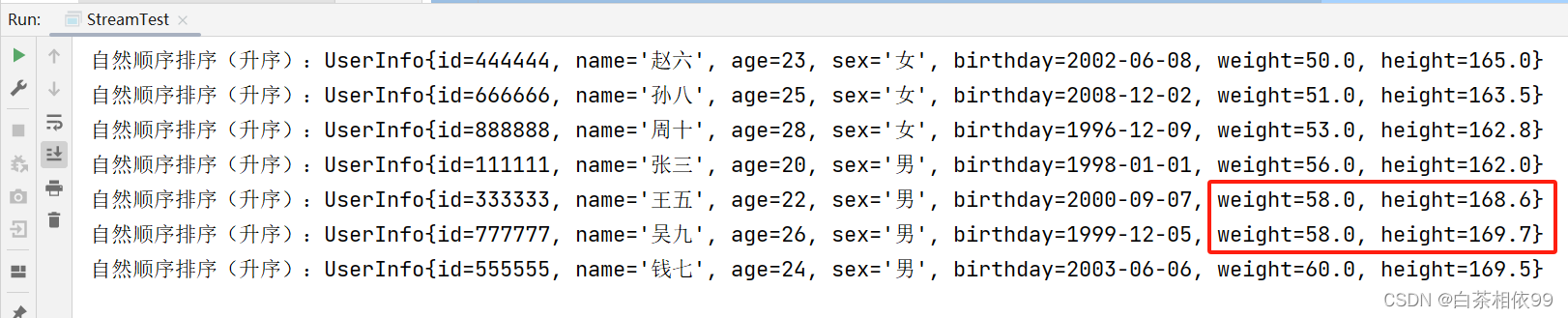
2、需求:根据对象的多个属性(体重、身高)自然排序【默认升序排列】
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
// 先按照体重升序排列,体重相同时在按照身高升序排序【自然排序默认排序(升序)】
List<UserInfo> collect = list.stream().sorted(Comparator.comparing(UserInfo::getWeight).thenComparing(UserInfo::getHeight)).collect(Collectors.toList());
for (UserInfo userInfo : collect) {
System.out.println("自然顺序排序(升序):" + userInfo);
}
}
}以上代码运行结果,如下所示:
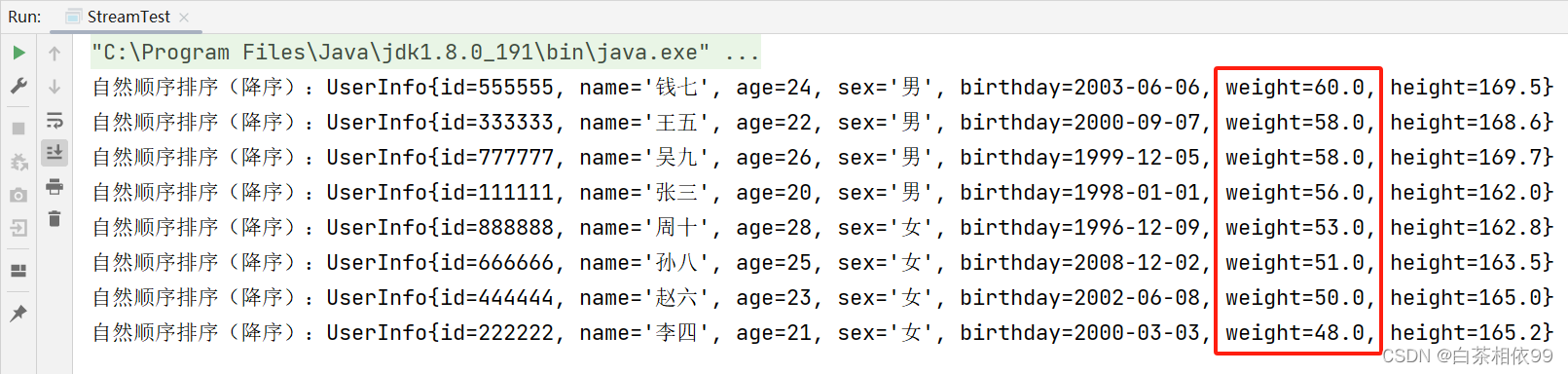
3、需求:根据对象的单个属性(体重)自然排序【降序排列】
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
// 按照体重降序排列
List<UserInfo> collect = list.stream().sorted(Comparator.comparing(UserInfo::getWeight).reversed()).collect(Collectors.toList());
for (UserInfo userInfo : collect) {
System.out.println("自然顺序排序(降序):" + userInfo);
}
}
}
以上代码运行结果,如下所示:
4、需求:根据对象的多个属性(体重、身高)自然排序【降序排列】
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
// 先按照体重降序排列,体重相同时在按照身高降序排序【自然排序(降序)】
List<UserInfo> collect = list.stream().sorted(Comparator.comparing(UserInfo::getWeight).thenComparing(UserInfo::getHeight).reversed()).collect(Collectors.toList());
for (UserInfo userInfo : collect) {
System.out.println("自然顺序排序(降序):" + userInfo);
}
}
}以上代码运行结果,如下所示:

2.2、定制排序
定制排序:是指根据自己定义的排序规则进行排序。
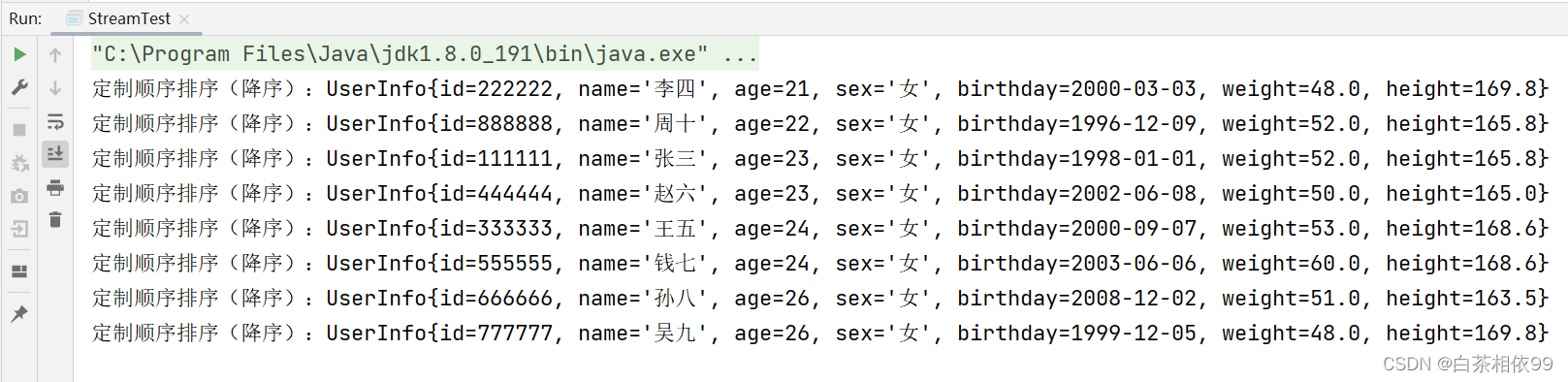
需求:先根据身高降序,身高相同时根据体重升序,体重相同时根据年龄升序
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.arrByStream().collect(Collectors.toList());
// 先根据身高降序,身高相同时根据体重升序,体重相同时根据年龄升序排列【定制排序】
List<UserInfo> collect = list.stream().sorted((indexList1, indexList2) -> {
if (indexList1.getHeight() == indexList2.getHeight()) {
// 正序(升序)排列
// return indexList1.getHeight().compareTo(indexList2.getHeight());
// 倒叙(降序)排列
return indexList2.getHeight().compareTo(indexList1.getHeight());
} else if (indexList1.getWeight() == indexList2.getWeight()){
// 正序(升序)排列
// return indexList1.getWeight().compareTo(indexList2.getWeight());
// 倒叙(降序)排列
return indexList2.getWeight().compareTo(indexList1.getWeight());
} else {
// 正序(升序)排列
return indexList1.getAge().compareTo(indexList2.getAge());
// 倒叙(降序)排列
// return indexList2.getAge().compareTo(indexList1.getAge());
}
}).collect(Collectors.toList());
for (UserInfo userInfo : collect) {
System.out.println("定制顺序排序(降序):" + userInfo);
}
}
}以上代码运行结果,如下所示:
7、limit(long maxSize)
【Java 8 API文档——有道词典翻译】:
返回由此流的元素组成的流,截断为长度不超过maxSize。这是一个短路的有状态中间操作。API 说明:虽然limit()在顺序流管道上通常是一种便宜的操作,但对于有序的并行管道来说,它可能非常昂贵,特别是对于maxSize的大值,因为limit(n)被限制为不仅返回任意n个元素,而且返回相遇顺序中的前n个元素。如果您的情况语义允许,使用无序流源(例如generate(Supplier))或使用BaseStream unordered()删除排序约束可能会显著提高并行管道中的limit()的速度。如果需要与偶遇顺序保持一致,并且在并行管道中使用limit()遇到性能差或内存利用率低的问题,那么使用BaseStream sequential()切换到顺序执行可能会提高性能。
参数:maxSize—流应该限制的元素数量
返回:新流抛出:IllegalArgumentException -如果maxSize为负
【《疯狂Java讲义(第六版)》——李刚,第八章】:
该方法用于保证对该流的后续访问中最大允许访问的元素个数。这是一个有状态的、短路方法。
在6、排序中2.2、定制排序时,我们排列出了身高最高,体重最轻,年龄最小的女性。此时我们增加需求:取出前三个身高最高,体重最轻,年龄最小的女性。
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.arrByStream().collect(Collectors.toList());
// 先根据身高降序,身高相同时根据体重升序,体重相同时根据年龄升序排列【定制排序】
List<UserInfo> collect = list.stream().sorted((indexList1, indexList2) -> {
if (indexList1.getHeight() == indexList2.getHeight()) {
// 正序(升序)排列
// return indexList1.getHeight().compareTo(indexList2.getHeight());
// 倒叙(降序)排列
return indexList2.getHeight().compareTo(indexList1.getHeight());
} else if (indexList1.getWeight() == indexList2.getWeight()){
// 正序(升序)排列
// return indexList1.getWeight().compareTo(indexList2.getWeight());
// 倒叙(降序)排列
return indexList2.getWeight().compareTo(indexList1.getWeight());
} else {
// 正序(升序)排列
return indexList1.getAge().compareTo(indexList2.getAge());
// 倒叙(降序)排列
// return indexList2.getAge().compareTo(indexList1.getAge());
}
}).collect(Collectors.toList());
// 新增需求:取出前三个身高最高,体重最轻,年龄最小的女性
List<UserInfo> limit = collect.stream().limit(3).collect(Collectors.toList());
for (UserInfo userInfo : limit) {
System.out.println("定制顺序排序(降序):" + userInfo);
}
}
}以上代码运行结果,如下所示:

(二)、Shteam常用的末端方法
1、forEach(Consumer action)
【Java 8 API文档——有道词典翻译】:
对该流的每个元素执行一个操作。这是一个终端操作。这个操作的行为是明确的不确定的。对于并行流管道,此操作不能保证尊重流的相遇顺序,因为这样做会牺牲并行性的好处。对于任何给定的元素,该操作可以在库选择的任何时间和线程中执行。如果动作访问共享状态,它负责提供所需的同步。
参数:action-在元素上执行的非干扰动作
【《疯狂Java讲义(第六版)》——李刚,第八章】:
遍历流中所有元素,对每个元素执行action。
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
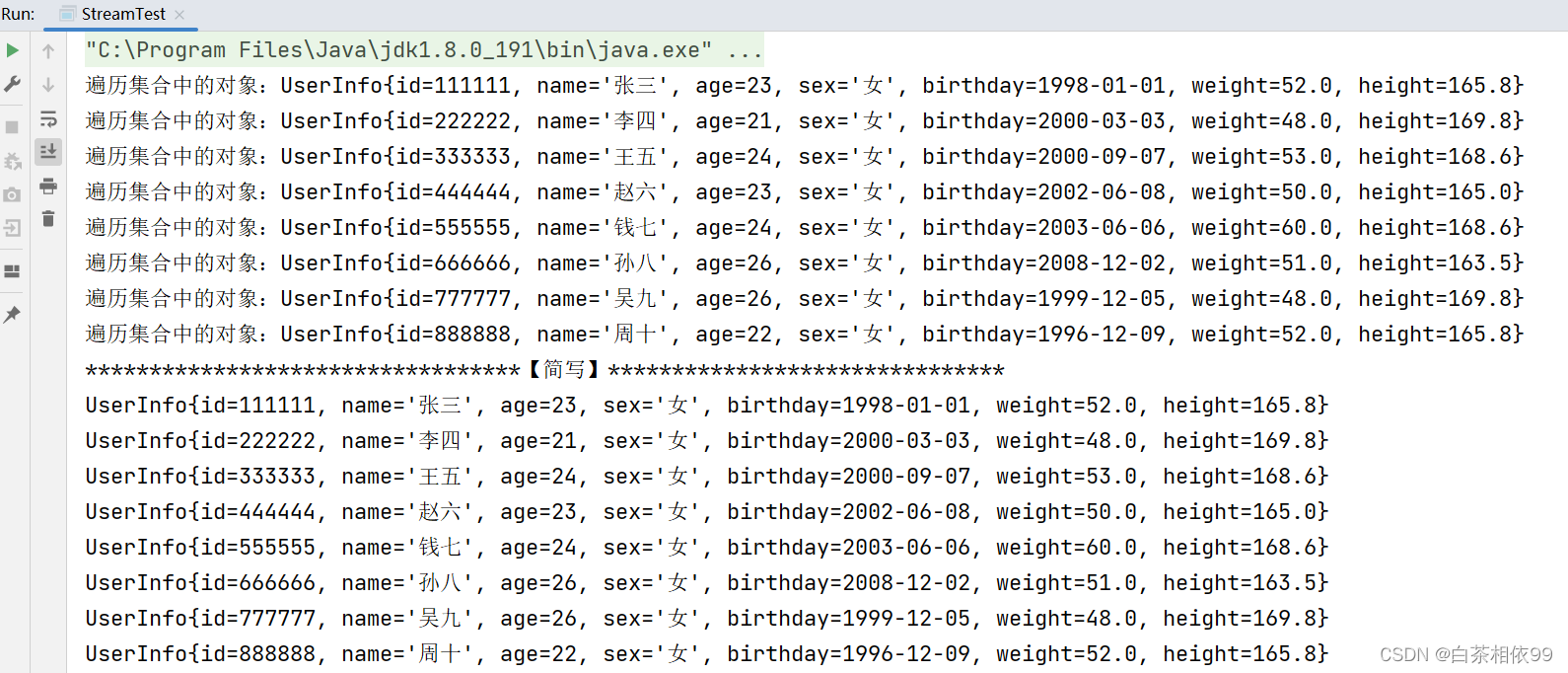
List<UserInfo> list = UserInfo.arrByStream().collect(Collectors.toList());
// 剪头函数写法
list.stream().forEach(e -> {
System.out.println("遍历集合中的对象:" + e);
});
System.out.println("**********************************【简写】*******************************");
// 简写
list.stream().forEach(System.out::println);
}
}以上代码运行结果,如下所示:
2、toArray()
2.1、toArray()

【Java 8 API文档——有道词典翻译】:
返回包含此流元素的数组。这是一个终端操作。
返回:包含此流元素的数组
【《疯狂Java讲义(第六版)》——李刚,第八章】:
将流中所有元素转换为一个数组。
测试代码,如下所示:
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.arrByStream().collect(Collectors.toList());
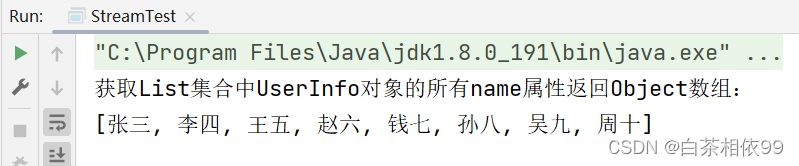
Object[] arrObj = list.stream().map(UserInfo::getName).toArray();
System.out.println("获取List集合中UserInfo对象的所有name属性返回Object数组:\n" + Arrays.toString(arrObj));
}
}
以上代码运行结果,如下所示:
2.2、toArray(IntFunction<A[]> generator)
【Java 8 API文档——有道词典翻译】:
使用提供的生成器函数来分配返回的数组,以及分区执行或调整大小可能需要的任何其他数组,返回包含此流元素的数组。这是一个终端操作。
API 说明:
生成器函数接受一个整数,即期望数组的大小,并生成一个期望大小的数组。这可以用一个数组构造函数引用来简洁地表达:
Person[] men = people.stream() .filter(p -> p.getGender() == MALE) .toArray(Person[]::new);类型参数:A——结果数组的元素类型
参数:generator——一个生成所需类型和提供长度的新数组的函数
返回:包含此流中的元素的数组
异常:ArrayStoreException——如果从数组生成器返回的数组的运行时类型不是此流中每个元素的运行时类型的超类型
【《疯狂Java讲义(第六版)》——李刚,第八章】:
将流中所有元素转换为一个数组。
测试代码,如下所示:
import java.util.Arrays;
import java.util.List;
import java.util.function.IntFunction;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.arrByStream().collect(Collectors.toList());
// String[] arrStr = list.stream().map(UserInfo::getName).toArray(new IntFunction<String[]>() {
// @Override
// public String[] apply(int value) {
// return new String[value];
// }
// });
// 以上代码简写形式,如下一行所示:
String[] arrStr = list.stream().map(UserInfo::getName).toArray(value -> new String[value]);
System.out.println("获取List集合中UserInfo对象的所有name属性返回String数组:\n" + Arrays.toString(arrStr));
UserInfo[] userInfoList = list.stream()
// 过滤list中年龄为26的UserInfo对象
.filter(p -> p.getAge() == 26)
// 添加到UserInfo[]数组中
.toArray(UserInfo[]::new);
System.out.println("获取List集合中年龄等于26的UserInfo对象放入UserInfo数组中:\n" + Arrays.toString(userInfoList));
System.out.println("************************【遍历UserInfo数组】****************************");
for (UserInfo userInfo : userInfoList) {
System.out.println("UserInfo对象:" + userInfo);
}
}
}
以上代码运行结果,如下所示:

3、toList()
【注意】:这是Java 17正式新增的一个方法。

【Java 8 API文档——有道词典翻译】:
将此流的元素累加到List中。列表中的元素将按照该流的相遇顺序排列,如果存在的话。返回的List是不可修改的;调用任何mutator方法总是会导致抛出UnsupportedOperationException。对返回的List的实现类型或可序列化性没有保证。返回实例可以是基于值的。调用者不应该对返回实例的身份做任何假设。对这些实例进行身份敏感的操作(引用相等(==)、身份哈希码和同步)是不可靠的,应该避免。这是一种终端操作。
API 说明:
如果需要对返回的对象进行更多的控制,请使用collector。toCollection(供应商)。实施要求:这个接口中的实现返回一个List,就好像是由以下代码产生的:
Collections.unmodifiableList(new ArrayList<>(Arrays.asList(this.toArray())))实现注意:
Stream的大多数实例将覆盖此方法,并提供与此接口中的实现相比高度优化的实现。
返回:包含流元素的List
【《疯狂Java讲义(第六版)》——李刚,第八章】:
将流中所有元素抓换为一个List集合,这是Java 17正式新增的一个方法。
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.arrByStream().collect(Collectors.toList());
List<String> nameList = list.stream().map(UserInfo::getName).toList();
System.out.println("获取list集合中所有的名字:" + nameList);
}
}
以上代码运行(以上代码运行需要JDK 17的运行环境)结果,如下所示:

4、reduce()
【Java 8 API文档——有道词典翻译】:
使用关联累加函数对该流的元素执行约简操作,并返回一个描述约简值的Optional(如果有的话)。这相当于:
boolean foundAny = false; T result = null; for (T element : this stream) { if (!foundAny) { foundAny = true; result = element; } else result = accumulator.apply(result, element); } return foundAny ? Optional.of(result) : Optional.empty();但不受顺序执行的约束。累加器函数必须是一个关联函数。这是一个终端操作。
参数:累加器——用于组合两个值的关联的、非干扰的、无状态的函数
返回:选择描述还原的结果
异常:NullPointerException——如果缩减的结果为null
参见:reduce(Object, BinaryOperator), min(Comparator), max(Comparator)
【《疯狂Java讲义(第六版)》——李刚,第八章】:
该方法有三个重载的版本,都用于通过某种操作来合并流中的元素。
测试代码,如下所示:
import java.util.List;
import java.util.function.BinaryOperator;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Integer total = list.stream().map(UserInfo::getAge).reduce(new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer val1, Integer val2) {
System.out.println("val1的值为:" + val1 + ", " + "val2的值为:" + val2 + ",返回值为:" + (val1 + val2));
return val1 + val2;
}
}).get();
System.out.println("total的值为:" + total);
// 以上函数式接口的简写形式如下所示:
Integer sum = list.stream().map(UserInfo::getAge).reduce((val1, val2) -> val1 + val2).get();
System.out.println("简写形式sum的值为:" + sum);
}
}以上代码运行结果,如下所示:

通过以上运行结果可看出,函数式接口的第一个参数第一次是集合的第一个元素,第二次以后就是第一次处理之后返回的结果。

【Java 8 API文档——有道词典翻译】:
使用提供的标识值和关联累加函数对该流的元素执行约简,并返回约简后的值。这相当于:
T result = identity; for (T element : this stream) result = accumulator.apply(result, element) return result;但不受顺序执行的约束。恒等值必须是累加器函数的恒等。这意味着对于所有的t,累加器。apply(identity, t)等于t,累加器函数必须是关联函数。这是一个终端操作。
API 说明:Sum、min、max、average和字符串连接都是简化的特殊情况。对一串数字求和可以表示为:
Integer sum = integers.reduce(0, (a, b) -> a+b);或者:
Integer sum = integers.reduce(0, Integer::sum);虽然与在循环中简单地改变运行总数相比,这似乎是一种更迂回的执行聚合的方式,但reduce操作的并行化更优雅,不需要额外的同步,并且大大降低了数据竞争的风险。
参数:恒等-累加函数的恒等值累加器——用于组合两个值的关联的、非干扰的、无状态的函数返回:还原的结果
【《疯狂Java讲义(第六版)》——李刚,第八章】:
该方法有三个重载的版本,都用于通过某种操作来合并流中的元素。
测试代码,如下所示:
import java.util.List;
import java.util.function.BinaryOperator;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Integer total = list.stream().map(UserInfo::getAge).reduce(9, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer val1, Integer val2) {
System.out.println("val1的值为:" + val1 + ", " + "val2的值为:" + val2 + ",返回值为:" + (val1 + val2));
return val1 + val2;
}
}).intValue();
System.out.println("total的值为:" + total);
// 以上函数式接口的简写形式如下所示:
Integer sum = list.stream().map(UserInfo::getAge).reduce(9,(val1, val2) -> val1 + val2).intValue();
// Integer sum = list.stream().map(UserInfo::getAge).reduce(9,Integer::sum).intValue();
System.out.println("简写形式sum的值为:" + sum);
}
}以上代码运行结果,如下所示:

通过以上运行结果可看出,函数式接口第一次的第一个参数是手动指定的数值(9),第二个参数是集合的第一个元素。第二次的第一个参数变为第一次执行完成后返回的结果,第二个参数是list集合中的元素以此类推。
【Java 8 API文档——有道词典翻译】:
使用所提供的恒等、累积和组合功能,对该流的元素进行约简。这相当于:
U result = identity; for (T element : this stream) result = accumulator.apply(result, element) return result;但不受顺序执行的约束。恒等值必须是组合函数的恒等。这意味着对于所有u, combiner(identity, u)等于u,另外,组合函数必须与累加器函数兼容;对于所有u和t,下列条件必须成立:
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)这是一个终端操作。
API 说明:使用这种形式的许多约简可以通过map和reduce操作的显式组合来更简单地表示。累加器函数作为一个融合的映射器和累加器,这有时比单独的映射和约简更有效,比如当知道之前的约简值可以让你避免一些计算。
类型参数:U -结果的类型
参数:
Identity——组合函数的单位值
accumulator——一个关联的、非干扰的、无状态的函数,用于将一个额外的元素合并到结果中
combiner——用于组合两个值的关联的、非干扰的、无状态的函数,它必须与累加器函数兼容
返回:还原的结果
参见:reduce(BinaryOperator), reduce(Object, BinaryOperator)
【《疯狂Java讲义(第六版)》——李刚,第八章】:
该方法有三个重载的版本,都用于通过某种操作来合并流中的元素。
测试代码,如下所示:
import java.util.List;
import java.util.function.BiFunction;
import java.util.function.BinaryOperator;
public class StreamTest {
public static void main(String[] args) {
int a = 10;
List<UserInfo> list = UserInfo.dataList();
Integer reduce = list.stream().map(UserInfo::getAge).parallel().reduce(0, new BiFunction<Integer, Integer, Integer>() {
@Override
public Integer apply(Integer val1, Integer val2) {
System.out.println("BiFunction中val1的值为:" + val1 + ",val2的值为:" + val2 + ",返回的值为:" + (val1 + val2));
return val1 + val2;
}
}, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer val1, Integer val2) {
System.out.println("【BinaryOperator】中val1的值为:" + val1 + ",val2的值为:" + val2 + ",返回的值为:" + (val1 + val2));
return val1 + val2;
}
});
// 以上代码的简写形式,如下所示:
// Integer reduce = list.stream().map(UserInfo::getAge).parallel().reduce(0, (val1, val2) -> val1 + val2, (val1, val2) -> val1 + val2);
// Integer reduce = list.stream().map(UserInfo::getAge).parallel().reduce(0, Integer::sum, Integer::sum);
System.out.println(reduce);
}
}以上代码运行结果,如下所示:
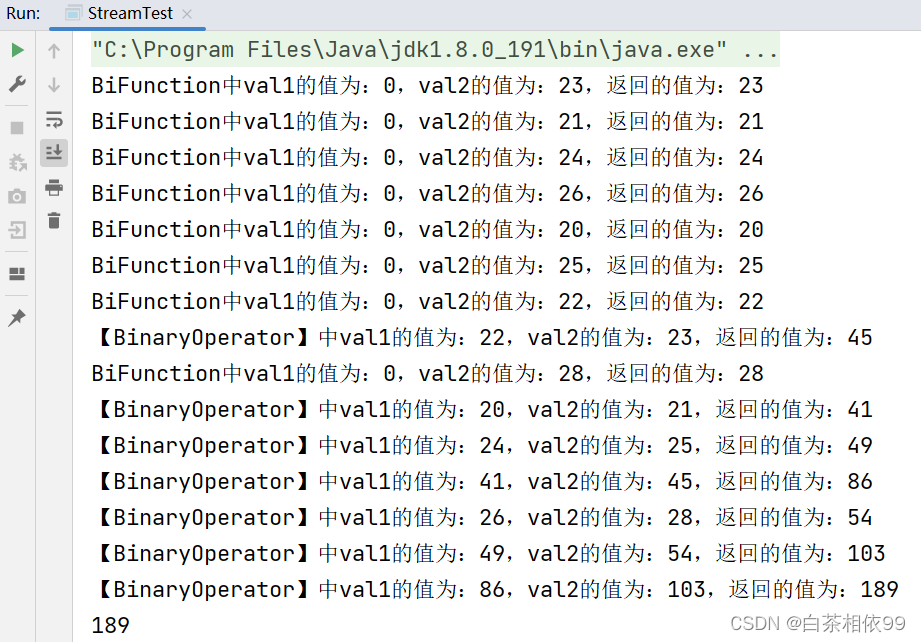
通过以上运行结果可看出,函数式接口第一次的第一个参数是手动指定的数值(9),第二个参数是集合的第一个元素。第二次的第一个参数变为第一次执行完成后返回的结果,第二个参数是list集合中的元素以此类推。
【案例演示】
实际开发中,我们可能需要对数据库查询出来的数据进行进一步封装,在返回前端。下面举个简单的例子,仅供大家参考,实际开发中可自由发挥。需求:将UserInfo对象的基本信息查询出来的结果,将名字、年龄返回前端,并且要求年龄全部除以2在返回前端,也可用reduce()方法实现。
实现代码,如下所示:
import java.util.ArrayList;
import java.util.List;
import java.util.function.BiFunction;
import java.util.function.BinaryOperator;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 建议:不要开启并行(.stream().parallel().reduce()),否则组装的数据可能不对。
ArrayList<UserVo> reduce = list.stream().reduce(new ArrayList<UserVo>(), new BiFunction<ArrayList<UserVo>, UserInfo, ArrayList<UserVo>>() {
@Override
public ArrayList<UserVo> apply(ArrayList<UserVo> userVos, UserInfo userInfo) {
UserVo userVo = new UserVo();
userVo.setName(userInfo.getName());
userVo.setValue(userInfo.getAge() / 2);
userVos.add(userVo);
return userVos;
}
}, new BinaryOperator<ArrayList<UserVo>>() {
@Override
public ArrayList<UserVo> apply(ArrayList<UserVo> userVos, ArrayList<UserVo> userVos2) {
return null;
}
});
// 以上代码简写形式,如下所示:
// ArrayList<UserVo> reduce = list.stream().reduce(new ArrayList<UserVo>(), (userVos, userInfo) -> {
// UserVo userVo = new UserVo();
// userVo.setName(userInfo.getName());
// userVo.setAge(userInfo.getAge() / 2);
// userVos.add(userVo);
// return userVos;
// }, (userVos, userInfo) -> null);
for (UserVo userVo : reduce) {
System.out.println("封装的vo数据为:" + userVo);
}
}
static class UserVo {
private String name; // 姓名
private Integer value; // 假设这个属性的值需要年龄除以2才可以。
// 此处省略了本对象的getter、setter、toString方法。
}
}以上代码运行结果,如下所示:

5、min()
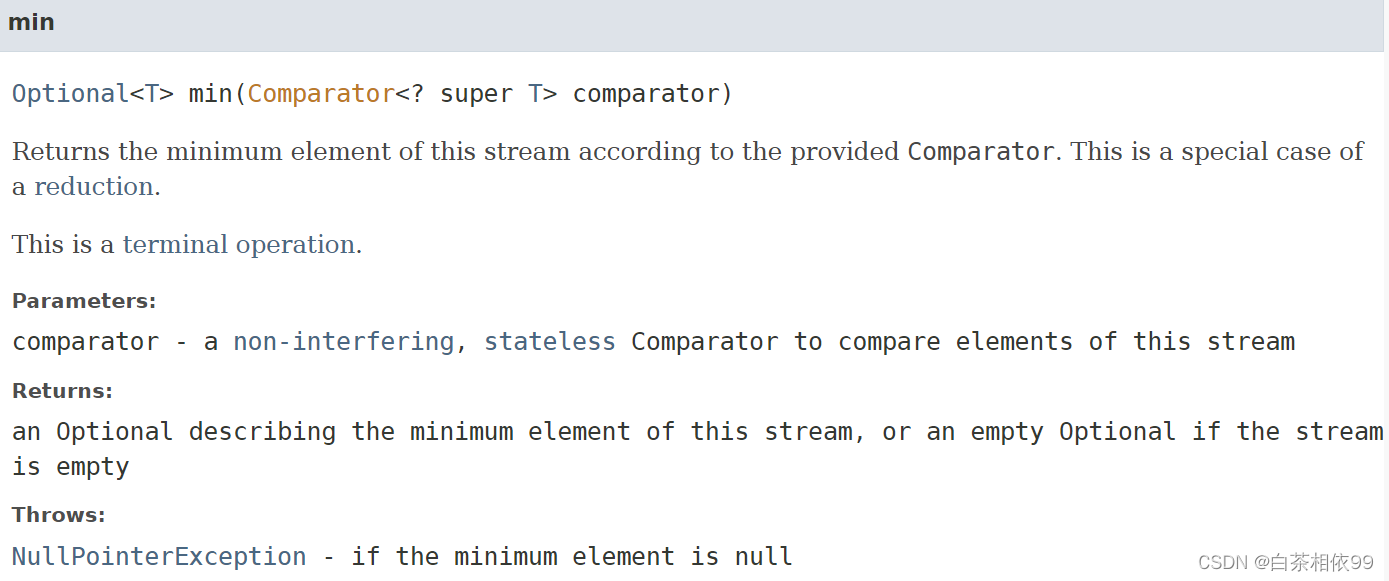
【Java 8 API文档——有道词典翻译】:
根据提供的比较器返回此流的最小元素。这是一个缩减的特殊情况。这是一个终端操作。
参数:比较器——一个非干扰的、无状态的比较器,用来比较流中的元素
返回:一个可选的描述这个流的最小元素,如果流是空的可选是空的
抛出:NullPointerException——如果最小元素为空
【《疯狂Java讲义(第六版)》——李刚,第八章】:
返回流中所有元素的最小值。
测试代码,如下所示:
import java.util.Comparator;
import java.util.List;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Optional<Integer> min = list.stream().map(UserInfo::getAge).min(new Comparator<Integer>() {
@Override
public int compare(Integer val1, Integer val2) {
// val2在前面则是求最大值,此处需要注意。
// return val2.compareTo(val1);
return val1.compareTo(val2);
}
});
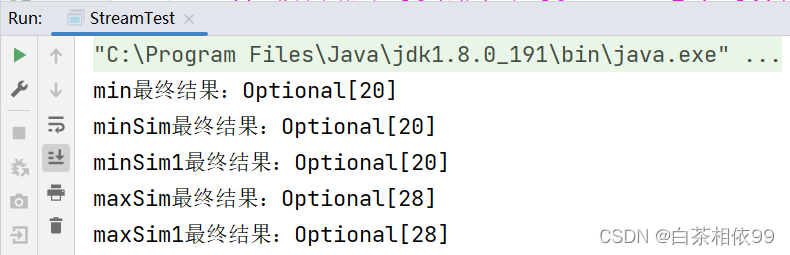
System.out.println("min最终结果:" + min);
// 求最小值(简写形式)
Optional<Integer> minSim = list.stream().map(UserInfo::getAge).min((val1, val2) -> val1.compareTo(val2));
System.out.println("minSim最终结果:" + minSim);
Optional<Integer> minSim1 = list.stream().map(UserInfo::getAge).min(Integer::compareTo);
System.out.println("minSim1最终结果:" + minSim1);
// 求最大值(val2在前面(val2.compareTo(val1))则是求最大值,此处需要注意)
Optional<Integer> maxSim = list.stream().map(UserInfo::getAge).min((val1, val2) -> val2.compareTo(val1));
System.out.println("maxSim最终结果:" + maxSim);
Optional<Integer> maxSim1 = list.stream().map(UserInfo::getAge).min(Comparator.reverseOrder());
System.out.println("maxSim1最终结果:" + maxSim1);
}
}以上代码运行结果,如下所示:
6、max()
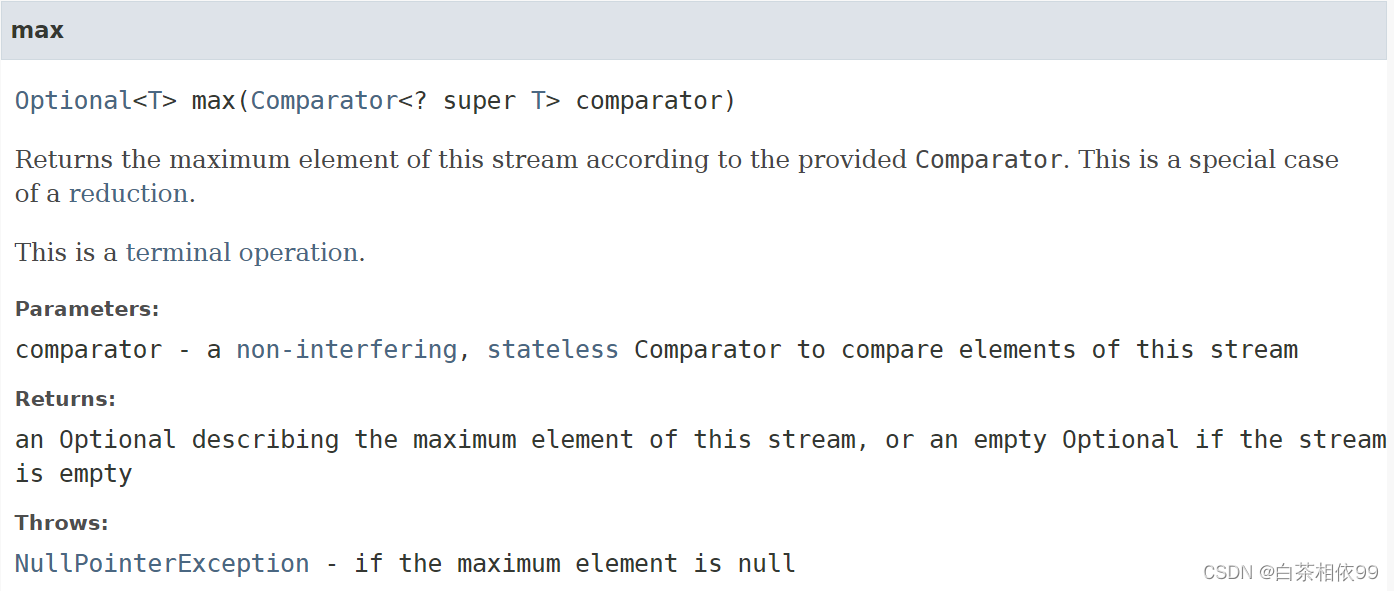
【Java 8 API文档——有道词典翻译】:
根据提供的比较器返回此流的最大元素。这是一个缩减的特殊情况。这是一个终端操作。
参数:比较器——一个非干扰的、无状态的比较器,用来比较流中的元素
返回:描述此流的最大元素的可选值,如果是流则为空的可选值是空的
抛出:NullPointerException——如果最大元素为空
【《疯狂Java讲义(第六版)》——李刚,第八章】:
返回流中所有元素的最大值。
测试代码,如下所示:
import java.util.Comparator;
import java.util.List;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Optional<Integer> max = list.stream().map(UserInfo::getAge).max(new Comparator<Integer>() {
@Override
public int compare(Integer val1, Integer val2) {
// val2在前面表示求最小值,此处需要注意。
// return val2.compareTo(val1);
return val1.compareTo(val2);
}
});
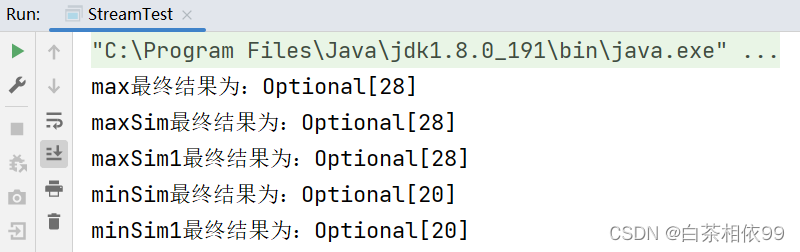
System.out.println("max最终结果为:" + max);
// 以上代码的简写形式,如下所示:
Optional<Integer> maxSim = list.stream().map(UserInfo::getAge).max((val1, val2) -> val1.compareTo(val2));
System.out.println("maxSim最终结果为:" + maxSim);
Optional<Integer> maxSim1 = list.stream().map(UserInfo::getAge).max(Integer::compareTo);
System.out.println("maxSim1最终结果为:" + maxSim1);
// 以下代码是将val2写在前面的简写,如下所示:
Optional<Integer> minSim = list.stream().map(UserInfo::getAge).max((val1, val2) -> val2.compareTo(val1));
System.out.println("minSim最终结果为:" + minSim);
Optional<Integer> minSim1 = list.stream().map(UserInfo::getAge).max(Comparator.reverseOrder());
System.out.println("minSim1最终结果为:" + minSim1);
}
}以上代码运行结果,如下所示:
7、count()

【Java 8 API文档——有道词典翻译】:
返回此流中元素的计数。这是一个特殊的约简情况,相当于:
return mapToLong(e -> 1L).sum();这是一个终端操作。
返回:该流中元素的计数
【《疯狂Java讲义(第六版)》——李刚,第八章】:
返回流中所有元素的数量。
测试代码,如下所示:
import java.util.List;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 统计list集合中的元素个数。
long count = list.stream().count();
System.out.println("list集合中的元素总数:" + count);
// 统计list集合中名字属性的个数
long sum = list.stream().map(UserInfo::getName).count();
System.out.println("名字属性的个数为:" + sum);
}
}以上代码运行结果,如下所示:

8、anyMatch(Predicate predicate)
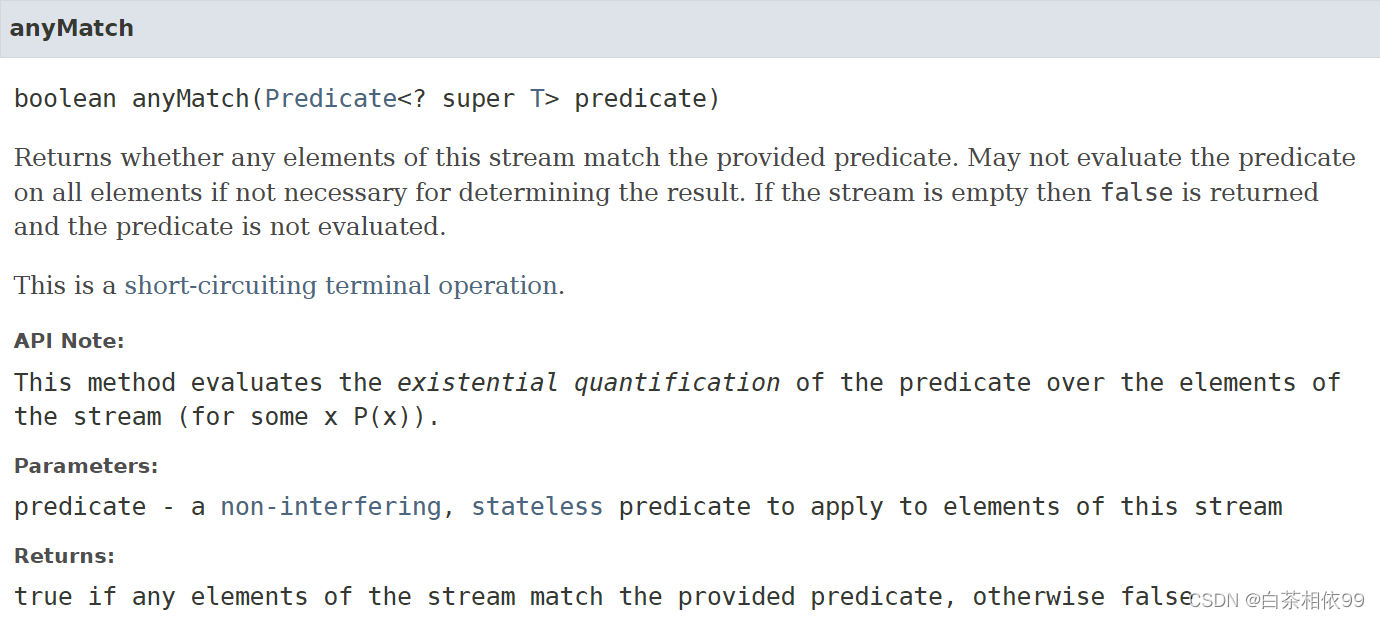
【Java 8 API文档——有道词典翻译】:
返回此流的任何元素是否与所提供的断言匹配。如果不是确定结果所必需的,可以不对所有元素计算断言。如果流为空,则返回false,不计算断言。这是一个短路终端操作。
API 说明:该方法计算流元素上断言的存在量化(for some x P(x))。
参数:谓词——一个非干扰的、无状态的断言,用于此流的元素
返回:如果流的任何元素匹配所提供的断言,则返回True,否则返回false
【《疯狂Java讲义(第六版)》——李刚,第八章】:
判断流中是否至少包含一个元素符合Predicate条件。
测试代码,如下所示:
import java.util.List;
import java.util.function.Predicate;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
boolean bool = list.stream().peek(System.out::println).anyMatch(new Predicate<UserInfo>() {
@Override
public boolean test(UserInfo userInfo) {
// 条件为:名字等于赵六,年龄等于23
return userInfo.getName().equals("赵六") && userInfo.getAge().equals(23);
}
});
System.out.println("是否存在满足条件的元素:" + bool);
}
}以上代码运行结果,如下所示:

通过以上结果,可以看出设置的条件(名字等于赵六,年龄等于23)会一个元素一个元素的进行匹配,匹配到就返回true,否则,就返回false。
【案例演示】
实际开发中,我们可能需要对两个不同集合进行比较取出相同或者不同的数据。下面举个简单的例子,仅供大家参考,实际开发中可自由发挥。需求:获取两个集合中存在名字相同,年龄一样的数据。
实现代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
List<UserInfo> newList = Arrays.asList(
new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0),
new UserInfo(222222L, "李四", 21, "女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2)
);
// 过滤出list中名字和年龄与newList中名字和年龄一样的UserInfo对象(获取两个集合中的相同数据)
List<UserInfo> alike = list.stream().filter(e -> newList.stream().anyMatch(userInfo -> {
return e.getName().equals(userInfo.getName()) && e.getAge() == userInfo.getAge();
})).collect(Collectors.toList());
for (UserInfo userInfo : alike) {
System.out.println("名字和年龄相同的UserInfo对象为:" + userInfo);
}
// 以上代码可以简写
List<UserInfo> alikeSim = list.stream().filter(e -> newList.stream().anyMatch(userInfo -> e.getName().equals(userInfo.getName()) && e.getAge() == userInfo.getAge())).collect(Collectors.toList());
System.out.println("********************************简写之后遍历的结果************************************");
for (UserInfo userInfo : alikeSim) {
System.out.println("简写:名字和年龄相同的UserInfo对象为:" + userInfo);
}
}
}以上代码运行结果,如下所示:

9、allMatch(Predicate predicate)

【Java 8 API文档——有道词典翻译】:
返回此流的所有元素是否与所提供的谓词匹配。如果不是确定结果所必需的,可以不对所有元素计算谓词。如果流为空,则返回true,不计算谓词。这是一个短路终端操作。
API 说明:该方法对流元素上的谓词(for all x P(x))进行通用量化。如果流为空,则称该量化是真空满足的,并且始终为真(regardless of P(x))。
参数:谓词——一个非干扰的、无状态的谓词,用于此流的元素
返回:如果流的所有元素都匹配所提供的谓词,或者流为空,否则为false
【《疯狂Java讲义(第六版)》——李刚,第八章】:
判断流中是否每个元素都符合Predicate条件。
测试代码,如下所示:
import java.util.List;
import java.util.Objects;
import java.util.regex.Pattern;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
list.stream().forEach(System.out::println);
String regex = "\\d{4}-\\d{2}-\\d{2}";
// 匹配生日是否是yyyy-MM-dd格式
boolean bool = list.stream().allMatch(e -> Pattern.compile(regex).matcher(Objects.toString(e.getBirthday())).matches());
System.out.println("匹配yyyy-MM-dd格式:" + bool);
// 匹配生日是否是yyyy-MM格式
String regex1 = "\\d{4}-\\d{2}";
boolean bool1 = list.stream().allMatch(e -> Pattern.compile(regex1).matcher(Objects.toString(e.getBirthday())).matches());
System.out.println("匹配yyyy-MM格式:" + bool1);
}
}以上代码运行结果,如下所示:

通过以上运行结果可知,匹配集合中所有元素都满足的情况下才返回true,否则返回false(测试代码有限,可下去自行测试)。实际开发中可通过该方法判断集合中的手机号码,身份证、特殊编码等是否符合正则表达式。此处不在举例说明,实际开发中自由发挥即可。
10、noneMatch(Predicate predicate)
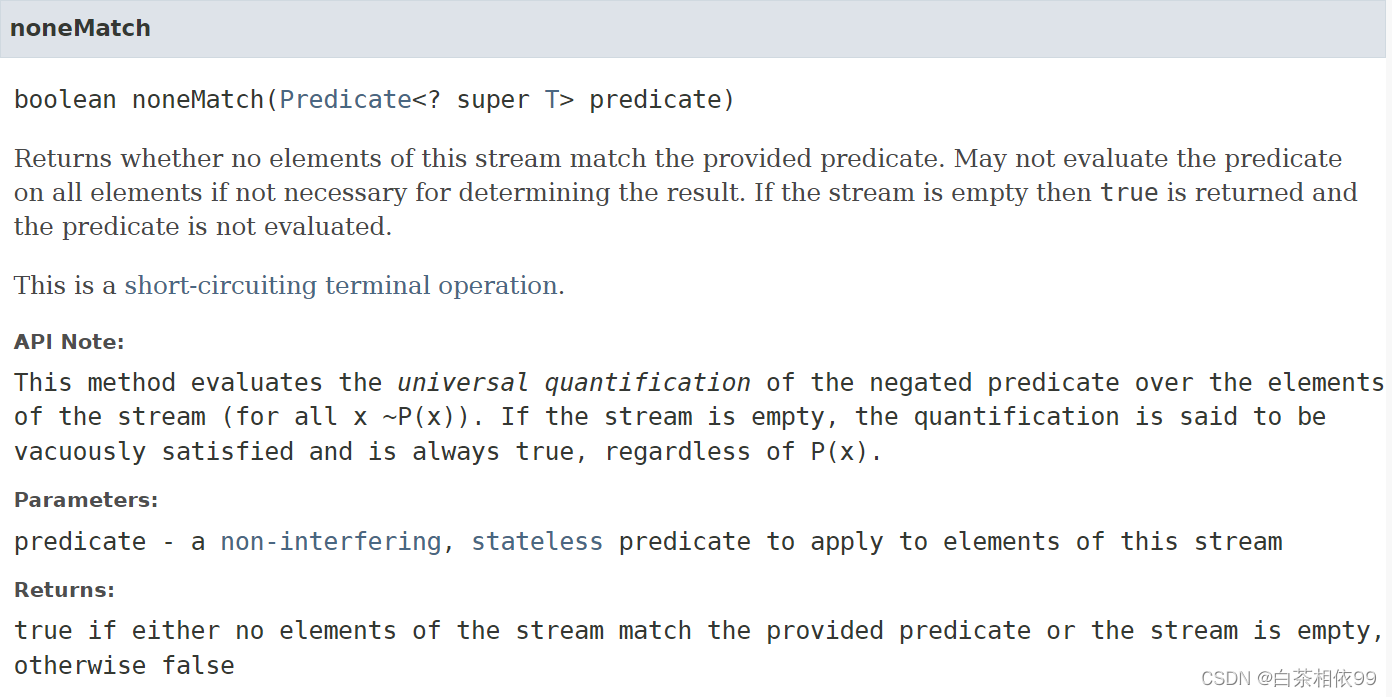
【Java 8 API文档——有道词典翻译】:
返回此流中是否没有元素与所提供的谓词匹配。如果不是确定结果所必需的,可以不对所有元素计算谓词。如果流为空,则返回true,不计算谓词。这是一个短路终端操作。
API 说明:该方法对流的元素(for all x ~P(x))求否定谓词的全称量化。如果流为空,则称该量化是真空满足的,并且无论P(x)如何,该量化始终为真。
参数:谓词——一个非干扰的、无状态的谓词,用于此流的元素
返回:如果流中没有元素匹配所提供的谓词或流为空,则返回True,否则返回false
【《疯狂Java讲义(第六版)》——李刚,第八章】:
判断流中是否所有元素都不符合Predicate条件。
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
List<UserInfo> newList = Arrays.asList(
new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0),
new UserInfo(222222L, "李四", 21, "女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2),
new UserInfo(999999L, "张飞", 21, "男", LocalDate.of(1900, Month.MARCH, 9), 59.0, 185.2)
);
// 返回list集合中与newList集合中不重复的元素集合
List<UserInfo> disList = list.stream().filter(e -> newList.stream().noneMatch(userInfo -> {
return e.getName().equals(userInfo.getName()) && e.getAge() == userInfo.getAge();
})).collect(Collectors.toList());
// 以上代码简写形式,如下所示:
// List<UserInfo> disList = list.stream().filter(e -> newList.stream().noneMatch(userInfo -> e.getName().equals(userInfo.getName()) && e.getAge() == userInfo.getAge())).collect(Collectors.toList());
for (UserInfo userInfo : disList) {
System.out.println("返回list中的元素:" + userInfo);
}
// 返回newList集合中与list集合中不重复的元素集合
List<UserInfo> disNewList = newList.stream().filter(e -> list.stream().noneMatch(userInfo -> {
return e.getName().equals(userInfo.getName()) && e.getAge() == userInfo.getAge();
})).collect(Collectors.toList());
// 以上代码简写形式,如下所示:
// List<UserInfo> disNewList = newList.stream().filter(e -> list.stream().noneMatch(userInfo -> e.getName().equals(userInfo.getName()) && e.getAge() == userInfo.getAge())).collect(Collectors.toList());
for (UserInfo userInfo : disNewList) {
System.out.println("返回newList中的元素:" + userInfo);
}
}
}以上代码运行结果,如下所示:
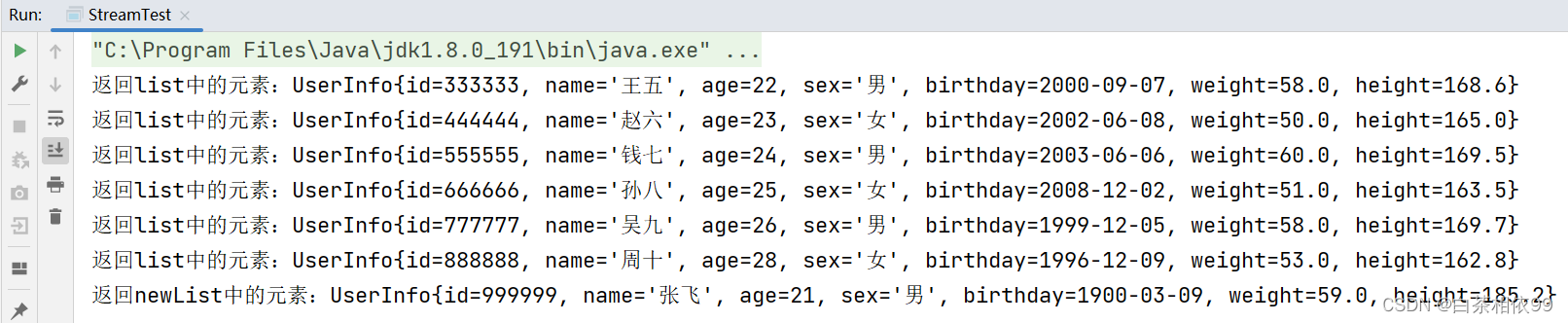
通过以上结果可求出两个集合的差集,将两个结果合并,disList.addAll(disNewList);即可。此处不在演示。
11、findFirst()

【Java 8 API文档——有道词典翻译】:
返回描述此流的第一个元素的Optional,如果流为空则返回空Optional。如果流没有相遇顺序,则可以返回任何元素。这是一个短路终端操作。
返回:描述流的第一个元素的Optional,如果是流则为空Optional是空的
抛出:NullPointerException——如果选定的元素为空
【《疯狂Java讲义(第六版)》——李刚,第八章】:
返回流中的第一个元素。
测试代码,如下所示:
import java.util.List;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Optional<UserInfo> first = list.stream().findFirst();
System.out.println("获取第一个对象:" + first);
Optional<String> firstName = list.stream().map(UserInfo::getName).findFirst();
System.out.println("获取第一个对象中的name属性:" + firstName);
}
}以上代码运行结果,如下所示:

12、findAny()
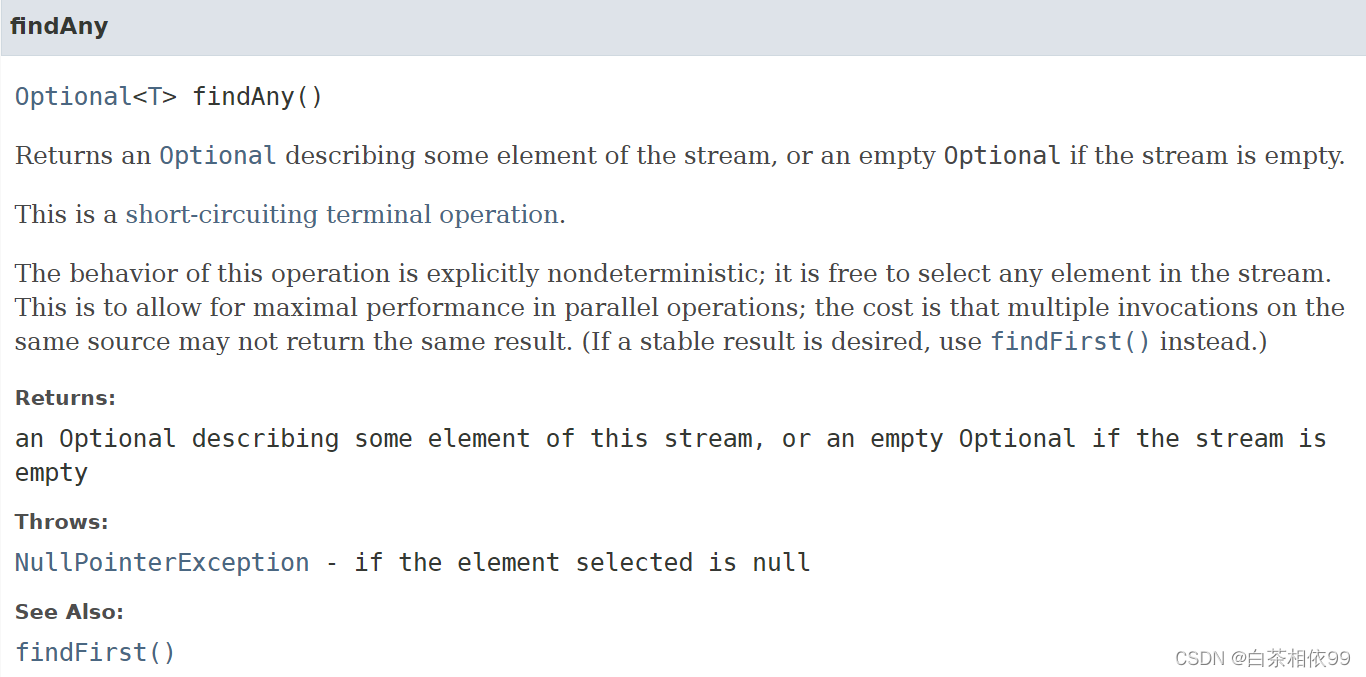
【Java 8 API文档——有道词典翻译】:
返回描述流的某个元素的Optional,如果流为空则返回空Optional。这是一个短路终端操作。这个操作的行为是明确的不确定性;可以自由选择流中的任何元素。这是为了在并行操作中实现最大的性能;代价是对同一源的多次调用可能不会返回相同的结果。(如果需要稳定的结果,请使用findFirst()代替。)
返回:描述此流的某个元素的可选参数,如果流为空则为空可选参数
抛出:NullPointerException——如果选定的元素为空
参见:findFirst ()
【《疯狂Java讲义(第六版)》——李刚,第八章】:
返回流中的任意一个元素。
测试代码,如下所示:
import java.util.List;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Optional<UserInfo> any = list.stream().findAny();
System.out.println("获取任意个对象:" + any);
Optional<String> anyName = list.stream().map(UserInfo::getName).findAny();
System.out.println("获取任意个对象中的name属性:" + anyName);
}
}以上代码运行结果,如下所示:

【注意】:findAny():返回流中的任意一个元素,大多数情况下还是返回第一个元素。但是源码没有为返回第一个元素提供有力保障。部分源码如下所示:

三、Optional简介
Optional(容器对象)是java.util包下面的一个类。以下内容来源于Java 8 API文档:

【Java 8 API文档——有道词典翻译】:
一个容器对象,它可以包含也可以不包含非空值。如果一个值存在,isPresent()将返回true, get()将返回该值。提供了依赖于包含值是否存在的其他方法,例如orElse()(如果值不存在则返回默认值)和ifPresent()(如果值存在则执行一段代码)。这是一个基于值的类;在Optional的实例上使用对身份敏感的操作(包括引用相等(==)、身份哈希码或同步)可能会产生不可预测的结果,应该避免。
【《疯狂Java讲义(第六版)》——李刚,第七章】:
Optional相当于一个容器,它所盛装的对象可能为null,也可能不为null,它的主要作用就是结合Lambda表达式来更优雅地处理是否为null的判断。
四、Optional API
1、empty()
【Java 8 API文档——有道词典翻译】:
返回一个空的可选实例。这个可选对象没有值。
API 说明:虽然这样做可能很诱人,但通过比较Option.empty()返回的实例与==来避免测试对象是否为空。不能保证它是单例对象。相反,使用isPresent()。
类型参数:T -不存在的值的类型
返回:一个空的Optional
测试代码,如下所示:
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
// 创建一个空的Optional容器
Optional<UserInfo> empty = Optional.empty();
System.out.println("创建一个空对象:" + empty);
}
}以上代码运行结果,如下所示:

2、of(T value)

【Java 8 API文档——有道词典翻译】:
返回具有指定当前非空值的可选对象。
类型参数:T——值的类型
参数:value -要呈现的值,它必须是非空
返回:带有当前值的可选参数
抛出:NullPointerException -如果值为空
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
// 创建一个不为空的Optional容器
UserInfo userInfo = new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0);
Optional<UserInfo> optional = Optional.of(userInfo);
System.out.println("创建一个不为空的Optional容器:" +optional);
}
}以上代码运行结果,如下所示:

3、ofNullable(T value)

【Java 8 API文档——有道词典翻译】:
返回描述指定值的Optional,如果非空,则返回空Optional。
类型参数:T——值的类型
参数:Value——要描述的可能空值
返回:如果指定的值非空,则返回一个带有当前值的Optional,否则返回一个空的Optional
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
// 创建一个Optional容器
UserInfo userInfo = new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0);
Optional<UserInfo> optional = Optional.ofNullable(userInfo);
System.out.println("创建一个不为空的Optional容器:" +optional);
Optional<Object> optNull = Optional.ofNullable(null);
System.out.println("创建一个为null的Optional容器:" + optNull);
}
}以上代码运行结果,如下所示:

4、get()

【Java 8 API文档——有道词典翻译】:
如果这个Optional中存在一个值,则返回该值,否则抛出NoSuchElementException。
返回:这个Optional包含的非空值
抛出:NoSuchElementException -如果没有值存在
参见:isPresent()
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
// 创建一个Optional容器
UserInfo userInfo = new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0);
Optional<UserInfo> optional = Optional.ofNullable(userInfo);
UserInfo optData = optional.get();
System.out.println("获取Optional容器中的数据:" + optData);
Optional<Object> optNull = Optional.ofNullable(null);
Object nullData = optNull.get();
System.out.println("获取Optional容器中的数据:" + nullData);
}
}以上代码运行结果,如下所示:

5、ifPresent()

【Java 8 API文档——有道词典翻译】:
如果存在值则返回true,否则返回false。
返回:如果存在值,则为True,否则为false
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
// 创建一个Optional容器
UserInfo userInfo = new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0);
Optional<UserInfo> optional = Optional.ofNullable(userInfo);
boolean optBoolData = optional.isPresent();
System.out.println("Optional容器有数据:" + optBoolData);
Optional<Object> optNull = Optional.ofNullable(null);
boolean optBoolNull = optNull.isPresent();
System.out.println("Optional容器中没有数据:" + optBoolNull);
}
}以上代码运行结果,如下所示:

6、isPresent(Consumer consumer)

【Java 8 API文档——有道词典翻译】:
如果存在值,则使用该值调用指定的消费者,否则什么都不做。
参数:如果有值存在,消费者块将被执行
抛出:NullPointerException -如果值存在且消费者为空
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.Optional;
import java.util.function.Consumer;
public class StreamTest {
public static void main(String[] args) {
// 创建一个Optional容器
UserInfo userInfo = new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0);
Optional<UserInfo> optional = Optional.ofNullable(userInfo);
optional.ifPresent(new Consumer<UserInfo>() {
@Override
public void accept(UserInfo userInfo) {
System.out.println("获取到的UserInfo对象为:" + userInfo);
}
});
// 简写形式,如下所示:
optional.ifPresent((info -> System.out.println("简写<==>获取到的UserInfo对象为:" + info)));
Optional<Object> optNull = Optional.ofNullable(null);
optNull.ifPresent(new Consumer<Object>() {
// 值为null时不调用以下方法
@Override
public void accept(Object o) {
System.out.println("获取到的Object对象为:对象为null值");
}
});
// 简写形式,如下所示:
optNull.ifPresent((obj) -> System.out.println("简写<==>获取到的Object对象为:对象为null值"));
}
}以上代码运行结果,如下所示:

7、filter(Predicate predicate)

【Java 8 API文档——有道词典翻译】:
如果存在一个值,并且该值与给定的谓词匹配,则返回描述该值的Optional,否则返回空Optional。
参数:predicate-如果存在,则应用于值的谓词
返回:如果存在一个值并且该值与给定的predicate匹配,则描述这个Optional的值,否则为空Optional
抛出:NullPointerException——如果谓词为空
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
// 创建一个Optional容器
UserInfo userInfo = new UserInfo(111111L, "张三", 20, "男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0);
Optional<UserInfo> optional = Optional.ofNullable(userInfo);
Optional<UserInfo> info = optional.filter(e -> e.getName().contains("张") && e.getAge() > 18);
System.out.println("过滤掉名字包含张,年龄大于18的对象:\n" + info);
Optional<UserInfo> infoNull = optional.filter(e -> e.getName().contains("张") && e.getAge() == 18);
System.out.println("过滤掉名字包含张,年龄等于18的对象:\n" + infoNull);
}
}以上代码运行结果,如下所示:

8、map(Function mapper)
【Java 8 API文档——有道词典翻译】:
如果存在值,则对其应用所提供的映射函数,如果结果非空,则返回描述结果的Optional。否则,返回一个空可选的。API 说明:此方法支持对可选值进行后处理,而不需要显式检查返回状态。例如,下面的代码遍历文件名流,选择一个尚未处理的文件名,然后打开该文件,返回一个可选的<FileInputStream>:
Optional<FileInputStream> fis = names.stream().filter(name -> !isProcessedYet(name)) .findFirst() .map(name -> new FileInputStream(name));这里,findFirst返回Optional<String>,然后map返回所需文件的Optional<FileInputStream>(如果存在)。
类型参数:U -映射函数的结果类型
参数:mapper——一个应用于值的映射函数,如果存在的话
返回:一个Optional描述将映射函数应用于此Optional的值的结果,如果存在值,否则为空Optional
抛出:NullPointerException——如果映射函数为空
测试代码,如下所示:
import java.util.List;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
// 获取list集合中的第一个元素
List<UserInfo> list = UserInfo.dataList();
// 将第一个元素中的name属性和age属性提取出来赋值给新的UserVo对象
Optional<UserVo> optional = list.stream().findFirst().map(e -> {
UserVo userVo = new UserVo();
userVo.setName(e.getName());
userVo.setAge(e.getAge());
return userVo;
});
System.out.println("新的UserVo对象为:" + optional);
}
}以上代码运行结果,如下所示:

9、flatMap(Function mapper)
【Java 8 API文档——有道词典翻译】:
如果存在值,则对其应用所提供的可选映射函数,返回该结果,否则返回空的Optional。此方法类似于map (Function),但所提供的映射器的结果已经是一个Optional,并且如果调用,flatMap不会用附加的Optional来包装它。
类型参数:U -可选返回的类型参数
参数:Mapper——应用于值的映射函数,如果呈现映射函数
返回:将可选映射函数应用于此Optional的值的结果,如果存在值,否则为空Optional
抛出:NullPointerException——如果映射函数为空或返回空结果
测试代码,如下所示:
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
/**
* flatMap方法和map方法类似,唯一的不同点就是 map方法会对返回的值进行Optional封装,
* 而flatMap不会,它需要手动执行Optional.of或Optional.ofNullable方法对Optional值进行封装。
*/
List<UserInfo> list = UserInfo.dataList();
Optional<UserVo> optObj = list.stream().findFirst().flatMap(e -> {
UserVo userVo = new UserVo();
userVo.setName(e.getName());
userVo.setAge(e.getAge());
return Optional.of(userVo);
});
System.out.println("新的UserVo对象为:" + optObj);
// 将第一个元素中的name属性和age属性提取出来赋值给新的Map对象
Optional<Map<String, Object>> optMap = list.stream().findFirst().flatMap(e -> {
Map<String, Object> map = new HashMap<>();
map.put("name", e.getName());
map.put("age", e.getAge());
return Optional.ofNullable(map);
});
System.out.println("新的Map对象为:" + optMap);
}
}以上代码运行结果,如下所示:

10、orElse(T other)

【Java 8 API文档——有道词典翻译】:
如果存在则返回值,否则返回other。
参数:Other——如果没有值,返回的值可能为null
返回:值,如果存在,否则为other
测试代码,如下所示:
import java.util.List;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Optional<String> optNull = list.stream().findFirst().filter(e -> e.getAge() < 20).map(UserInfo::getName);
System.out.println("获取的Optional为空:" + optNull.orElse("暂无数据"));
Optional<String> optObj = list.stream().findFirst().filter(e -> e.getAge() == 20).map(UserInfo::getName);
System.out.println("获取的Optional不为空:" + optObj.orElse("暂无数据"));
}
}以上代码运行结果,如下所示:

11、orElseGet(Supplier other)

【Java 8 API文档——有道词典翻译】:
如果存在则返回值,否则调用other并返回该调用的结果。
参数:other -一个provider,如果没有值返回结果
返回:如果值存在,则为other.get()的结果
抛出:NullPointerException - if value不存在且other为null
测试代码,如下所示:
import java.util.List;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Optional<UserInfo> optNull = list.stream().findFirst().filter(e -> e.getAge() < 20);
UserInfo userInfo1 = optNull.orElseGet(() -> {
UserInfo userInfo = new UserInfo();
userInfo.setName("暂无数据");
return userInfo;
});
System.out.println("获取的Optional为空:" + userInfo1);
Optional<UserInfo> optObj = list.stream().findFirst().filter(e -> e.getAge() == 20);
UserInfo userInfo2 = optObj.orElseGet(() -> {
UserInfo userInfo = new UserInfo();
return userInfo;
});
System.out.println("获取的Optional不为空:" + userInfo2);
}
}以上代码运行结果,如下所示:

12、orElseThrow(Supplier exceptionSupplier)

【Java 8 API文档——有道词典翻译】:
返回包含的值(如果存在),否则抛出由提供的提供程序创建的异常。
API 说明:对带有空参数列表的异常构造函数的方法引用可以用作提供者。例如,IllegalStateException::new类型
参数:X -要抛出异常的类型参数:exceptionprovider——将返回要抛出的异常的供应商
返回:现值
抛出:
X -如果没有值存在
NullPointerException -如果没有值存在并且exceptionprovider为空X继承Throwable
测试代码,如下所示:
import java.util.List;
import java.util.Optional;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Optional<UserInfo> optObj = list.stream().findFirst().filter(e -> e.getAge() == 20);
UserInfo userInfo2 = optObj.orElseThrow(() -> {
return new RuntimeException("你获取了一个为空的Optional容器");
});
System.out.println("获取的Optional不为空:" + userInfo2);
Optional<UserInfo> optNull = list.stream().findFirst().filter(e -> e.getAge() < 20);
UserInfo userInfo1 = optNull.orElseThrow(() -> {
return new RuntimeException("你获取了一个为空的Optional容器");
});
System.out.println("获取的Optional为空:" + userInfo1);
}
}以上代码运行结果,如下所示:

13、equals(Object obj)、hashCode()、toString()
equals(Object obj)、hashCode()、toString()这三个方法比较常见用法上大同小异,此处不在介绍。
五、Collectors简介

【Java 8 API文档——有道词典翻译】:
Collector的实现,实现各种有用的约简操作,例如将元素累积到集合中,根据各种标准汇总元素等。
六、Collectors API
由于文档字数已过4万字,所以以下方法的Java API文档截屏及翻译省略,需要看文档的读者请自行查询API文档进行阅读。
(一)、统计数据
1、统计集合的元素数量
要求:计算List<UserInfo>集合中的UserInfo对象的元素数量。测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
// 统计元素数量:counting
Long total = list.stream().collect(Collectors.counting());
System.out.println("统计元素数量====total====> " + total);
}
}以上代码控制台运行结果,如下图所示:

2、平均值
Collectors工具类为计算平均值提供了如下图所示的三个方法:

averagingDouble方法中需要传入一个ToDoubleFunction的函数式接口,通过源码查看可知,ToDoubleFunction函数式接口返回一个double类型的数值。

【函数式接口扩展知识】:
函数式接口:只有一个抽象方法的接口,就叫函数式接口。
@FunctionalInterface:用于修饰函数式接口,作用与@Override类似,都是用于““语法格式报错”。
在接口上添加@FunctionalInterface注解,并在接口中编写两个抽象方法的接口,测试代码省略,测试时编译报错,如下图所示:

Collectors工具类调用averagingDouble(ToDoubleFunction<? super T> mapper)方法时,发现需要传入一个实现ToDoubleFunction函数式接口,且有泛型通配符的下限(也称:泛型逆变)的约束。
【泛型逆变知识扩展】:
List<? super T>
如果类A是类B的父类,那么List<A>就相当于List<? super B>(只要求集合元素是B的父类,具体哪个父类则无法确定)的子类。-- 这种类型通配符的变化是逆向的,称为“逆变”。泛型逆变:只能进不能出。
List<类型>(只要尖括号中的类型是下限或者下限的子类),List<类型>的集合就可以被当成List<? super T>使用,用于被赋值。
对于带下限的通配符的泛型的实例。
(1)、只能调用参数类型为泛型(相当于集合添加元素)的方法,不能返回值参数类型为泛型(相当于为集合取出元素)的方法(除非你只把返回值当成Object类型来处理)。
(2)、调用参数类型为泛型的方法,传入的参数只能是下限或下限的子类。
调用averagingDouble(ToDoubleFunction<? super T> mapper)方法,代码如下所示:
// 实现ToDoubleFunction函数式接口,如下所示:
Collector<UserInfo, ?, Double> tDoubleCollector = Collectors.averagingDouble(new ToDoubleFunction<UserInfo>() {
@Override
public double applyAsDouble(UserInfo value) {
return value.getWeight();
}
});
// Lambda表达式的写法,如下所示:
Collector<Object, ?, Double> objectDoubleCollector = Collectors.averagingDouble(value -> {
try {
Method method = value.getClass().getMethod("weight", Double.class);
Object invoke = method.invoke("weight");
return Double.valueOf(invoke.toString());
} catch (Exception e) {
throw new RuntimeException(e);
}
});
// Lambda表达式的简化写法,如下所示:
Collector<UserInfo, ?, Double> userInfoDoubleCollector = Collectors.averagingDouble(UserInfo::getWeight);
以上对函数式接口有了一定的了解,接下来我们对Collectors工具类提供的计算平均值的方法进行测试。如下图所示:

通过函数式接口源码可知不同类型的数据需要调用不同类型的方法进行计算,测试代码如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
// 求平均值:averagingDouble、averagingInt、averagingLong
Double aDouble = list.stream().collect(Collectors.averagingDouble(UserInfo::getWeight));
System.out.println("求平均值====【求Double类型的平均值】====> " + aDouble);
Double aInt = list.stream().collect(Collectors.averagingInt(UserInfo::getAge));
System.out.println("求平均值====【求Int类型的平均值】====> " + aInt);
Double aLong = list.stream().collect(Collectors.averagingLong(UserInfo::getId));
System.out.println("求平均值====【求Long类型的平均值】====> " + aLong);
// 将浮点型转换为整型进行计算,转换过程可能出现精度丢失,慎用!
Double aDoubleByInt = list.stream().collect(Collectors.averagingInt(u -> u.getHeight().intValue()));
System.out.println("求平均值====【求Double类型转换为Int类型的平均值】====> " + aDoubleByInt);
Double aDoubleByLong = list.stream().collect(Collectors.averagingLong(u -> u.getHeight().longValue()));
System.out.println("求平均值====【求Double类型转换为Long类型的平均值】====> " + aDoubleByLong);
}
}以上代码控制台运行结果,如下图所示:

3、求和
Collectors工具类为计算求和提供了如下图所示的三个方法:

通过上图可知不同类型的数据需要调用不同类型的方法进行计算。测试代码如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
// 求和 - 需要进行类型转换时
System.out.println("********************需要进行类型转换时********************");
Integer aInt = list.stream().collect(Collectors.summingInt(u -> u.getWeight().intValue()));
System.out.println("求和====【求Int类型的和】====> " + aInt);
Long aLong = list.stream().collect(Collectors.summingLong(u -> u.getHeight().longValue()));
System.out.println("求和====【求Long类型的和】====> " + aLong);
Double aDouble = list.stream().collect(Collectors.summingDouble(u -> u.getAge().doubleValue()));
System.out.println("求和====【求Double类型的和】====> " + aDouble);
// 求和 - 不需要进行类型转换时
System.out.println("********************不需要进行类型转换时********************");
Integer bInt = list.stream().collect(Collectors.summingInt(UserInfo::getAge));
System.out.println("求和====【求Int类型的和】====> " + bInt);
Long bLong = list.stream().collect(Collectors.summingLong(UserInfo::getId));
System.out.println("求和====【求Long类型的和】====> " + bLong);
Double bDouble = list.stream().collect(Collectors.summingDouble(UserInfo::getHeight));
System.out.println("求和====【求Double类型的和】====> " + bDouble);
}
}以上代码控制台运行结果,如下图所示:

4、求最值
Collectors工具类为计算求最值提供了两个方法,maxBy()方法求最大值,minBy()方法求最小值,如下图所示:

通过上图可知需要传入Comparator接口作为参数,查看源码可知该接口中有静态方法可以直接调用。测试代码如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
// 求最值
Optional<UserInfo> min = list.stream().collect(Collectors.minBy(Comparator.comparing(UserInfo::getAge)));
System.out.println("求最小值====【求年龄的最小值】====> " + min);
Optional<UserInfo> max = list.stream().collect(Collectors.maxBy(Comparator.comparing(UserInfo::getAge)));
System.out.println("求最大值====【求年龄的最大值】====> " + max);
}
}以上代码控制台运行结果,如下图所示:

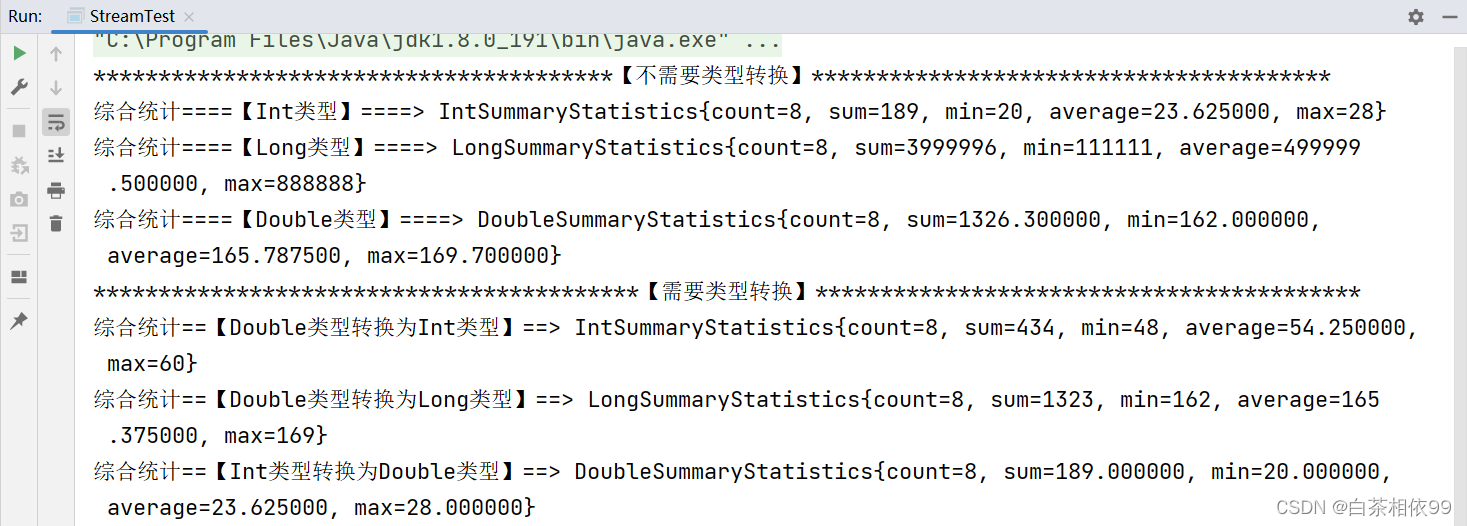
5、综合统计
综合统计是指指定集合中某个对象的某个属性进行计数(count)、求和(sum)、求最小值(min)、求平均值(average)、求最大值(max)对应的结果。Collectors工具类为综合统计提供三个方法,如下图所示:

通过上图可知不同类型的数据需要调用不同类型的方法进行统计,测试代码如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
// 导入数据
List<UserInfo> list = UserInfo.dataList();
// 综合统计
System.out.println("****************************************【不需要类型转换】****************************************");
IntSummaryStatistics intSum = list.stream().collect(Collectors.summarizingInt(UserInfo::getAge));
System.out.println("综合统计====【Int类型】====> " + intSum);
LongSummaryStatistics longSum = list.stream().collect(Collectors.summarizingLong(UserInfo::getId));
System.out.println("综合统计====【Long类型】====> " + longSum);
DoubleSummaryStatistics doubleSum = list.stream().collect(Collectors.summarizingDouble(UserInfo::getHeight));
System.out.println("综合统计====【Double类型】====> " + doubleSum);
System.out.println("******************************************【需要类型转换】******************************************");
IntSummaryStatistics aInt = list.stream().collect(Collectors.summarizingInt(u -> u.getWeight().intValue()));
System.out.println("综合统计==【Double类型转换为Int类型】==> " + aInt);
LongSummaryStatistics aLong = list.stream().collect(Collectors.summarizingLong(u -> u.getHeight().longValue()));
System.out.println("综合统计==【Double类型转换为Long类型】==> " + aLong);
DoubleSummaryStatistics aDouble = list.stream().collect(Collectors.summarizingDouble(u -> u.getAge().doubleValue()));
System.out.println("综合统计==【Int类型转换为Double类型】==> " + aDouble);
}
}以上代码控制台运行结果,如下图所示:
(二)、聚合对象

1、toMap()
【两个参数的toMap()方法】:
keyMapper – keys的映射函数valueMapper – values的映射函数
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.List;
import java.util.Map;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Map<Long, UserInfo> map = list.stream().collect(Collectors.toMap(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, new Function<UserInfo, UserInfo>() {
@Override
public UserInfo apply(UserInfo userInfo) {
return userInfo;
}
}));
// 简写形式,如下所示:
// Map<Long, UserInfo> map = list.stream().collect(Collectors.toMap(userInfo -> userInfo.getId(), userInfo -> userInfo));
// 更优雅的简写形式,如下所示:
// Map<Long, UserInfo> map = list.stream().collect(Collectors.toMap(UserInfo::getId, Function.identity()));
System.out.println(map);
}
}以上代码运行结果,如下所示:

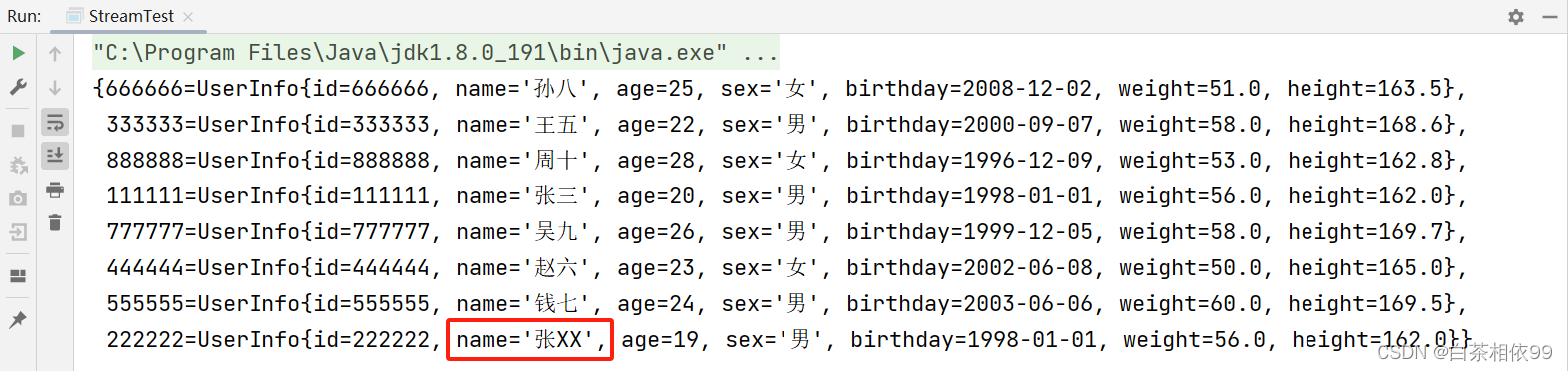
如果数据中出现重复Id的数据,运行时以上方法出会出现IllegalStateException(非法状态异常),如下所示:

解决办法是toMap()方法的第三个参数。如下所示:
【三个参数的toMap()方法】:
keyMapper – keys的映射函数valueMapper – values的映射函数
mergeFunction – 一个合并函数,用于解决与相同键关联的值之间的冲突,提供给Map merge(Object, Object, biffunction)。
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 在刚刚的数据中加入两条id相同的数据如下所示:
List<UserInfo> arr = new ArrayList<>();
arr.add(new UserInfo(222222L, "张XX",19,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0));
arr.add(new UserInfo(222222L, "李XX",18,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2));
arr.addAll(list);
Map<Long, UserInfo> map = arr.stream().collect(Collectors.toMap(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, new Function<UserInfo, UserInfo>() {
@Override
public UserInfo apply(UserInfo userInfo) {
return userInfo;
}
}, new BinaryOperator<UserInfo>() {
@Override
public UserInfo apply(UserInfo userInfo1, UserInfo userInfo2) {
// 出现重复数据时取第一个对象数据
return userInfo1;
}
}));
// 简写形式,如下所示:
// Map<Long, UserInfo> map = arr.stream().collect(Collectors.toMap(userInfo -> userInfo.getId(), userInfo -> userInfo,(userInfo1, userInfo2)-> userInfo1));
// 更优雅的简写形式,如下所示:
// Map<Long, UserInfo> map = arr.stream().collect(Collectors.toMap(UserInfo::getId, Function.identity(),(userInfo1, userInfo2)-> userInfo1));
System.out.println(map);
}
}以上代码运行结果,如下所示:
【四个参数的toMap()方法】:
keyMapper – keys的映射函数valueMapper – values的映射函数
mergeFunction – 一个合并函数,用于解决与相同键关联的值之间的冲突,提供给Map merge(Object, Object, biffunction)。
mapSupplier – 返回一个新的空Map,将结果插入其中的函数
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.*;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 在刚刚的数据中加入两条id相同的数据如下所示:
List<UserInfo> arr = new ArrayList<>();
arr.add(new UserInfo(222222L, "张XX",19,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0));
arr.add(new UserInfo(222222L, "李XX",18,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2));
arr.addAll(list);
Map<Long, UserInfo> map= arr.stream().collect(Collectors.toMap(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, new Function<UserInfo, UserInfo>() {
@Override
public UserInfo apply(UserInfo userInfo) {
return userInfo;
}
}, new BinaryOperator<UserInfo>() {
@Override
public UserInfo apply(UserInfo userInfo1, UserInfo userInfo2) {
// 出现重复数据时取第一个数据
return userInfo1;
}
}, new Supplier<Map<Long, UserInfo>>() {
@Override
public Map<Long, UserInfo> get() {
// 创建一个新的空Map,将数据放入新的空Map中
// return new TreeMap<>();
// return new HashMap<>();
return new LinkedHashMap<>();
}
}));
// 简写形式,如下所示:
// Map<Long, UserInfo> map = arr.stream().collect(Collectors.toMap(userInfo -> userInfo.getId(), userInfo -> userInfo,(userInfo1, userInfo2) -> userInfo1, () -> new LinkedHashMap<>()));
// 更优雅的简写形式,如下所示:
// Map<Long, UserInfo> map = arr.stream().collect(Collectors.toMap(UserInfo::getId, Function.identity(), (userInfo1, userInfo2)-> userInfo1, LinkedHashMap::new));
System.out.println(map);
}
}以上代码运行结果,如下所示:
2、toConcurrentMap()
【Java API说明】:
toConcurrentMap()方法返回一个并发收集器,该收集器将元素累积到ConcurrentMap中,ConcurrentMap的键和值是将提供的映射函数应用于输入元素的结果。如果映射的键包含重复项 (according to Object.equals(Object)),将值映射函数应用于每个相等的元素,并使用提供的合并函数对结果进行合并。
【自我理解】:
其实和toMap()和toConcurrentMap()用法一样,只是返回值有所差异,toMap()返回的是Map类型的数据,而toConcurrentMap()返回的是ConcurrentMap类型的数据。
【两个参数的toMap()方法】:
keyMapper – keys的映射函数valueMapper – values的映射函数
测试代码,如下所示:
import java.util.*;
import java.util.concurrent.ConcurrentMap;
import java.util.function.Function;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
ConcurrentMap<Long, String> concurrentMap = list.stream().collect(Collectors.toConcurrentMap(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, new Function<UserInfo, String>() {
@Override
public String apply(UserInfo userInfo) {
return userInfo.getName();
}
}));
// 简写形式,如下所示:
// ConcurrentMap<Long, String> concurrentMap = list.stream().collect(Collectors.toConcurrentMap(userInfo -> userInfo.getId(), userInfo -> userInfo.getName()));
// 更优雅的简写形式,如下所示:
// ConcurrentMap<Long, String> concurrentMap = list.stream().collect(Collectors.toConcurrentMap(UserInfo::getId, UserInfo::getName));
System.out.println(concurrentMap);
}
}以上代码运行结果,如下所示:

如果数据中出现重复Id的数据,运行时以上方法出会出现IllegalStateException(非法状态异常),如下所示:
 解决办法是toConcurrentMap()方法的第三个参数。如下所示:
解决办法是toConcurrentMap()方法的第三个参数。如下所示:
【三个参数的toMap()方法】:
keyMapper – keys的映射函数valueMapper – values的映射函数
mergeFunction – 一个合并函数,用于解决与相同键关联的值之间的冲突,提供给Map merge(Object, Object, biffunction)。
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.*;
import java.util.concurrent.ConcurrentMap;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 在刚刚的数据中加入两条id相同的数据如下所示:
List<UserInfo> arr = new ArrayList<>();
arr.add(new UserInfo(222222L, "张XX",19,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0));
arr.add(new UserInfo(222222L, "李XX",18,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2));
arr.addAll(list);
ConcurrentMap<Long, String> concurrentMap = arr.stream().collect(Collectors.toConcurrentMap(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, new Function<UserInfo, String>() {
@Override
public String apply(UserInfo userInfo) {
return userInfo.getName();
}
}, new BinaryOperator<String>() {
@Override
public String apply(String str1, String str2) {
return str1;
}
}));
// 简写形式,如下所示:
// ConcurrentMap<Long, String> concurrentMap = arr.stream().collect(Collectors.toConcurrentMap(userInfo -> userInfo.getId(), userInfo -> userInfo.getName(), (str1, str2) -> str1));
// 更优雅的简写形式,如下所示:
// ConcurrentMap<Long, String> concurrentMap = arr.stream().collect(Collectors.toConcurrentMap(UserInfo::getId, UserInfo::getName, (str1, str2) -> str1));
System.out.println(concurrentMap);
}
}以上代码运行结果,如下所示:

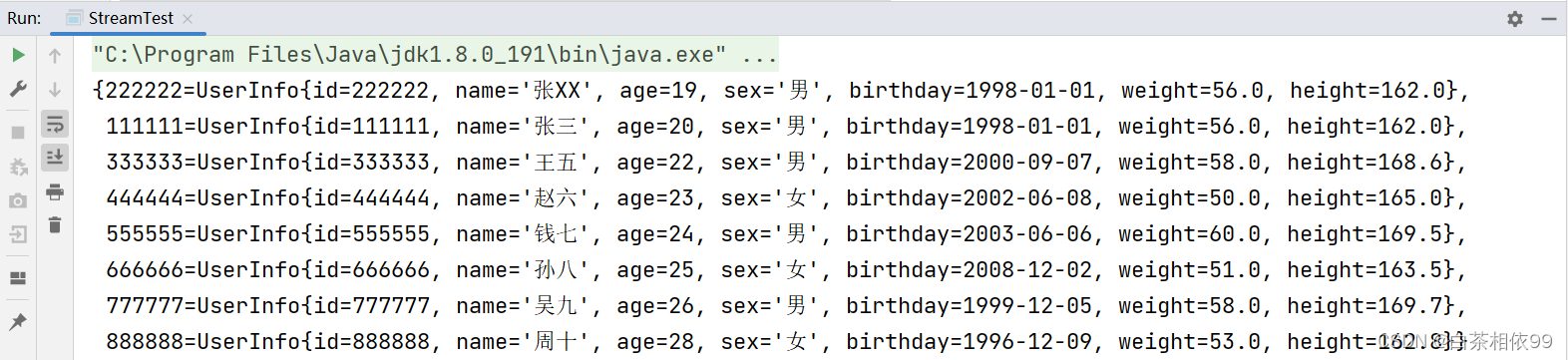
【四个参数的toMap()方法】:
keyMapper – keys的映射函数valueMapper – values的映射函数
mergeFunction – 一个合并函数,用于解决与相同键关联的值之间的冲突,提供给Map merge(Object, Object, biffunction)。
mapSupplier – 返回一个新的空Map,将结果插入其中的函数
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 在刚刚的数据中加入两条id相同的数据如下所示:
List<UserInfo> arr = new ArrayList<>();
arr.add(new UserInfo(222222L, "张XX",19,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0));
arr.add(new UserInfo(222222L, "李XX",18,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2));
arr.addAll(list);
ConcurrentMap<Long, String> concurrentMap = arr.stream().collect(Collectors.toConcurrentMap(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, new Function<UserInfo, String>() {
@Override
public String apply(UserInfo userInfo) {
return userInfo.getName();
}
}, new BinaryOperator<String>() {
@Override
public String apply(String str1, String str2) {
return str1;
}
}, new Supplier<ConcurrentMap<Long, String>>() {
@Override
public ConcurrentMap<Long, String> get() {
// 返回一个新的ConcurrentHashMap,将数据插入新的ConcurrentHashMap中
return new ConcurrentHashMap<>();
}
}));
// 简写形式,如下所示:
// ConcurrentMap<Long, String> concurrentMap = arr.stream().collect(Collectors.toConcurrentMap(userInfo -> userInfo.getId(), userInfo -> userInfo.getName(), (str1, str2) -> str1,ConcurrentHashMap::new));
// 更优雅的简写形式,如下所示:
// ConcurrentMap<Long, String> concurrentMap = arr.stream().collect(Collectors.toConcurrentMap(UserInfo::getId, UserInfo::getName, (str1, str2) -> str1, ConcurrentHashMap::new));
System.out.println(concurrentMap);
}
}以上代码运行结果,如下所示:

(三)、聚合集合

toSet()、toList()、toCollection()三个方法比较简单,此处就不依次列举说明了,直接测试。
测试代码,如下所示:
import java.time.LocalDate;
import java.util.*;
import java.util.function.Supplier;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
Set<String> toSet = list.stream().map(UserInfo::getName).collect(Collectors.toSet());
System.out.println("toSet聚合名字属性:\n" + toSet);
List<Integer> toList = list.stream().map(UserInfo::getAge).collect(Collectors.toList());
System.out.println("toList聚合年龄属性:\n" + toList);
List<LocalDate> toCollection = list.stream().map(UserInfo::getBirthday).collect(Collectors.toCollection(new Supplier<List<LocalDate>>() {
@Override
public List<LocalDate> get() {
return new ArrayList<>();
}
}));
System.out.println("toCollection聚合出生日期属性:\n" + toCollection);
// 简写形式,如下所示:
List<LocalDate> toCol = list.stream().map(UserInfo::getBirthday).collect(Collectors.toCollection(() -> new ArrayList<>()));
System.out.println("简写形式 <====> toCollection聚合出生日期属性:\n" + toCol);
// 更优雅的简写形式,如下所示:
List<LocalDate> toC = list.stream().map(UserInfo::getBirthday).collect(Collectors.toCollection(ArrayList::new));
System.out.println("更优雅的简写形式 <====> toCollection聚合出生日期属性:\n" + toC);
}
}以上代码运行结果,如下所示:
 (四)、分组
(四)、分组

1、groupingBy()
【groupingBy()方法的三个参数】:
classifier – 一个将输入元素映射到键的分类器函数mapFactory – 一个函数,当它被调用时,会产生一个新的所需类型的空Map
downstream – 一个执行下游缩减的收集器
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.*;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 在刚刚的数据中加入两条id相同的数据如下所示:
List<UserInfo> arr = new ArrayList<>();
arr.add(new UserInfo(222222L, "张XX",19,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0));
arr.add(new UserInfo(222222L, "李XX",18,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2));
arr.addAll(list);
/**
* 传一个参数
* Function:是一个函数式接口,可以直接new一个Function并实现接口方法。
*/
Map<Long, List<UserInfo>> oneList = arr.stream().collect(Collectors.groupingBy(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}));
// System.out.println("传一个参数传统写法的结果:\n" + oneList);
// 简写形式,代码如下所示:
Map<Long, List<UserInfo>> oneListAd = arr.stream().collect(Collectors.groupingBy(userInfo -> userInfo.getId()));
// System.out.println("传一个参数简写形式的结果:\n" + oneListAd);
// 更优雅的简写形式,代码如下所示:
Map<Long, List<UserInfo>> oLAd = arr.stream().collect(Collectors.groupingBy(UserInfo::getId));
// System.out.println("传一个参数更优雅的简写形式的结果:\n" + oLAd);
/**
* 传两个参数
* Function:是一个函数式接口,可以直接new一个Function并实现接口方法。
* Collector:通过源码观察,Collector不是函数式接口,如果直接new一个Collector实现接口方法,这样过于复杂。
* 但是可以用Collectors.toList()、Collectors.toSet()、Collectors.toCollection(ArrayList::new)等等,
* 这些静态方法的返回值是Collector类型。
*/
Map<Long, List<UserInfo>> twoList = arr.stream().collect(Collectors.groupingBy(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, Collectors.toList()));
// System.out.println("传两个参数传统写法的结果:\n" + twoList);
// 简写形式,代码如下所示:
Map<Long, List<UserInfo>> twoListAd = arr.stream().collect(Collectors.groupingBy(userInfo -> userInfo.getId(), Collectors.toList()));
// System.out.println("传两个参数简写形式的结果:\n" + twoListAd);
// 更优雅的简写形式,代码如下所示:
Map<Long, List<UserInfo>> tLAd = arr.stream().collect(Collectors.groupingBy(UserInfo::getId, Collectors.toList()));
// System.out.println("传两个参数更优雅的简写形式的结果:\n" + tLAd);
/**
* 传三个参数
* Function:是一个函数式接口,可以直接new一个Function并实现接口方法。
* Supplier:是一个函数式接口,可以直接new一个Supplier并实现接口方法。
* Collector:通过源码观察,Collector不是函数式接口,如果直接new一个Collector实现接口方法,这样过于复杂。
* 但是可以用Collectors.toList()、Collectors.toSet()、Collectors.toCollection(ArrayList::new)等等,
* 这些静态方法的返回值是Collector类型。
*/
Map<Long, List<UserInfo>> threeList = arr.stream().collect(Collectors.groupingBy(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, new Supplier<Map<Long, List<UserInfo>>>() {
@Override
public Map<Long, List<UserInfo>> get() {
// 创建一个新的HashMap,将数据放入此Map中
return new HashMap<>();
}
}, Collectors.toList()));
// System.out.println("传三个参数传统写法的结果:\n" + threeList);
// 简写形式,代码如下所示:
Map<Long, List<UserInfo>> threeListAd = arr.stream().collect(Collectors.groupingBy(userInfo -> userInfo.getId(),() -> new HashMap<>(), Collectors.toList()));
// System.out.println("传三个参数简写形式的结果:\n" + threeListAd);
// 更优雅的简写形式,代码如下所示:
Map<Long, List<UserInfo>> thLAd = arr.stream().collect(Collectors.groupingBy(UserInfo::getId, HashMap::new, Collectors.toList()));
System.out.println("传三个参数更优雅的简写形式的结果:\n" + thLAd);
}
}以上代码运行结果,如下所示:

2、groupingByConcurrent()
【groupingByConcurrent()方法的三个参数】:
classifier – 一个将输入元素映射到键的分类器函数mapFactory – 一个函数,当它被调用时,会产生一个新的所需类型的空Map
downstream – 一个执行下游缩减的收集器
【说明】:
groupingBy()方法与groupingByConcurrent()方法一样,只是返回的数据类型略有差异,前者返回Map类型数据,后者返回ConcurrentMap类型
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 在刚刚的数据中加入两条id相同的数据如下所示:
List<UserInfo> arr = new ArrayList<>();
arr.add(new UserInfo(222222L, "张XX",19,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0));
arr.add(new UserInfo(222222L, "李XX",18,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2));
arr.addAll(list);
/**
* 传一个参数
* Function:是一个函数式接口,可以直接new一个Function并实现接口方法。
*/
ConcurrentMap<Long, List<UserInfo>> oneList = arr.stream().collect(Collectors.groupingByConcurrent(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}));
// System.out.println("传一个参数传统写法的结果:\n" + oneList);
// 简写形式,代码如下所示:
ConcurrentMap<Long, List<UserInfo>> oneListAd = arr.stream().collect(Collectors.groupingByConcurrent(userInfo -> userInfo.getId()));
// System.out.println("传一个参数简写形式的结果:\n" + oneListAd);
// 更优雅的简写形式,代码如下所示:
ConcurrentMap<Long, List<UserInfo>> oLAd = arr.stream().collect(Collectors.groupingByConcurrent(UserInfo::getId));
// System.out.println("传一个参数更优雅的简写形式的结果:\n" + oLAd);
/**
* 传两个参数
* Function:是一个函数式接口,可以直接new一个Function并实现接口方法。
* Collector:通过源码观察,Collector不是函数式接口,如果直接new一个Collector实现接口方法,这样过于复杂。
* 但是可以用Collectors.toList()、Collectors.toSet()、Collectors.toCollection(ArrayList::new)等等,
* 这些静态方法的返回值是Collector类型。
*/
ConcurrentMap<Long, List<UserInfo>> twoList = arr.stream().collect(Collectors.groupingByConcurrent(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, Collectors.toList()));
// System.out.println("传两个参数传统写法的结果:\n" + twoList);
// 简写形式,代码如下所示:
ConcurrentMap<Long, List<UserInfo>> twoListAd = arr.stream().collect(Collectors.groupingByConcurrent(userInfo -> userInfo.getId(), Collectors.toList()));
// System.out.println("传两个参数简写形式的结果:\n" + twoListAd);
// 更优雅的简写形式,代码如下所示:
ConcurrentMap<Long, List<UserInfo>> tLAd = arr.stream().collect(Collectors.groupingByConcurrent(UserInfo::getId, Collectors.toList()));
// System.out.println("传两个参数更优雅的简写形式的结果:\n" + tLAd);
/**
* 传三个参数
* Function:是一个函数式接口,可以直接new一个Function并实现接口方法。
* Supplier:是一个函数式接口,可以直接new一个Supplier并实现接口方法。
* Collector:通过源码观察,Collector不是函数式接口,如果直接new一个Collector实现接口方法,这样过于复杂。
* 但是可以用Collectors.toList()、Collectors.toSet()、Collectors.toCollection(ArrayList::new)等等,
* 这些静态方法的返回值是Collector类型。
*/
ConcurrentMap<Long, List<UserInfo>> threeList = arr.stream().collect(Collectors.groupingByConcurrent(new Function<UserInfo, Long>() {
@Override
public Long apply(UserInfo userInfo) {
return userInfo.getId();
}
}, new Supplier<ConcurrentMap<Long, List<UserInfo>>>() {
@Override
public ConcurrentMap<Long, List<UserInfo>> get() {
// 创建一个新的ConcurrentHashMap,将数据放入此ConcurrentHashMap中
return new ConcurrentHashMap<>();
}
}, Collectors.toList()));
// System.out.println("传三个参数传统写法的结果:\n" + threeList);
// 简写形式,代码如下所示:
ConcurrentMap<Long, List<UserInfo>> threeListAd = arr.stream().collect(Collectors.groupingByConcurrent(userInfo -> userInfo.getId(),() -> new ConcurrentHashMap<>(), Collectors.toList()));
// System.out.println("传三个参数简写形式的结果:\n" + threeListAd);
// 更优雅的简写形式,代码如下所示:
ConcurrentMap<Long, List<UserInfo>> thLAd = arr.stream().collect(Collectors.groupingByConcurrent(UserInfo::getId, ConcurrentHashMap::new, Collectors.toList()));
System.out.println("传三个参数更优雅的简写形式的结果:\n" + thLAd);
}
}以上代码运行结果,如下所示:
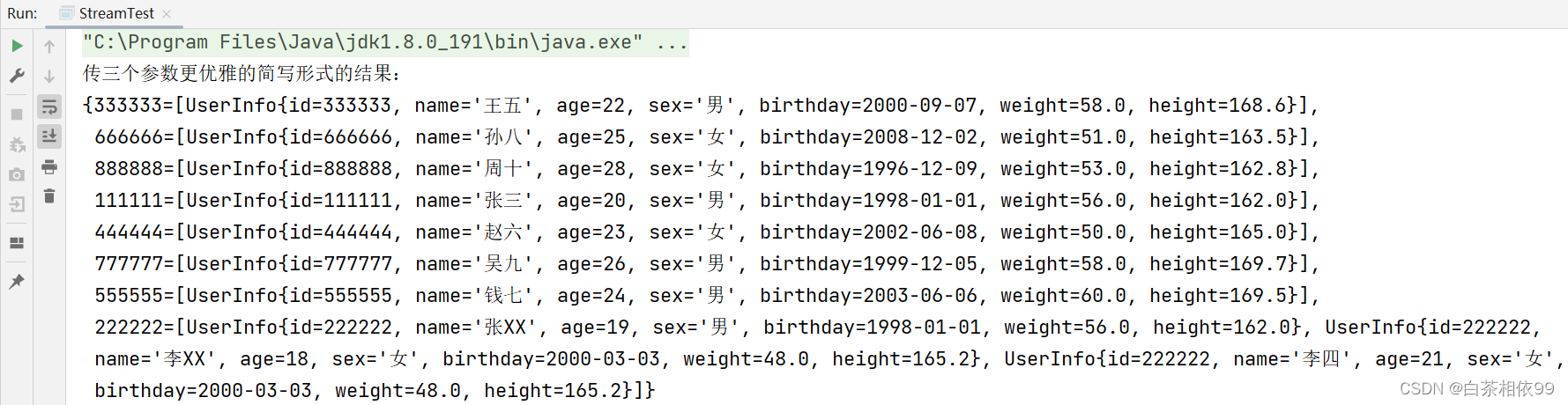
3、partitioningBy()

【partitioningBy()方法的三个参数】:
predicate – 用于对输入元素进行分类的断言
downstream – 实现下游缩减的收集器
测试代码,如下所示:
import java.time.LocalDate;
import java.time.Month;
import java.util.*;
import java.util.function.Predicate;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 在刚刚的数据中加入两条id相同的数据如下所示:
List<UserInfo> arr = new ArrayList<>();
arr.add(new UserInfo(222222L, "张XX",19,"男", LocalDate.of(1998, Month.JANUARY, 1), 56.0, 162.0));
arr.add(new UserInfo(222222L, "李XX",18,"女", LocalDate.of(2000, Month.MARCH, 3), 48.0, 165.2));
arr.addAll(list);
/**
* 传一个参数
* Predicate:是一个函数式接口,可以直接new一个Predicate并实现接口方法。
*/
Map<Boolean, List<UserInfo>> oneList = arr.stream().collect(Collectors.partitioningBy(new Predicate<UserInfo>() {
@Override
public boolean test(UserInfo userInfo) {
return userInfo.getAge() > 23;
}
}));
// System.out.println("传一个参数传统写法的结果:\n" + oneList);
// 简写形式,代码如下所示:
Map<Boolean, List<UserInfo>> oneListAd = arr.stream().collect(Collectors.partitioningBy(userInfo -> userInfo.getAge() > 23));
// System.out.println("传一个参数简写形式的结果:\n" + oneListAd);
/**
* 传两个参数
* Function:是一个函数式接口,可以直接new一个Function并实现接口方法。
* Collector:通过源码观察,Collector不是函数式接口,如果直接new一个Collector实现接口方法,这样过于复杂。
* 但是可以用Collectors.toList()、Collectors.toSet()、Collectors.toCollection(ArrayList::new)等等,
* 这些静态方法的返回值是Collector类型。
*/
Map<Boolean, List<UserInfo>> twoList = arr.stream().collect(Collectors.partitioningBy(new Predicate<UserInfo>() {
@Override
public boolean test(UserInfo userInfo) {
return userInfo.getAge() > 25;
}
}, Collectors.toList()));
// System.out.println("传两个参数传统写法的结果:\n" + twoList);
// 简写形式,代码如下所示:
Map<Boolean, List<UserInfo>> twoListAd = arr.stream().collect(Collectors.partitioningBy(userInfo -> userInfo.getAge() > 25, Collectors.toList()));
System.out.println("传两个参数简写形式的结果:\n" + twoListAd);
}
}以上代码运行结果,如下所示:

(五)、连接操作

【joining()方的三个参数】:
delimiter – 在每个元素之间使用的分隔符prefix – 要在联接结果的开头使用的字符序列
suffix – 要在连接结果的末尾使用的字符序列
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
String zeroStr = list.stream().map(UserInfo::getName).collect(Collectors.joining());
System.out.println("传一个参数:" + zeroStr);
// 第一个参数表示分割符
String oneStr = list.stream().map(UserInfo::getName).collect(Collectors.joining(","));
System.out.println("传二个参数:" + oneStr);
// 第一个参数表示分割符,第二个参数表示前缀,第三个表示后缀。
String threeStr = list.stream().map(UserInfo::getName).collect(Collectors.joining(",", "【", "】"));
System.out.println("传三个参数:" + threeStr);
}
}以上代码运行结果,如下所示:

(六)、其它聚合操作
1、mapping()

【提示】:该法在【二、Stream API】中介绍的map() 相似,推荐使用Stream中的map()方法。
【mapping()方的二个参数】:
mapper – 应用于输入元素的函数
downstream – 将接受映射值的收集器
测试代码,如下所示:
import java.util.*;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// stream().map()方法【推荐使用这种方法】
List<String> nameStream = list.stream().map(UserInfo::getName).collect(Collectors.toList());
System.out.println("stream().map()方法:" + nameStream);
// Collectors.mapping()方法
List<String> nameList = list.stream().collect(Collectors.mapping(UserInfo::getName, Collectors.toList()));
System.out.println("Collectors.mapping()方法:" + nameList);
}
}以上代码运行结果,如下所示:

2、reducing()

【reducing()方的二个参数】:
identity – 约简的标识值(也就是在没有输入元素时返回的值)mapper – 应用于每个输入值的映射函数
op – 用于约简映射值的BinaryOperator<U>
测试代码,如下所示:
import java.util.*;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 传入一个参数
System.out.println("***********传入一个参数*************");
Optional<Integer> oneOpt = list.stream().map(UserInfo::getAge).collect(Collectors.reducing(new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer val1, Integer val2) {
return val1 + val2;
}
}));
System.out.println("传一个参数传统写法:" + oneOpt);
// 以上代码简写形式,如下所示:
Optional<Integer> oneOptAd = list.stream().map(UserInfo::getAge).collect(Collectors.reducing((val1, val2) -> val1 + val2));
System.out.println("传一个参数简写形式写法:" + oneOptAd);
// 优雅的代码简写形式,如下所示:
Optional<Integer> oneOA = list.stream().map(UserInfo::getAge).collect(Collectors.reducing(Integer::sum));
System.out.println("传一个参数优雅的代码简写写法:" + oneOA);
// 传入二个参数
System.out.println("***********传二个参数*************");
Integer twoInt = list.stream().map(UserInfo::getAge).collect(Collectors.reducing(0, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer val1, Integer val2) {
return val1 + val2;
}
}));
System.out.println("传二个参数传统写法:" + twoInt);
// 以上代码简写形式,如下所示:
Integer twoIntAd = list.stream().map(UserInfo::getAge).collect(Collectors.reducing(0, (val1, val2) -> val1 + val2));
System.out.println("传二个参数简写形式写法:" + twoIntAd);
// 优雅的代码简写形式,如下所示:
Integer twoIA = list.stream().map(UserInfo::getAge).collect(Collectors.reducing(0, Integer::sum));
System.out.println("传二个参数优雅的代码简写写法:" + twoIA);
// 传三个参数
System.out.println("***********传三个参数*************");
Integer threeInt = list.stream().collect(Collectors.reducing(0, new Function<UserInfo, Integer>() {
@Override
public Integer apply(UserInfo userInfo) {
return userInfo.getAge();
}
}, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer val1, Integer val2) {
return val1 + val2;
}
}));
System.out.println("传三个参数传统写法:" + threeInt);
// 以上代码简写形式,如下所示:
Integer threeIntAd = list.stream().collect(Collectors.reducing(0, userInfo -> userInfo.getAge(), (val1, val2) -> val1 + val2));
System.out.println("传三个参数简写形式写法:" + threeIntAd);
// 优雅的代码简写形式,如下所示:
Integer threeIA = list.stream().collect(Collectors.reducing(0, UserInfo::getAge, Integer::sum));
System.out.println("传三个参数优雅的代码简写写法:" + threeIA);
}
}
以上代码运行结果,如下所示:
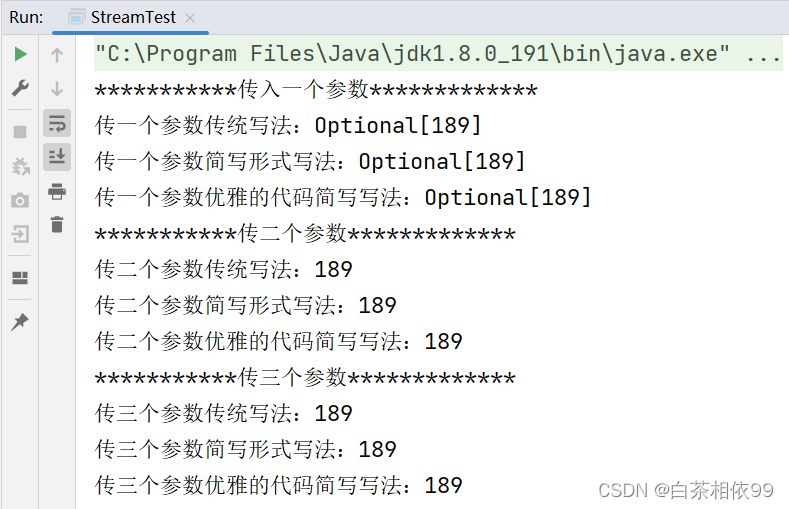
3、collectingAndThen()

【特别说明】:
collectingAndThen()方法由于不常用,简单介绍一下collectingAndThen()方法的两个参数,第一个参数为Collector类型,只要调用Collectors中的静态方法返回值皆为Collector类型,第二个参数为Function是一个函数式接口,new 一个Function函数式接口实现里面的方法即可。
【collectingAndThen()方法的二个参数】:
downstream – 一个收集器finisher – 应用于下游收集器最终结果的函数
测试代码,如下所示:
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 获取list集合中的所有名字,并且过滤掉张三、李四、王五
// stream API实现
List<String> strList = Stream.of("张三", "李四", "王五").collect(Collectors.toList());
List<String> collect = list.stream().map(UserInfo::getName).filter(e -> !strList.contains(e)).collect(Collectors.toList());
System.out.println("stream API实现写法:" + collect);
// Collectors API实现
List<String> filList = list.stream().collect(Collectors.collectingAndThen(
// 获取list集合中的所有名字
Collectors.mapping(UserInfo::getName, Collectors.toList()),
// 过滤掉张三、李四、王五
new Function<List<String>, List<String>>() {
@Override
public List<String> apply(List<String> stringList) {
return stringList.stream().filter(a -> !strList.contains(a)).collect(Collectors.toList());
}
}));
System.out.println("Collectors API实现传统写法:" + filList);
// 代码简写,如下所示:
List<String> filListAd = list.stream().collect(Collectors.collectingAndThen(
// 获取list集合中的所有名字
Collectors.mapping(UserInfo::getName, Collectors.toList()),
// 过滤掉张三、李四、王五
sList -> sList.stream().filter(str -> !strList.contains(str)).collect(Collectors.toList())));
System.out.println("Collectors API实现代码简写法:" + filListAd);
}
}
以上代码运行结果,如下所示:

(七)、综合案例演示
1、分组后聚合
需求:获取List<UserInfo>集合中根据UserInfo对象的性别进行分组,并且只返回UserInfo对象的姓名。代码如下所示:
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 根据性别分组取出姓名
Map<String, List<String>> listMap = list.stream().collect(Collectors.groupingBy(new Function<UserInfo, String>() {
@Override
public String apply(UserInfo userInfo) {
return userInfo.getSex();
}
}, Collectors.mapping(new Function<UserInfo, String>() {
@Override
public String apply(UserInfo userInfo) {
return userInfo.getName();
}
}, Collectors.toList())));
System.out.println("代码传统写法如下所示:" + listMap);
// 以上代码简化写法
Map<String, List<String>> listMapAd = list.stream().collect(Collectors.groupingBy(userInfo -> userInfo.getSex(), Collectors.mapping(userInfo -> userInfo.getName(), Collectors.toList())));
System.out.println("代码简化写法:" + listMapAd);
// 更优雅的代码简化写法
Map<String, List<String>> listMAd = list.stream().collect(Collectors.groupingBy(UserInfo::getSex, Collectors.mapping(UserInfo::getName, Collectors.toList())));
System.out.println("更优雅的代码简化写法:" + listMAd);
}
}以上代码运行结果,如下所示:

2、分组后计算
2.1、获取List<UserInfo>集合中根据UserInfo对象的性别进行分组,并且统计UserInfo对象的数量。代码如下所示:
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 获取List<UserInfo>集合中根据UserInfo对象的性别进行分组,并且统计UserInfo对象的数量。
Map<String, Long> mapCount = list.stream().collect(Collectors.groupingBy(new Function<UserInfo, String>() {
@Override
public String apply(UserInfo userInfo) {
return userInfo.getSex();
}
}, Collectors.counting()));
System.out.println("代码传统写法:" + mapCount);
// 以上代码简化写法
Map<String, Long> mapCountAd = list.stream().collect(Collectors.groupingBy(UserInfo::getSex, Collectors.counting()));
System.out.println("代码简化写法:" + mapCountAd);
// 更优雅的代码简化写法
Map<String, Long> mapCAd = list.stream().collect(Collectors.groupingBy(UserInfo::getSex, Collectors.counting()));
System.out.println("更优雅的代码简化写法:" + mapCAd);
}
}
以上代码运行结果,如下所示:

2.2、获取List<UserInfo>集合中根据UserInfo对象的性别进行分组,并且统计UserInfo对象中不同性别年龄的总和。代码如下所示:
import java.util.*;
import java.util.function.Function;
import java.util.function.ToIntFunction;
import java.util.stream.Collectors;
public class StreamTest {
public static void main(String[] args) {
List<UserInfo> list = UserInfo.dataList();
// 获取List<UserInfo>集合中根据UserInfo对象的性别进行分组,并且统计UserInfo对象中不同性别年龄的总和。
Map<String, Integer> mapSum = list.stream().collect(Collectors.groupingBy(new Function<UserInfo, String>() {
@Override
public String apply(UserInfo userInfo) {
return userInfo.getSex();
}
}, Collectors.summingInt(new ToIntFunction<UserInfo>() {
@Override
public int applyAsInt(UserInfo userInfo) {
return userInfo.getAge().intValue();
}
})));
System.out.println("代码传统写法:" + mapSum);
// 以上代码简化写法
Map<String, Integer> mapSumAd = list.stream().collect(Collectors.groupingBy(userInfo -> userInfo.getSex(), Collectors.summingInt(userInfo -> userInfo.getAge().intValue())));
System.out.println("代码简化写法:" + mapSumAd);
// 更优雅的代码简化写法
Map<String, Integer> mapSAd = list.stream().collect(Collectors.groupingBy(UserInfo::getSex, Collectors.summingInt(UserInfo::getAge)));
System.out.println("更优雅的代码简化写法:" + mapSAd);
}
}
以上代码运行结果,如下所示:

以上综合案例仅供参考,实际开发中可根据需求自由发挥!
















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









