







什么是Kafka
Kafka起初是由LinkedIn 公司采用Scala语言开发的一一个多分区、多副本且基于ZooKeeper协调的分布式消息系统,现已被捐献给Apache基金会。目前Kafka已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Storm、Spark、Flink等都支持与Kafka集成。
Kafka为什么会越来越受欢迎
Kafka受欢迎的原因在于它扮演的三大角色:
消息系统: afka 和传统的消息系统(也称作消息中间件〉都具备系统解稿、冗余存储、流量削峰、缓冲、异步通信、扩展性、 可恢复性等功能。与此同时, Kafka供了大多数消息系统难以实现的消息 序性保障及回溯消费的功能
存储系统: Kafka 把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险 也正是得益于 Kafka 的消息持久化功能和多副本机制,我们可以把 Kafka 作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为“永久”或启用主题的日志压缩功能即可
流式处理平台: Kafka 不仅为每个流行的流式处理框架提供了可靠的数据来源,提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
Kafka思维导图
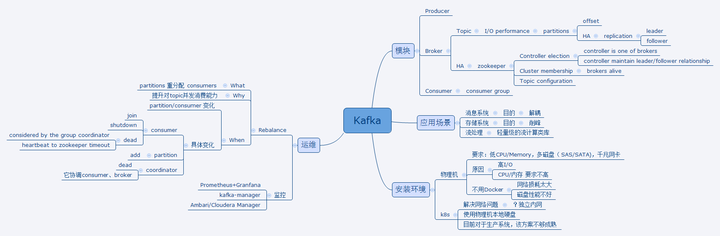
编辑切换为居中
添加图片注释,不超过 140 字(可选)
在这个数据科学和分析是一个大问题的世界里,捕获数据到数据库和实时分析系统是一件大事。但是Kafka可以承受这种剧烈的使用情况,所以说Kafka是一个大成就。下面我就为大家介绍一份Kafka的实战PDF。
看完这份PDF能学到什么:本书主要阐述了Kafka中生产者客户端、消费者客户端、主题与分区、日志存储、原理解析、监控管理、应用扩展及流式计算等内容。
◆基础篇介绍Kafka的基础概念、生产者、消费者,以及主题与分区。
◆原理篇包括对日志存储、协议设计、控制器、组协调器、事务、-致性、可靠性等内容的探究。
◆扩展篇从应用扩展层面来做讲解,包括监控、应用工具、应用扩展(延时队列、重试队列、死信队列、消息轨迹等)、与Spark的集成等。
这本Kafka实战PDF总共有12个章节,主要内容如下:
第1章 初识Kafka

编辑
添加图片注释,不超过 140 字(可选)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









