



一.爬取数据时显示乱码
在爬取的时候有很多种乱码,我遇到的是类似ÉÌÆ·Áбí-Ó¢ÐÛÁªÃ˵À¾Û³Ç这种的,在查找资料后是以ISO 8859-1读取gbk导致的,最后解决办法是发送get请求后通过这个代码
MyHtml = response.text.encode('iso-8859-1').decode('gbk')就可以显示出来,乱码有很多种,其他更具体的需要查看其他资料,这里放一个具体乱码类型的表格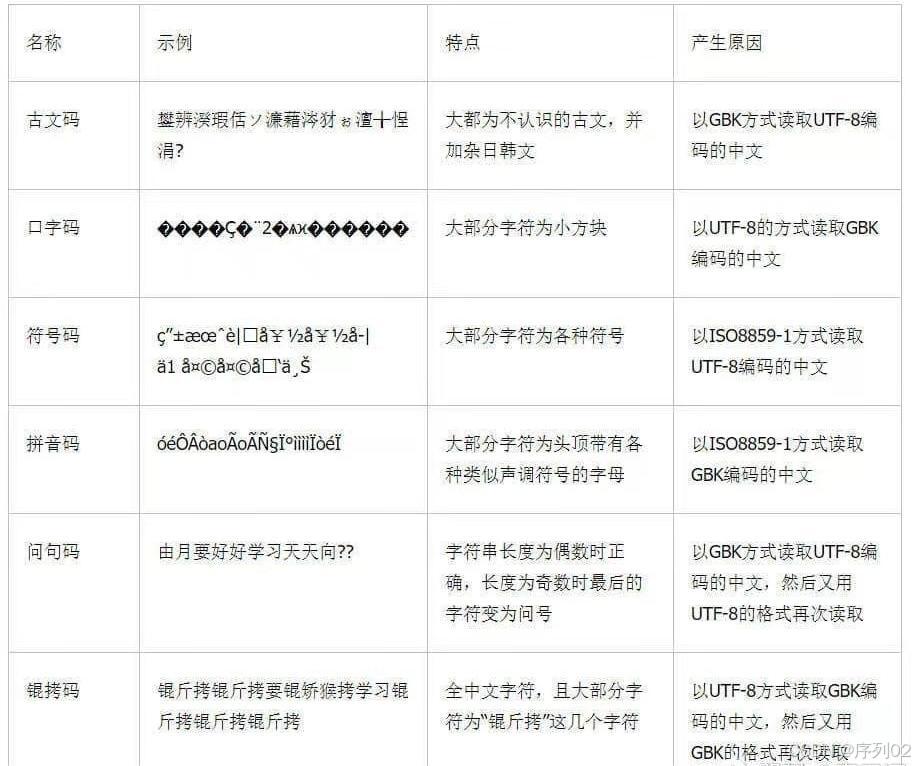
具体解决方案就需要自己在去查找了
二.显示动态数据
在爬取网页数据时遇到类似${x.beRepliedUser.userId}这样的表达式,这通常意味着这部分内容是由JavaScript动态生成的,而不是直接在HTML源代码中静态显示的。这种情况在现代web开发中非常常见,尤其是使用单页面应用(SPA)框架(如React, Vue, Angular)构建的网站。这里我是使用Selenium来解决的
这工具可以模拟浏览器的行为,包括执行JavaScript,因此可以获取到页面渲染后的完整内容。Selenium支持多种编程语言,包括Python。使用Selenium,你可以编写脚本来打开网页,等待JavaScript执行完毕,然后提取所需的数据。
下面是一个简单的例子
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 初始化WebDriver
driver = webdriver.Edge()
try:
# 访问初始页面
driver.get("url") #需要爬取的网页
# 初始化一个列表来保存数据
data = []
# 循环遍历页面
while True:
# 解析和提取当前页面的数据(这里只是示例,你需要根据页面结构编写具体的解析代码)
# 假设每个页面都有一个<strong>标签,我们提取它的文本
elements = driver.find_elements(By.TAG_NAME, "strong")
for element in elements:
data.append(element.text)
# 检查是否存在“下一页”链接
try:
# 找到“下一页”链接并点击
next_page_link = driver.find_element(By.LINK_TEXT, "下一页")
next_page_link.click()
# 等待页面加载完成(可选,取决于你的需求)
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.LINK_TEXT, "下一页"))
)
except Exception as e:
# 如果没有找到“下一页”链接,则跳出循环
print("没有更多页面")
for a in data:
print(a)
break
finally:
# 关闭WebDriver
driver.quit()
# 现在,data列表包含了从所有页面中提取的数据
# 你可以根据需要保存或处理这些数据这个例子里面是爬取该网站的多个页面,爬取名为strong标签里面的内容,并且通过
next_page_link = driver.find_element(By.LINK_TEXT, "下一页") next_page_link.click()
来查找点击下一页,实现多个页面的爬取,在没有下一页时结束爬取。

















 1677
1677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









