







usage:
scrapy crawl first
一、抓取效果
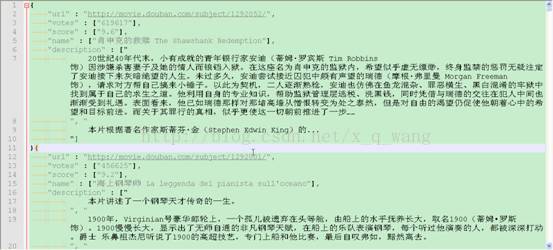
二、源码下载
http://download.csdn.net/detail/wxq714586001/8821149
三、总结
done:
1、解决了将unicode字符串(类似于‘\uxxx\n\t\t’)转换为实际的文字,困扰了很久。
2、用正则表达式替换字符串。
3、scrapy的基本使用方法。
todo:
1、爬了一段时间就被豆瓣禁了。
2、存储了一些无效的链接。
usage:
scrapy crawl first
一、抓取效果
二、源码下载
http://download.csdn.net/detail/wxq714586001/8821149
三、总结
done:
1、解决了将unicode字符串(类似于‘\uxxx\n\t\t’)转换为实际的文字,困扰了很久。
2、用正则表达式替换字符串。
3、scrapy的基本使用方法。
todo:
1、爬了一段时间就被豆瓣禁了。
2、存储了一些无效的链接。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 319
319





