







Java的序列化简介
Java 提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。
将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化,也就是说,对象的类型信息、对象的数据,还有对象中的数据类型可以用来在内存中新建对象。
序列化应该用在哪
如果单从序列化的简介上来看,很容易理解。曾经也存在很多不解,因为:
- 在业务中,存储的数据方式,比如:文件、数据库、ftp服务 等。之前在使用的时候,只是需要了解如何保存,如何下载。
- 在传输数据中,controll->service->dao的传输方式中,一般只涉及POJO的类转换, 基本类型数据或集合类型数据的组装、遍历等等。
- 在三方插件中,比如elasticsearch、redis、kafka等,更多的是借助api的存储和传递 等等
初时序列化的用途
业务场景:张某某本来在A城市工作,他的档案归A城市管理,某一天张某某想去B城市工作了,他要将档案信息从A城市调到B城市
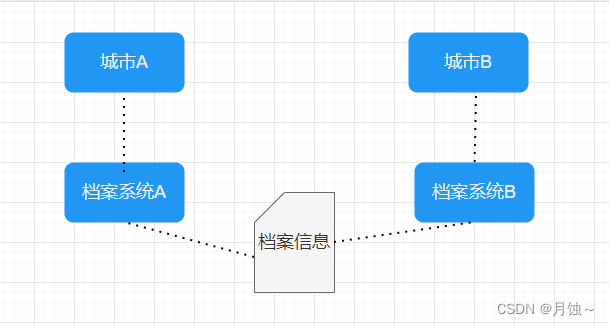
这时疑问的是,张某某在城市A在办理档案转移手续时,城市A直接调用城市B的档案信息接口转移进去不就可以。
但是可能存在的问题,如果档案信息比较复杂,涉及的内容比较多,如何保证接口的正确性,如何保证网络的畅通性。这时学到了一个新的业务词汇:报文。
将双方约定的档案信息按照报文信息填充,城市A发送报文至中心服务,中心服务负责转发报文至城市B。
相对于城市A来说, 那么A给B的过程可以称之为:序列化,B给A的过程称之为:反序列化。
去除不想序列化的内容
序列化的内容,一般是根据业务场景约定好的, 即你想序列化哪些内容,反序列化的时候你想读到哪些内容。
不想序列化的内容:
- 不在序列化中的bean中出现
- 或者不想序列化的属性前增加transient 修饰
控制序列化的版本
如果A和B之前是好朋友,他们用了一个serialVersionUID=1L的暗号,作为他们的通信识别 。某一天关系破裂了,修改serialVersionUID的值,那么就代码他们的序列化关系断了。
实战用途
当你的脑海中有了序列化的用途时, 那么在你的实际业务中可以通过序列化来完成你需要的业务场景。
在我的程序中,如何想要保存程序关闭时树的展开、收起形状,那么我可以通过序列化的操作来完成。
相比于遍历树的每个节点,获知树的形态属性并保存,通过递归来回显保存时的树的形状, 序列化或许减少了许多工作。

拓展自己的脑海,让自己作为一个看的更远的智者。















 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









