










目录
一、二分查找
前面介绍了顺序查找,但是对于有序表,有没有更好更快的查找算法呢?
在顺序查找中,如果第一个数据项比匹配查找项的话,那么最对还有n-1个待比对的数据项。那么是否可以利用有序表的特性,迅速缩小待比对数据项的范围呢?
我们从列表的中间开始比对!
- 如果列表中间的项匹配查找项,则查找结束
- 如果不匹配,那么就有两种情况:
- 列表中间的项比查找项大,那么查找项就只可能出现在前半部分;
- 列表中间的项比查找项小,那么查找项就只可能出现在列表的后半部分。
无论如何,我们都会将比对的范围缩小到原来的一半: n/2
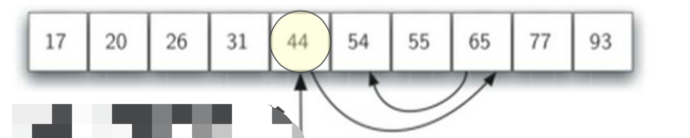
继续上面的查找,每次都会将比对范围缩小一半。
二、二分查找代码
def binarySearch(alist, item):
first = 0
last = len(alist) - 1
found = False
while first <= last and not found:
midpoint = (first + last) // 2
if alist[midpoint] == item:
found = True
else:
if alist[midpoint] > item:
last = midpoint-1
else:
first = midpoint + 1
return found三、二分查找:分而治之
二分查找实际上体现了解决问题的典型策略:分而治之
将问题分为若干更小规模的部分,通过解决每一个小规模部分问题,并将结果汇总得到原问题的解。

显然,递归算法是一种典型的分治策略算法,二分法也适合用递归算法来实现。
代码:
def binarySearch(alist, item):
if len(alist) == 0:
return False
else:
midpoint = len(alist) // 2
if alist[midpoint] == item:
return True
else:
if alist[midpoint] > item:
return binarySearch(alist[:midpoint], item)
else:
return binarySearch(alist[midpoint+1:, item])
四、算法分析
由于二分查找,每次比对数据都将下一次的比对范围缩小一半,每次比对后剩余数据项如下表所示:

当比对次数足够多以后,比对范围内就会仅剩余一个数据项,无论这个数据项是否匹配查找项,比对最终都会结束,解方程i=log2(n):

所以二分查找的的算法复杂度是O(logn)
但是在本算法中,除了比对,还有一个因素需要考虑到:
这个递归中,使用了列表的切片操作,而切片操作的复杂度是O(k),这样会使算法的复杂度稍稍增加。
当然,我们采用切片是为了使程序的可读性更好,实际上也可以不切片,而只传入起始和结束的索引值即可,这样就不会有切片的时间开销了。















 5779
5779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









