







参考:
http://www.cnblogs.com/Xnice/p/4522671.html
http://blog.csdn.net/dark_scope/article/details/17228643
http://blog.csdn.net/qq_20599123/article/details/51509335
用户-电影评分矩阵形式

矩阵分解模型(matrix factorization model)

Pu
代表用户隐因子矩阵(
表示用户
u
对因子
k
的喜好程度),Qi
表示电影隐因子矩阵(
表示电影
i
在因子
k
上的程度)
Baseline Predictors
不过有些评分与用户和产品的交互无关:有些用户偏向于给产品打高分,有些产品会收到高分。我们将这类不涉及用户产品交互的影响建模为baseline predictors。

μ是平均值,然后分别用bi和bu来代表具体用户和物品的整体偏差

SVD:
SVD就是一种加入Baseline Predictors优化的matrix factorization model。
加入防止过拟合的 λ 参数,最简单的SVD是优化下面的Loss function:
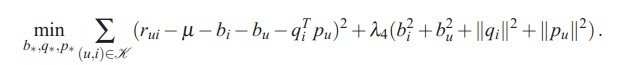
采用随机梯度下降进行优化:

虽然看起来比较简单,但实际上对预测的效果已经超出Item-based很多了,而从SVD衍生出很多其它的算法,利用了更多的信息,我们在这里只予以介绍而不加实践。
SVD++:
SVD++算法是指在SVD的基础上引入隐式反馈,使用用户的历史浏览数据、用户历史评分数据、电影的历史浏览数据、电影的历史评分数据等作为新的参数。

模型的解释:这样的模型对于提供了很多隐式反馈(
|
R
(
u
)
|
较高)的用户,使得它们的预测偏离基准预测。这对于推荐系统是一个较好的尝试,因为我们总是希望对那些提供了较多反馈用户从而可以较好建模的用户冒更大的风险。对于这类用户我们我们愿意提供不常见的推荐。而对于提供较少用户,我们更希望提供安全的预测,在基准值附近。

使用用户的历史评价数据作为隐式反馈,算法流程图如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









