







 本文介绍了生产者消费者模式的基本概念、优点,并通过Java代码展示了如何避免多线程假死问题。讨论了在实现过程中可能出现的问题及解决方案,包括使用阻塞队列提升并发性能。
本文介绍了生产者消费者模式的基本概念、优点,并通过Java代码展示了如何避免多线程假死问题。讨论了在实现过程中可能出现的问题及解决方案,包括使用阻塞队列提升并发性能。
昨天去了一家游戏公司复试,这就是一道面试题目,要求用Java基础实现生产者消费者模式(机试),当时准确地说只完成了一半。开启两个线程时没什么问题,但后来面试官要求开启20个线程,结果就出现了假死。当时也没弄懂是什么原因导致假死,回来才弄懂!1、什么是生产者消费者模式?
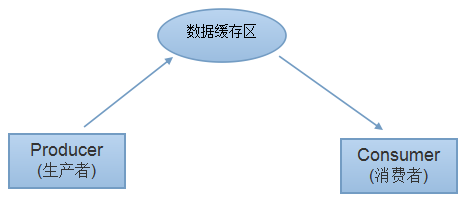
在实际的开发工作中,也会有这样的情节:某个模块负责生产数据(产品),而这些数据由另一个模块负责消费(此处的模块是广义的,可以是类、方法、线程、进程等)。在这里,负责生产数据的模块就是生产者,而负责处理这些数据的消费者,在生产者与消费者之间加一个数据的缓存区,生成着负责向其中放产品,而消费者从其中取产品,这样就构成了生产者消费者模式。如图:
2、生产者消费者模式的优点
(1)解耦
假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。
举个例子,我们去邮局投递信件,如果不使用邮筒(也就是缓冲区),你必须得把信直接交给邮递员。有同学会说,直接给邮递员不是挺简单的嘛?其实不简单,你必须得认识谁是邮递员,才能把信给他(光凭身上穿的制服,万一有人假冒,就惨了)。这就产生和你和邮递员之间的依赖(相当于生产者和消费者的强耦合)。万一哪天邮递员换人了,你还要重新认识一下(相当于消费者变化导致修改生产者代码)。而邮筒相对来说比较固定,你依赖它的成本就比较低(相当于和缓冲区之间的弱耦合)。
(2)支持并发
由于生产者与消费者是两个独立的并发体,他们之间是用缓冲区作为桥梁连接,生产者只需要往缓冲区里丢数据,就可以继续生产下一个数据,而消费者只需要从缓冲区了拿数据即可,这样就不会因为彼此的处理速度而发生阻塞。
接上面的例子,如果我们不使用邮筒,我们就得在邮局等邮递员,直到他回来,我们把信件交给他,这期间我们啥事儿都不能干(也就是生产者阻塞),或者邮递员得挨家挨户问,谁要寄信(相当于消费者轮询)。
(3)支持忙闲不均
缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。当数据制造快的时候
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9807
9807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









