







本小结仅仅只为考试,请为了学习的小伙伴不要太过参考。
数据结构讲了什么?
1. 什么是数据结构。
2. 链表
3. 队列和栈
4. 树
a. 二叉树
b. 平衡二叉树
c. B+树
d. B-树
二叉树遍历:先序、后序、中序遍历。
满二叉树
所有的分支结点都存在左子树和右子树,并且所有的叶子结点都在同一层上,这样就是满二叉树。就是完美圆满的意思,关键在于树的平衡。
根据满二叉树的定义,得到其特点为:
- 叶子只能出现在最下一层。
- 非叶子结点度一定是2.
- 在同样深度的二叉树中,满二叉树的结点个数最多,叶子树最多。
3、完全二叉树
对一棵具有n个结点的二叉树按层序排号,如果编号为i的结点与同样深度的满二叉树编号为i结点在二叉树中位置完全相同,就是完全二叉树。满二叉树必须是完全二叉树,反过来不一定成立。
其中关键点是按层序编号,然后对应查找。
B树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:
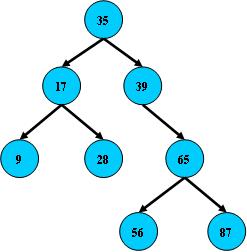
B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;
否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入
右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树
的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构
(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:
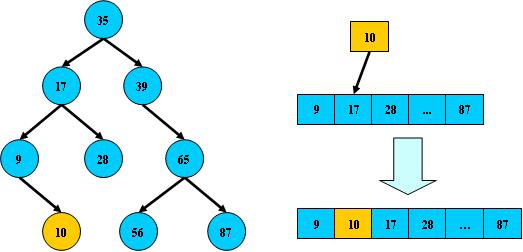
但B树在经过多次插入与删除后,有可能导致不同的结构:
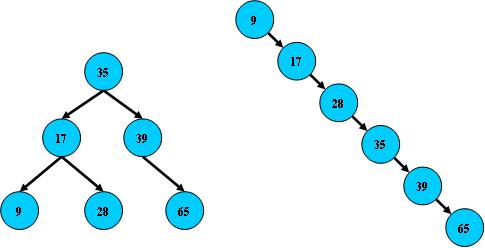
右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的
树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就
是所谓的“平衡”问题;
实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树
结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的
策略;
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的
子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
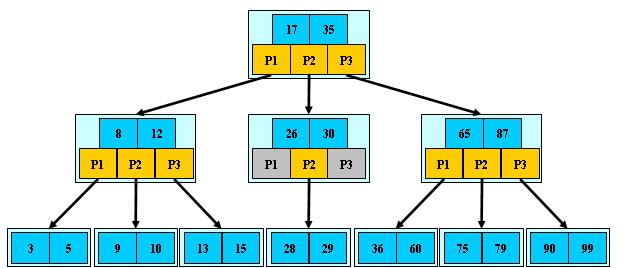
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果
命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为
空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少
利用率,其最底搜索性能为:
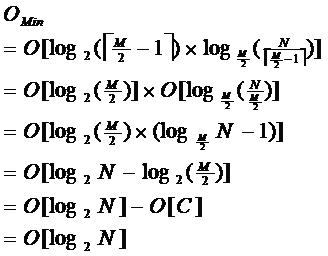
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占
M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树
(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)
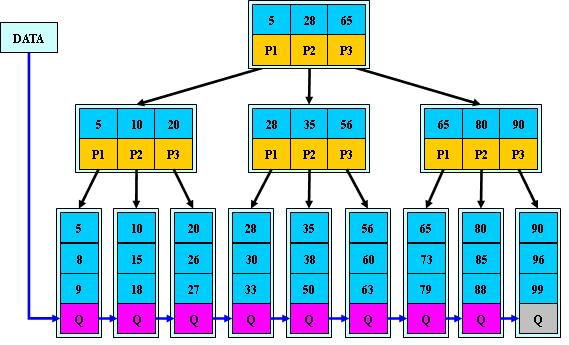
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在
非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好
是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储
(关键字)数据的数据层;
4.更适合文件索引系统;
根据数据元素间关系的不同特性,通常有下列四类基本的结构:⑴集合结构。该结构的数据元素间的关系是“属于同一个集合”。⑵线性结构。该结构的数据元素之间存在着一对一的关系。⑶树型结构。该结构的数据元素之间存在着一对多的关系。⑷图形结构。该结构的数据元素之间存在着多对多的关系,也称网状结构。
常用数据结构:
数组
在程序设计中,为了处理方便,把具有相同类型的若干变量按有序的形式组织起来。这些按序排列的同类数据元素的集合称为数组。在C语言中,数组属于构造数据类型。一个数组可以分解为多个数组元素,这些数组元素可以是基本数据类型或是构造类型。因此按数组元素的类型不同,数组又可分为数值数组、字符数组、指针数组、结构数组等各种类别。
栈
是只能在某一端插入和删除的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
队列
一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列是按照“先进先出”或“后进后出”的原则组织数据的。队列中没有元素时,称为空队列。
链表
是一种物理存储单元上非连续、非顺序的存储结构,它既可以表示线性结构,也可以用于表示非线性结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
树
是包含n(n>0)个结点的有穷集合K,且在K中定义了一个关系N,N满足以下条件:
(1)有且仅有一个结点 K0,他对于关系N来说没有前驱,称K0为树的根结点。简称为根(root)。
(2)除K0外,K中的每个结点,对于关系N来说有且仅有一个前驱。
(3)K中各结点,对关系N来说可以有m个后继(m>=0)。
图
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
堆
在计算机科学中,堆是一种特殊的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。
队列、栈有很多模板,在STL中就可以找到。
List
栈的简单实现:
#include<iostream>
#include<stdlib.h>
using namespace std;
#define MAXSIZE 0xffff
template<classtype>
class my_stack
{
int top;
type*my_s;
int maxsize;
public:
my_stack():top(-1),maxsize(MAXSIZE)
{
my_s=newtype[maxsize];
if(my_s==NULL)
{
cerr<<"动态存储分配失败!"<<endl;
exit(1);
}
}
my_stack(int size):top(-1),maxsize(size)
{
my_s=newtype[maxsize];
if(my_s==NULL)
{
cerr<<"动态存储分配失败!"<<endl;
exit(1);
}
}
~my_stack()
{
delete[] my_s;
}
//是否为空
bool Empty();
//压栈
void Push(typetp);
//返回栈顶元素
typeTop();
//出栈
void Pop();
//栈大小
int Size();
};
template<classtype>
bool my_stack<type>::Empty()
{
if(top==-1){
returntrue;
}
else
returnfalse;
}
template<classtype>
typemy_stack<type>::Top()
{
if(top!=-1)
{
return my_s[top];
}
else
{
cout<<"栈空\n";
exit(1);
}
}
template<classtype>
void my_stack<type>::Push(typetp)
{
if(top+1<maxsize)
{
my_s[++top]=tp;
}
else
{
cout<<"栈满\n";
exit(1);
}
}
template<classtype>
void my_stack<type>::Pop()
{
if(top>=0)
{
top--;
}
else
{
cout<<"栈空\n";
exit(1);
}
}
template<classtype>
int my_stack<type>::Size()
{
return top+1;
}
队列实现:
/* 顺序队列接口定义头文件*/
#define true 1
#define false 0
/* 队的最大长度 */
#define MAX_QUEUE_SIZE 100
/* 队列的数据类型 */
typedefint datatype;
/* 静态链的数据结构 */
typedefstructqueue{
datatype sp_queue_array[MAX_QUEUE_SIZE];
/*队头 */
int front;
/*队尾 */
int rear;
}sp_queue;
/* 静态顺序链的接口定义 */
/* 静态链的初始化 */
sp_queue queue_init();
/* 判断队列是否为空,若为空
*返回true
*否则返回false
*/
int queue_empty(sp_queue q);
/* 插入元素e为队q的队尾新元素
*插入成功返回true
*队满返回false
*/
int queue_en(sp_queue *q, datatype e);
/* 队头元素出队
*用e返回出队元素,并返回true
*若队空返回false
*/
int queue_de(sp_queue *q, datatype *e);
/* 清空队 */
void queue_clear(sp_queue *q);
/* 获得队头元素
*队列非空,用e返回队头元素,并返回true
*否则返回false
*/
int get_front(sp_queue, datatype *e );
/* 获得队长 */
int queue_len(sp_queue q);
/* 遍历队 */
void queue_traverse(sp_queue q,void(*visit)(sp_queue q));
void visit(sp_queue s);
/* 接口实现文件 */
#include<stdio.h>
#include<stdlib.h>
#include"sp_queue.h"
sp_queue queue_init()
{
sp_queue q;
q.front = q.rear = 0;
return q;
}
int queue_empty(sp_queue q)
{
return q.front == q.rear;
}
int queue_en(sp_queue *q, datatype e)
{
/*队满 */
if (q -> rear == MAX_QUEUE_SIZE)
returnfalse;
/*入队 */
q -> sp_queue_array[q -> rear] = e;
printf("q.sp_queue_array[%d]=%d\n", q -> rear, e);
q -> rear += 1;
returntrue;
}
int queue_de(sp_queue *q, datatype *e)
{
/*队空 */
if(queue_empty(*q))
returnfalse;
/*出队 */
q -> rear -= 1;
*e = q -> sp_queue_array[q -> rear];
returntrue;
}
void queue_clear(sp_queue *q)
{
q -> front = q -> rear = 0;
}
int get_front(sp_queue q, datatype *e)
{
/*队空 */
if(q.front == q.rear)
returnfalse;
/*获取队头元素 */
*e = q.sp_queue_array[q.front];
returntrue;
}
int queue_len(sp_queue q)
{
return (q.rear - q.front);
}
void queue_traverse(sp_queue q,void (*visit)(sp_queue q))
{
visit(q);
}
void visit(sp_queue q)
{
/*队空 */
if (q.front == q.rear)
printf("队列为空\n");
int temp = q.front;
while(temp != q.rear)
{
printf("%d ",q.sp_queue_array[temp]);
temp += 1;
}
printf("\n");
}















 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









