







public Page<Backlog> getEndListService(String loginName,Page<Backlog> page,String type) {
String endPoint = Backlog.getEndPoint() + "/ioa/services/ECS_COM_INF_IDaiBan"; // ws地址
String nameSpace = "urn:inv"; // 命名空间
Object[] objects = new Object[]{
"<PARAMS><USERID>"+loginName+"</USERID><PAGESIZE>"+page.getPageSize()+"</PAGESIZE><PAGEPARAMS><PAGEPARAM><TYPE>"+type+"</TYPE><PAGE>"+page.getPageNo()+"</PAGE></PAGEPARAM>"
};
List<Backlog> backlogs = null;
String count = null;
try {
String returnXml = null;
try {
returnXml = invokingService(endPoint, nameSpace, objects, "getDaiBanTasks");
logger.debug(returnXml);
org.dom4j.Document document = org.dom4j.DocumentHelper.parseText(returnXml);
org.dom4j.Element rootElt = document.getRootElement(); // ROOTVO根路径
org.dom4j.Node repCodeNode = rootElt.selectSingleNode("REPCODE"); // 返回结果码
if (repCodeNode == null) {
throw new Exception("returnXml节点<REPCODE>不存在");
}
String repCode = rootElt.selectSingleNode("REPCODE").getText();
org.dom4j.Node returnMessageNode = rootElt.selectSingleNode("RETURNMESSAGE"); // 结果信息
if (returnMessageNode == null) {
throw new Exception("returnXml节点<RETURNMESSAGE>不存在");
}
if (!repCode.equals("0000")) { // 非成功返回,抛出异常
throw new Exception("返回失败,结果码" + repCode);
}
/*列表总数*/
org.dom4j.Node DATA_TOTAL = rootElt.selectSingleNode("/DATA/DATA_TOTAL");
if (DATA_TOTAL == null) {
throw new Exception("returnXml节点<DATA_TOTAL>不存在");
}
count = DATA_TOTAL.getText();
page.setTotalCount(Long.parseLong(count));
/*列表内容*/
org.dom4j.Node BACKLOGS = rootElt.selectSingleNode("/DATA/BACKLOGS");
if (BACKLOGS != null) {
backlogs = new ArrayList<Backlog>();
try {
List<org.dom4j.Node> nodes = BACKLOGS.selectNodes("BACKLOG");
for(org.dom4j.Node node :nodes){
Backlog backlog = new Backlog();
backlog.setBacklogTitle(node.selectSingleNode("BACKLOG_TITLE").getText());
backlog.setBacklogRes(node.selectSingleNode("BACKLOG_WORKITEMID").getText());
backlogs.add(backlog);
}
page.setResult(backlogs);
} catch (Exception e) {
e.getStackTrace();
}
}
} catch (Exception e) {
logger.error(returnXml);
logger.error("系统解析出错:" + e.getMessage());
}
} catch (Exception e) {
logger.error("系统解析出错:" + e.getMessage());
}
return page;
}
dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的。dom4j是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件,可以在SourceForge上找到它.
对主流的Java XML API进行的性能、功能和易用性的评测,dom4j无论在那个方面都是非常出色的。如今你可以看到越来越多的Java软件都在使用dom4j来读写XML,例如hibernate,包括sun公司自己的JAXM也用了Dom4j。
使用Dom4j开发,需下载dom4j相应的jar文件
1.官网下载: http://www.dom4j.org/dom4j-1.6.1/
2.dom4j是sourceforge.NET上的一个开源项目,因此可以到http://sourceforge.Net/projects/dom4j下载其最新版.
对于下载的zip文件进行解压后的效果如下:
打开dom4j-1.6.1的解压文件
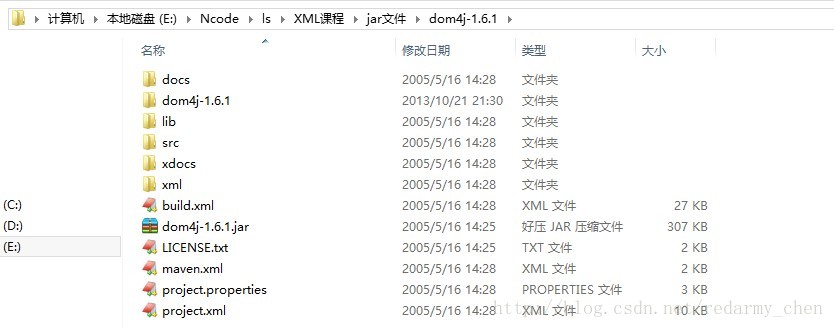
在这里可以看到有docs帮助的文件夹,也有需要使用dom4j解析xml文件的dom4j-1.6.1.jar文件.我们只需要把dom4j-1.6.1.jar文件构建到我们开发的项目中就可以使用dom4j开发了.
下面我以Myeclipse创建Java项目的构建方法为例说明.
首先创建一个demo项目,在demo项目中创建一个lib文件,把dom4j-1.6.1.jar文件拷贝到lib中,然后右键dom4j-1.6.1jar文件

点击Add to Build Path即可构建到项目中去了.
备注:如果进行的是web项目开发,我们只需要把它拷贝到web-inf/lib中去即可,会自动构建到web项目中.
在项目开发的过程中可以参考docs文件夹的(帮助文档),找到index.html打开,点击Quick start可以通过帮助文档进行学习 dom4j进行xml的解析.
下面我对我认为api中重要的方法进行翻译说明如下:
一、DOM4j中,获得Document对象的方式有三种:
二、节点对象操作的方法
三、节点对象的属性方法操作
四、将文档写入XML文件
五、字符串与XML的转换
六、案例(解析sida.xml文件并对其进行curd的操作)
1.sida.xml描述四大名著的操作,文件内容如下
2.解析类测试操作
自己适当注释部分代码观察运行效果,反复练习,希望你对dom4j有进一步的了解.
七、字符串与XML互转换案例

Dom4j可以获取Node和Element 两种,但是两种的区辨到底是什么,我有些迷惑,在网上找到了一些比较合理的解释,
Node是节点,一个属性、一段文字、一个注释等都是节点,而Element是元素,是比较完整的一个xml的元素,即我们口头上说的xml“结点”(此处故意使用“结”字,以示与“节点”Node区别),我觉得这点和HTNL中DOM很像,比如说<div id="ss"></div>其中它由元素节点、属性节点和文本节点组成,但是它是一个div元素,
我们平时在开发中经常大都使用的是Element,我们怎样把Node转为Element呢,















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









