






摘要:
什么是快数据,如何高效的处理快数据, Kafka + OSA可以达到极高的性能,堪称处理快数据的核武器。
内容:
什么是快数据
要了解什么是快数据,让我们先回顾什么是大数据。大数据的概念本身比较抽象,一个比较有代表性的是 4V 定义,即认为大数据需满足 4个特点:规模性(Volume)、 多样性(Variety)、高速性(Velocity) 和价值性 (Value)。
而快数据则是为了实现高速性(Velocity) 而产生的。“快”来自一些众所周知的法则:时间就是金钱,数据的价值也具有时效性,数据的价值随着时间折旧越快。
如下图所示:金融交易类的数据,其价值以毫秒计算,如股指期货的指数数据,其价值瞬间就耗散,几分钟之前的股指数据几乎没有任何价值。航班的库存(剩余座位)信息,随着机票销售的进行,剩余数量在不断变化中,可能20秒之前的剩余座位数据对现在已经不具备参考意义。天气预报、实时路况和机票价格数据,其有效时间可能会稍长一些,以小时计算。2、3个小时之前的路况拥堵信息,已经不能作为人们出行的参考依据了。还有一些数据有效性可能会更长一些,比如商品房的售价,汽车的零售价,商家报给消费者的价格,有效期会是几天的时间。
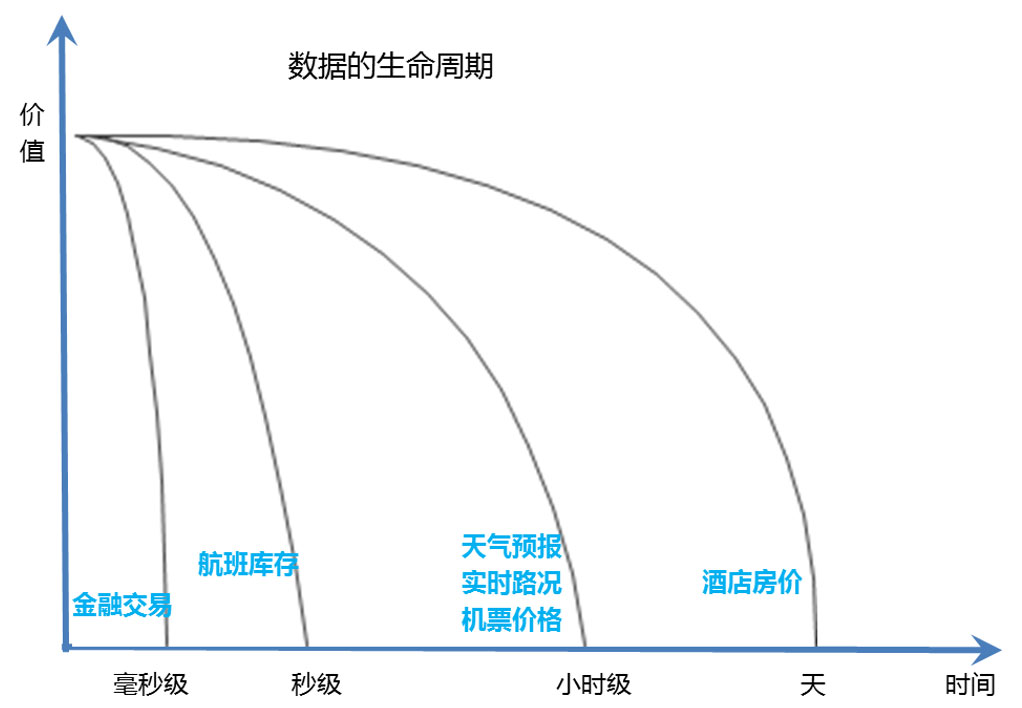
很多数据首先是快数据,其次才是大数据。那么就需要正确认识数据的生命周期,充分利用数据的实时价值,比如机票的价格数据,需要根据库存情况进行以小时为单位的动态调整。航班起飞后,这架航班上的机票销售数据就成为历史数据,实时价值丧失,这时候可以作为大数据的一部分,成为未来机票价格制定的参考依据。
快数据处理技术
下面给出了不同业务处理数据快慢的比较。从数据分析的技术实现视角分析,目前的大数据处理可以分为如下三个类型:
- 复杂的批量数据处理(batch processing),常见的实现框架如Hadoop/Mapreduce,数据处理的时间跨度在数十分钟到数小时之间。
- 增强的历史数据的交互式查询(inter-active query),常见的实现框架如Dremel/Impala,数据处理的时间跨度在数十秒到数分钟之间。
- 基于实时事件数据流的数据处理(event streaming processing),常见的实现框架如Oracle OSA、Apache Strom。数据处理的时间跨度在数百毫秒到数秒之间。
以上的三种方式,最符合快数据定义的是第三种。基于实时事件数据流的数据处理不光是能够提供更快的数据处理效率,而是采用了一种完全不同于离线批处理的模式。这两种处理模式,批处理(Batch Processing)是先存储后处理(Store-then-process),而流处理则是直接处理(Straight-through processing)。这两种处理模式相辅相成,在企业构建大数据处理框架时都非常重要。
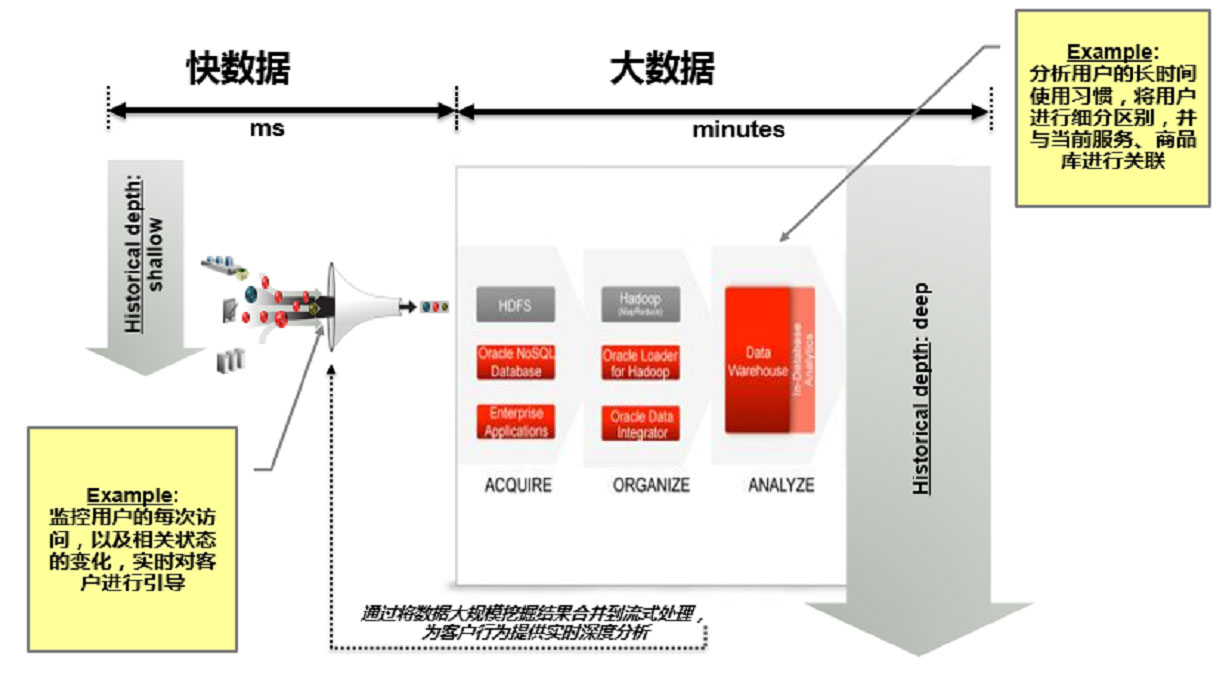
快数据指的就是流处理模式中的活动数据、即时状态数据或者正在进行处理当中的数据。快速数据的价值会随着处理时间的增加而迅速减少。这就要求处理工具要具备接近实时处理和决策的能力。而通过实时分析,企业可以通过实时交互为客户提供很好的服务、更加高效的管理系统资源以及推出新的实时业务。快数据已成为大数据之中的一项重点发展方向。
捕捉输入数据价值的最佳方式就是在信息抵达时立即作出反应及操作。为了处理每秒涌现的数万乃至数百万事件的相关数据,我们需要两类技术作为前提:首先,一套能够在事件抵达的同时立即进行交付的流系统;第二,一套能够在所有条目抵达的同时立即进行处理的数据存储方案。
Oracle OSA(Oracle Stream Analytics)能够非常可靠地处理每秒消息量高达百万级别的数据流。Kafka则是一套具备极高数据吞吐能力的分布式消息处理系统。这两大流系统方案解决了快数据处理任务的前提性难题。虽然去年发布的Kafka也提供流数据处理功能Stream API.但相比OSA还是要弱很多。所以它们更适合结合起来用,发挥各自的长处。
Kafka简介
Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一个分布式的,可分区的,冗余备份的持久性的日志服务。它主要用于处理流式数据。
Kafka提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。Kafka有4部分核心的API,分别是:
Ø ProducerAPI发布流记录(streamof records)到Kafka topics.
Ø ConsumerAPI 应用订阅Kafka topics,并处理其中的流记录(stream of records)
Ø Streams API 使应用相当于一个流处理器,从一个或者多个Kafka topics的输入流中消费流记录,进行高效转换,发布到输出流output streams中。
Ø ConnectorAPI 连接Kafka topics到其他应用或者数据系统,如连接到数据库,并捕获表中数据的变化。
与传统消息系统相比,Kafka有以下特点:
Ø 同时为发布和订阅提供高吞吐量。同传统消息系统比,Kafka具有良好的扩展性和性能优势。
Ø 可进行持久化操作,将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
Ø 分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
Ø 消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
Ø Kafka基于拉的消费模型让消费者以自己的速度处理消息。如果处理消息时出现了异常,消费者始终可以选择再消费该消息。
值的一提的是,Oracle Cloud 也支持Kafka, 在Oracle Cloud的Event Hub Cloud Service中可以直接创建Kafka实例。
Oracle Stream Analytics简介
Oracle Stream Analytics是一个快数据(流数据)处理平台。对快数据进行实时的关联,聚合和过滤。具有以下特点:
Ø 具有极高的处理性能,普通PC服务器上,每秒百万级事件处理能力。
Ø 领先的CQL- Oracle复杂事件处理器的核心,CQL与SQL-99 兼容。
Ø 同Oracle其他产品如Coherence, SOA, BAM等无缝集成,提供完整的解决方案
Ø 强大的集成能力,可集成AQ, JMS , HTTP Publish/Subscribe, SOA Suite, 数据库,Oracle Spatial,Coherence,BAM,ESB,BPM,MQTT,ApacheKafka,Twitter等。
Ø 满足企业级应用的高性能,高可用,高可扩展
Ø 可运行在Spark上面
Ø OSA更可以同OracleR结合,进行机器学习和训练,使快数据的处理进入人工智能时代。
OSA同Kafka结合
Oracle Stream Analytics支持新的事件流源和目标,例如MQTT,Apache Kafka和Twitter。特别是Kafka在现代大数据架构中变得越来越重要。我们现在可以使用Oracle Golden Gate立即捕获任何数据库表(CDC=更改数据捕获)上的更改,使用GoldenGate for BigData将这些捕获的更改事件发送到Kafka,并从OSA中使用它来对其应用流分析。
另外,OSA也可以直接调用Kafka提供的API,与Kafka集成。接收Kafka发送过来的消息,进行过滤处理,也可以发OSA处理的结果发送给Kafka.
总结:
快数据已成为大数据的一项重点发展方向,数据越快得到处理,它的价值也就越大。所以快数据有非常高的经济价值,在越来越多的领域被广泛使用。OSA能够非常可靠高效地处理数据流,在普PC服务器上每秒高达百万级别消息连的处理能力。Kafka则是一套具备极高数据吞吐能力的分布式消息处理系统。Oracle Cloud也提供Kafka服务,并且Kafka和OSA可以非常容易的进行集成。它们结合起来,可以有极高的性能,堪称处理快数据的核武器。OSA更可以同OracleR结合,进行机器学习和训练,使快数据的处理进入人工智能时代。
另外,Kafka, OSA也可以同Oracle 的IoT云结合,快速构建可靠,高效的物联网应用。














 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









