







背景
本人想学习操作系统的知识,现在最流行的操作系统就是linux,所以这里选择研究linux-0.11版本,这里会结合赵炯博士的《linux-0.11深入解析》
概念
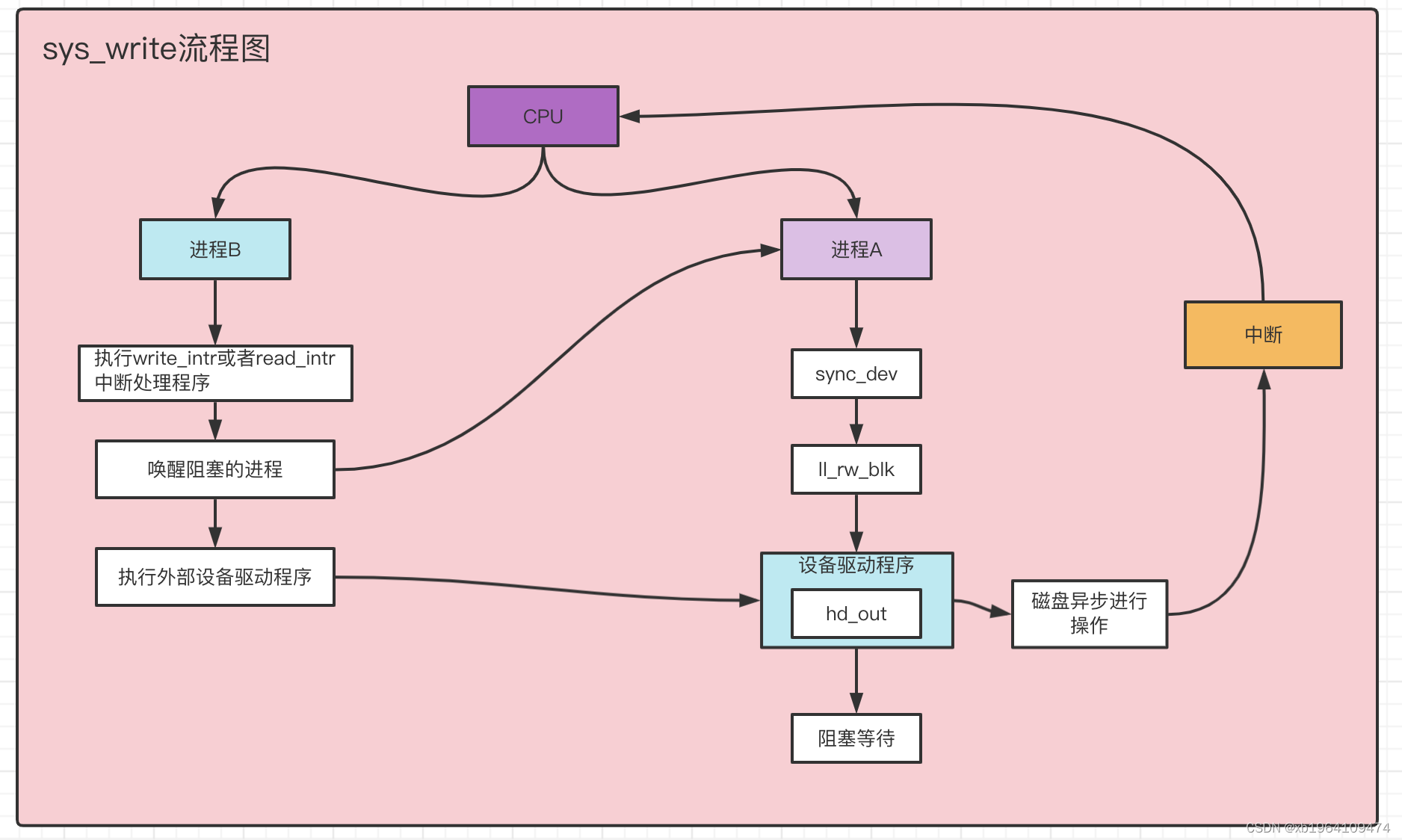
sys_write是系统调用函数,对磁盘中文件进行写操作
流程
源码
sys_write
写文件系统调用
// 参数fd是文件句柄,buf是用户缓冲区,count是欲写字节数。
int sys_write(unsigned int fd,char * buf,int count)
{
struct file * file;
struct m_inode * inode;
// 同样地,我们首先判断函数参数的有效性。若果进程文件句柄值大于程序最多打开文件数
// NR_OPEN,或者需要写入的字节数小于0,或者该句柄的文件结构指针为空,则返回出错码
// 并退出。如果需读取字节数count等于0,则返回0退出。
if (fd>=NR_OPEN || count <0 || !(file=current->filp[fd]))
return -EINVAL;
if (!count)
return 0;
// 然后验证存放数据的缓冲区内存限制。并取文件的i节点。用于根据该i节点属性,分别调
// 用相应的读操作函数。若是管道文件,并且是写管道文件模式,则进行写管道操作,若成
// 功则返回写入的字节数,否则返回出错码退出。如果是字符设备文件,则进行写字符设备
// 操作,返回写入的字符数退出。如果是块设备文件,则进行块设备写操作,并返回写入的
// 字节数退出。若是常规文件,则执行文件写操作,并返回写入的字节数,退出。
inode=file->f_inode;
if (inode->i_pipe)
return (file->f_mode&2)?write_pipe(inode,buf,count):-EIO;
if (S_ISCHR(inode->i_mode))
return rw_char(WRITE,inode->i_zone[0],buf,count,&file->f_pos);
if (S_ISBLK(inode->i_mode))
return block_write(inode->i_zone[0],&file->f_pos,buf,count);
if (S_ISREG(inode->i_mode))
return file_write(inode,file,buf,count);
// 执行到这里,说明我们无法判断文件的属性。则打印节点文件属性,并返回出错码退出。
printk("(Write)inode->i_mode=%06o\n\r",inode->i_mode);
return -EINVAL;
}
里面我们主要研究块设备操作。
block_write
数据块写函数 - 向指定设备从给定偏移出写入制定长度数据。
// 参数:dev - 设备号; pos - 设备文件中偏移量指针;buf - 用户空间中缓冲区地址;
// count - 要传送的字节数
// 返回已写入字节数。若没有写入任何字节或出错,则返回出错号。
// 对于内核来说,写操作是向高速缓冲区中写入数据。什么时候数据最终写入设备是由高
// 速缓冲管理程序决定并处理的。另外,因为块设备是以块为单位进行读写,因此对于写
// 开始位置不处于块起始处时,需要先将开始字节所在的整个块读出,然后将需要写的数
// 据从写开始处填写满该块,再将完整的一块数据写盘(即交由高速缓冲程序去处理)。
int block_write(int dev, long * pos, char * buf, int count)
{
// 首先由文件中位置pos换算成开始读写盘快的块序号block,并求出需写第1字节在该
// 块中的偏移位置offset.
int block = *pos >> BLOCK_SIZE_BITS; // pos所在文件数据块号
int offset = *pos & (BLOCK_SIZE-1); // pos在数据块中偏移值
int chars;
int written = 0;
struct buffer_head * bh;
register char * p; // 局部寄存器变量,被存放在寄存器中
// 然后针对要写入的字节数count,循环执行以下操作,知道数据全部写入。在循环执行
// 过程中,先计算在当前处理的数据块中可写入的字节数。如果写入的字节数填不满一块,
// 那么就只需写count字节。如果正要写1块数据内容,则直接申请1块高速缓冲块,并把
// 用户数据放入即可。否则就需要读入将被写入部分数据的数据块,并预读下两块数据。
// 然后将块号递增1,为下次操作做好准备。如果缓冲块操作失败,则返回已写字节数,
// 如果没有写入任何字节,则返回出错号(负数).
while (count>0) {
chars = BLOCK_SIZE - offset;
if (chars > count)
chars=count;
if (chars == BLOCK_SIZE)
bh = getblk(dev,block);
else
bh = breada(dev,block,block+1,block+2,-1);
block++;
if (!bh)
return written?written:-EIO;
// 接着先把指针p指向读出数据的缓冲块中开始写入数据的位置处。若最后一次循环写入
// 的数据不足一块,则需从块开始处填写(修改)所需的字节,因此这里需预先设置offset
// 为零。此后将文件中偏移指针pos前移此次将要写的字节数chars,并累加这些要写的
// 字节数到统计值written中,再把还需要写的计数值count减去此次要写的字节数chars.
// 然后我们从用户缓冲区复制chars个字节到p指向的高速缓冲中开始写入的位置处。复制
// 完后就设置该缓冲区块已修改标志,并释放该缓冲区(也即该缓冲区引用计数递减1)。
p = offset + bh->b_data;
offset = 0;
*pos += chars;
written += chars; // 累计写入字节数
count -= chars;
while (chars-->0)
*(p++) = get_fs_byte(buf++);
bh->b_dirt = 1;
brelse(bh);
}
return written;
}
getblk
取高速缓冲中指定的缓冲块
// 检查指定(设备号和块号)的缓冲区是否已经在高速缓冲中。如果指定块已经在
// 高速缓冲中,则返回对应缓冲区头指针退出;如果不在,就需要在高速缓冲中设置一个
// 对应设备号和块好的新项。返回相应的缓冲区头指针。
struct buffer_head * getblk(int dev,int block)
{
struct buffer_head * tmp, * bh;
repeat:
// 搜索hash表,如果指定块已经在高速缓冲中,则返回对应缓冲区头指针,退出。
if ((bh = get_hash_table(dev,block)))
return bh;
// 扫描空闲数据块链表,寻找空闲缓冲区。
// 首先让tmp指向空闲链表的第一个空闲缓冲区头
tmp = free_list;
do {
// 如果该缓冲区正被使用(引用计数不等于0),则继续扫描下一项。对于
// b_count = 0的块,即高速缓冲中当前没有引用的块不一定就是干净的
// (b_dirt=0)或没有锁定的(b_lock=0)。因此,我们还是需要继续下面的判断
// 和选择。例如当一个任务该写过一块内容后就释放了,于是该块b_count()=0
// 但b_lock不等于0;当一个任务执行breada()预读几个块时,只要ll_rw_block()
// 命令发出后,它就会递减b_count; 但此时实际上硬盘访问操作可能还在进行,
// 因此此时b_lock=1, 但b_count=0.
if (tmp->b_count)
continue;
// 如果缓冲头指针bh为空,或者tmp所指缓冲头的标志(修改、锁定)权重小于bh
// 头标志的权重,则让bh指向tmp缓冲块头。如果该tmp缓冲块头表明缓冲块既
// 没有修改也没有锁定标志置位,则说明已为指定设备上的块取得对应的高速
// 缓冲块,则退出循环。否则我们就继续执行本循环,看看能否找到一个BANDNESS()
// 最小的缓冲块。
if (!bh || BADNESS(tmp)<BADNESS(bh)) {
bh = tmp;
if (!BADNESS(tmp))
break;
}
/* and repeat until we find something good */
} while ((tmp = tmp->b_next_free) != free_list);
// 如果循环检查发现所有缓冲块都正在被使用(所有缓冲块的头部引用计数都>0)中,
// 则睡眠等待有空闲缓冲块可用。当有空闲缓冲块可用时本进程会呗明确的唤醒。
// 然后我们跳转到函数开始处重新查找空闲缓冲块。
if (!bh) {
sleep_on(&buffer_wait);
goto repeat;
}
// 执行到这里,说明我们已经找到了一个比较合适的空闲缓冲块了。于是先等待该缓冲区
// 解锁。如果在我们睡眠阶段该缓冲区又被其他任务使用的话,只好重复上述寻找过程。
wait_on_buffer(bh);
if (bh->b_count)
goto repeat;
// 如果该缓冲区已被修改,则将数据写盘,并再次等待缓冲区解锁。同样地,若该缓冲区
// 又被其他任务使用的话,只好再重复上述寻找过程。
while (bh->b_dirt) {
sync_dev(bh->b_dev);
wait_on_buffer(bh);
if (bh->b_count)
goto repeat;
}
/* NOTE!! While we slept waiting for this block, somebody else might */
/* already have added "this" block to the cache. check it */
// 在高速缓冲hash表中检查指定设备和块的缓冲块是否乘我们睡眠之际已经被加入
// 进去。如果是的话,就再次重复上述寻找过程。
if (find_buffer(dev,block))
goto repeat;
/* OK, FINALLY we know that this buffer is the only one of it's kind, */
/* and that it's unused (b_count=0), unlocked (b_lock=0), and clean */
// 于是让我们占用此缓冲块。置引用计数为1,复位修改标志和有效(更新)标志。
bh->b_count=1;
bh->b_dirt=0;
bh->b_uptodate=0;
// 从hash队列和空闲队列块链表中移出该缓冲区头,让该缓冲区用于指定设备和
// 其上的指定块。然后根据此新的设备号和块号重新插入空闲链表和hash队列新
// 位置处。并最终返回缓冲头指针。
remove_from_queues(bh);
bh->b_dev=dev;
bh->b_blocknr=block;
insert_into_queues(bh);
return bh;
}
sync_dev
对指定设备进行高速缓冲数据与设备上数据的同步操作
// 该函数首先搜索高速缓冲区所有缓冲块。对于指定设备dev的缓冲块,若其数据已经
// 被修改过就写入盘中(同步操作)。然后把内存中i节点表数据写入 高速缓冲中。之后
// 再对指定设备dev执行一次与上述相同的写盘操作。
int sync_dev(int dev)
{
int i;
struct buffer_head * bh;
// 首先对参数指定的设备执行数据同步操作,让设备上的数据与高速缓冲区中的数据
// 同步。方法是扫描高速缓冲区中所有缓冲块,对指定设备dev的缓冲块,先检测其
// 是否已被上锁,若已被上锁就睡眠等待其解锁。然后再判断一次该缓冲块是否还是
// 指定设备的缓冲块并且已修改过(b_dirt标志置位),若是就对其执行写盘操作。
// 因为在我们睡眠期间该缓冲块有可能已被释放或者被挪作他用,所以在继续执行前
// 需要再次判断一下该缓冲块是否还是指定设备的缓冲块。
bh = start_buffer;
for (i=0 ; i<NR_BUFFERS ; i++,bh++) {
if (bh->b_dev != dev) // 不是设备dev的缓冲块则继续
continue;
wait_on_buffer(bh); // 等待缓冲区解锁
if (bh->b_dev == dev && bh->b_dirt)
ll_rw_block(WRITE,bh);
}
// 再将i节点数据吸入高速缓冲。让i姐电表inode_table中的inode与缓冲中的信息同步。
sync_inodes();
// 然后在高速缓冲中的数据更新之后,再把他们与设备中的数据同步。这里采用两遍同步
// 操作是为了提高内核执行效率。第一遍缓冲区同步操作可以让内核中许多"脏快"变干净,
// 使得i节点的同步操作能够高效执行。本次缓冲区同步操作则把那些由于i节点同步操作
// 而又变脏的缓冲块与设备中数据同步。
bh = start_buffer;
for (i=0 ; i<NR_BUFFERS ; i++,bh++) {
if (bh->b_dev != dev)
continue;
wait_on_buffer(bh);
if (bh->b_dev == dev && bh->b_dirt)
ll_rw_block(WRITE,bh);
}
return 0;
}
ll_rw_block
void ll_rw_block(int rw, struct buffer_head * bh)
{
unsigned int major;
if ((major=MAJOR(bh->b_dev)) >= NR_BLK_DEV ||
!(blk_dev[major].request_fn)) {
printk("Trying to read nonexistent block-device\n\r");
return;
}
make_request(major,rw,bh);
}
make_request
static void make_request(int major,int rw, struct buffer_head * bh)
{
struct request * req;
int rw_ahead;
/* WRITEA/READA is special case - it is not really needed, so if the */
/* buffer is locked, we just forget about it, else it's a normal read */
if ((rw_ahead = (rw == READA || rw == WRITEA))) {
if (bh->b_lock)
return;
if (rw == READA)
rw = READ;
else
rw = WRITE;
}
if (rw!=READ && rw!=WRITE)
panic("Bad block dev command, must be R/W/RA/WA");
lock_buffer(bh);
if ((rw == WRITE && !bh->b_dirt) || (rw == READ && bh->b_uptodate)) {
unlock_buffer(bh);
return;
}
repeat:
/* we don't allow the write-requests to fill up the queue completely:
* we want some room for reads: they take precedence. The last third
* of the requests are only for reads.
*/
if (rw == READ)
req = request+NR_REQUEST;
else
req = request+((NR_REQUEST*2)/3);
/* find an empty request */
while (--req >= request)
if (req->dev<0)
break;
/* if none found, sleep on new requests: check for rw_ahead */
if (req < request) {
if (rw_ahead) {
unlock_buffer(bh);
return;
}
sleep_on(&wait_for_request);
goto repeat;
}
/* fill up the request-info, and add it to the queue */
req->dev = bh->b_dev;
req->cmd = rw;
req->errors=0;
req->sector = bh->b_blocknr<<1;
req->nr_sectors = 2;
req->buffer = bh->b_data;
req->waiting = NULL;
req->bh = bh;
req->next = NULL;
add_request(major+blk_dev,req);
}
add_request
/*
* add-request adds a request to the linked list.
* It disables interrupts so that it can muck with the
* request-lists in peace.
*/
static void add_request(struct blk_dev_struct * dev, struct request * req)
{
struct request * tmp;
req->next = NULL;
cli();
if (req->bh)
req->bh->b_dirt = 0;
if (!(tmp = dev->current_request)) {
dev->current_request = req;
sti();
(dev->request_fn)();
return;
}
for ( ; tmp->next ; tmp=tmp->next)
if ((IN_ORDER(tmp,req) ||
!IN_ORDER(tmp,tmp->next)) &&
IN_ORDER(req,tmp->next))
break;
req->next=tmp->next;
tmp->next=req;
sti();
}
硬盘的操作
void do_hd_request(void)
{
int i,r = 0;
unsigned int block,dev;
unsigned int sec,head,cyl;
unsigned int nsect;
INIT_REQUEST;
dev = MINOR(CURRENT->dev);
block = CURRENT->sector;
if (dev >= 5*NR_HD || block+2 > hd[dev].nr_sects) {
end_request(0);
goto repeat;
}
block += hd[dev].start_sect;
dev /= 5;
__asm__("divl %4":"=a" (block),"=d" (sec):"0" (block),"1" (0),
"r" (hd_info[dev].sect));
__asm__("divl %4":"=a" (cyl),"=d" (head):"0" (block),"1" (0),
"r" (hd_info[dev].head));
sec++;
nsect = CURRENT->nr_sectors;
if (reset) {
reset = 0;
recalibrate = 1;
reset_hd(CURRENT_DEV);
return;
}
if (recalibrate) {
recalibrate = 0;
hd_out(dev,hd_info[CURRENT_DEV].sect,0,0,0,
WIN_RESTORE,&recal_intr);
return;
}
if (CURRENT->cmd == WRITE) {
hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,&write_intr);
for(i=0 ; i<3000 && !(r=inb_p(HD_STATUS)&DRQ_STAT) ; i++)
/* nothing */ ;
if (!r) {
bad_rw_intr();
goto repeat;
}
port_write(HD_DATA,CURRENT->buffer,256);
} else if (CURRENT->cmd == READ) {
hd_out(dev,nsect,sec,head,cyl,WIN_READ,&read_intr);
} else
panic("unknown hd-command");
}
```
#### hd_out
```c
static void hd_out(unsigned int drive,unsigned int nsect,unsigned int sect,
unsigned int head,unsigned int cyl,unsigned int cmd,
void (*intr_addr)(void))
{
register int port asm("dx");
if (drive>1 || head>15)
panic("Trying to write bad sector");
if (!controller_ready())
panic("HD controller not ready");
do_hd = intr_addr;
outb_p(hd_info[drive].ctl,HD_CMD);
port=HD_DATA;
outb_p(hd_info[drive].wpcom>>2,++port);
outb_p(nsect,++port);
outb_p(sect,++port);
outb_p(cyl,++port);
outb_p(cyl>>8,++port);
outb_p(0xA0|(drive<<4)|head,++port);
outb(cmd,++port);
}
```
#### 中断回调函数
```c
static void write_intr(void)
{
if (win_result()) {
bad_rw_intr();
do_hd_request();
return;
}
if (--CURRENT->nr_sectors) {
CURRENT->sector++;
CURRENT->buffer += 512;
do_hd = &write_intr;
port_write(HD_DATA,CURRENT->buffer,256);
return;
}
end_request(1);
do_hd_request();
}
```
### 总结
1. 找不到buffer_head会进行阻塞。
2. 等待磁盘IO的写操作。
3. 等待buffer_head lock锁释放














 1798
1798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









