







一、系统架构设计
1. 分层式语音处理架构
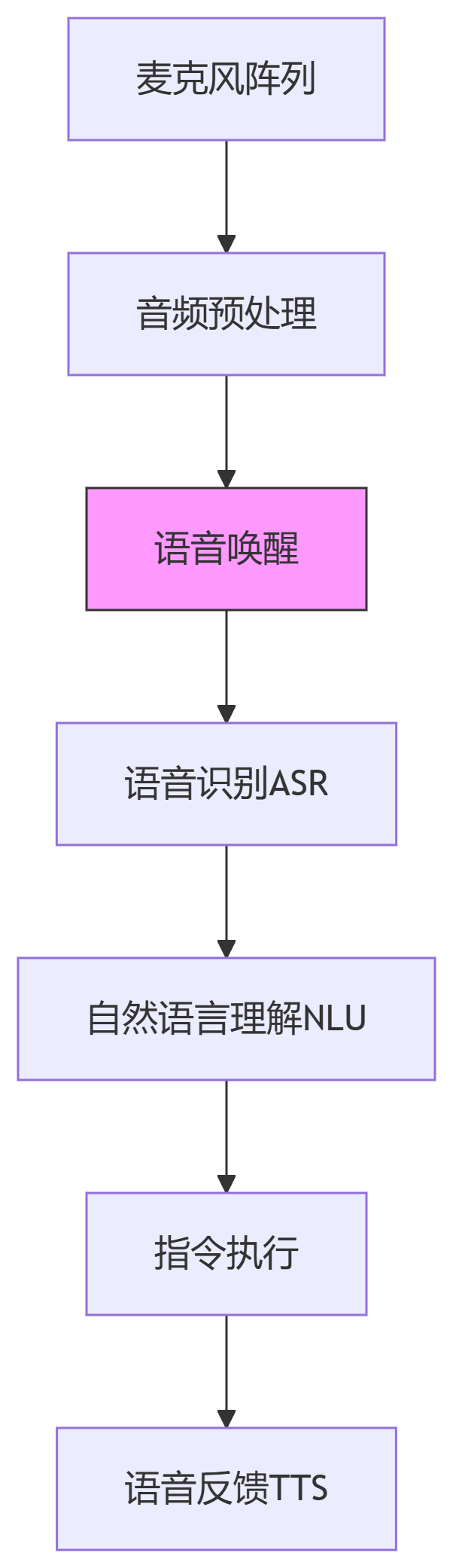
2. 硬件组成要求
| 组件 | 规格要求 | 车载特殊性 |
|---|---|---|
| 麦克风 | 4-8个数字MEMS | 抗发动机噪声 |
| DSP芯片 | 200MIPS+算力 | AEC-Q100认证 |
| 存储 | 1GB+专用缓存 | 宽温级(-40~85℃) |
三、核心技术实现
1. 车载环境语音增强
# 基于深度学习的降噪示例
class NoiseSuppression(nn.Module):
def forward(self, noisy):
stft = torch.stft(noisy, n_fft=512)
mag = self.encoder(stft) # 幅度谱编码
mask = self.mask_net(mag) # 预测理想二值掩膜
return istft(mag * mask) # 重建语音2. 本地唤醒词检测
// 低功耗始终监听实现
void KWS_Thread() {
while(1) {
if(pdm_get_samples(buf) > WAKEUP_THRESH) {
notify_main_processor(); // 唤醒主CPU
break;
}
enter_low_power_mode();
}
}3. 混合云架构设计
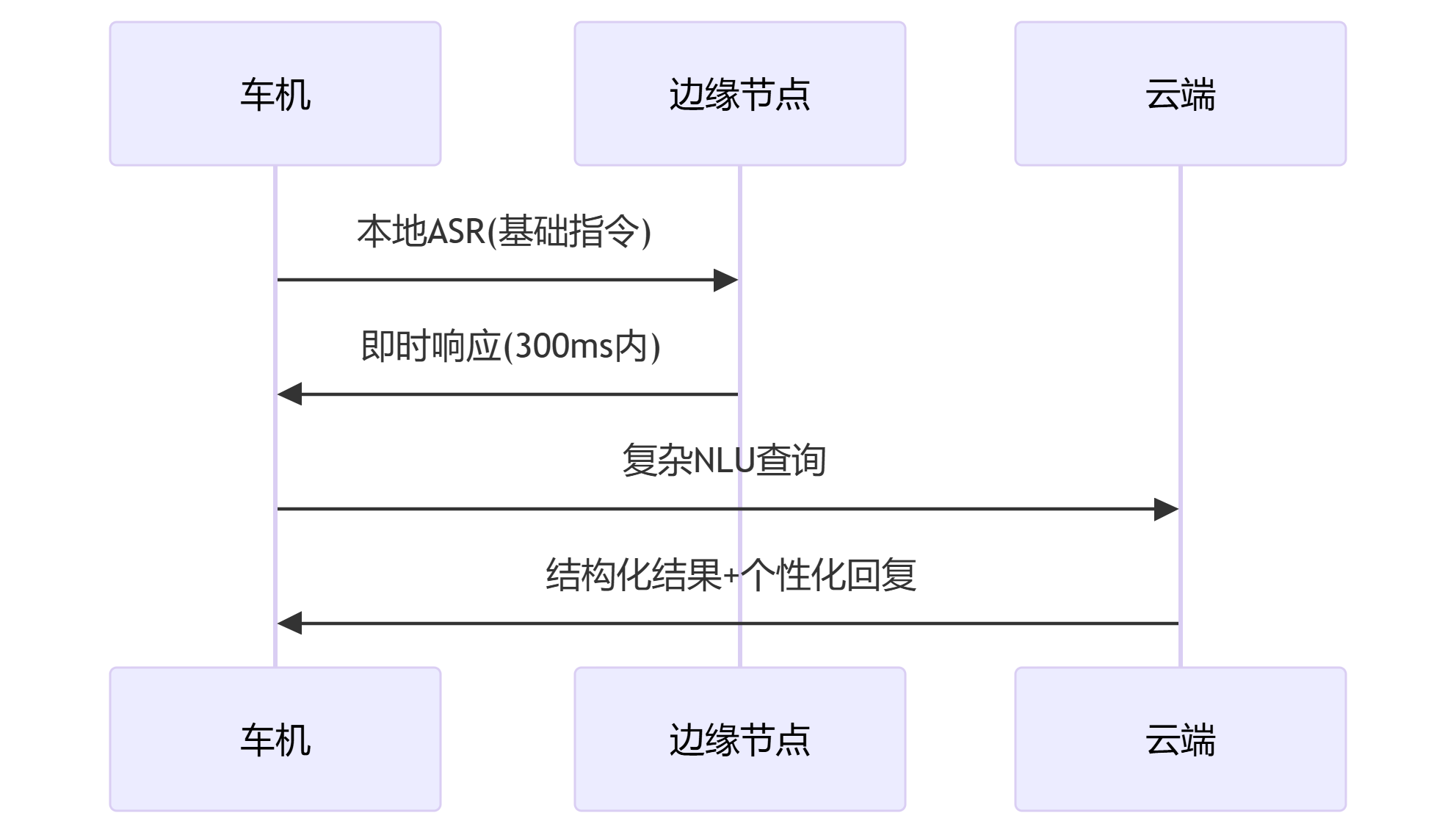
四、功能安全与合规
1. 驾驶模式限制
| 车辆状态 | 允许语音操作 | 交互限制 |
|---|---|---|
| 行驶中 | 基础控制(空调等) | 禁用长文本输入 |
| 倒车时 | 紧急指令优先 | 暂停娱乐系统 |
| 充电中 | 全功能开放 | 增加安全确认 |
2. 隐私保护方案
-
数据脱敏:自动过滤位置等PII信息
-
本地处理:敏感指令100%离线执行
-
权限管控:
<!-- Android Automotive权限 --> <uses-permission android:name="android.car.permission.CAR_VOICE_COMMAND" /> <uses-permission android:name="android.permission.RECORD_AUDIO" android:maxSdkVersion="29" />
五、性能优化策略
1. 延迟分级控制
| 操作类型 | 目标延迟 | 实现方式 |
|---|---|---|
| 唤醒响应 | <200ms | 本地DSP处理 |
| 基础指令 | <500ms | 边缘节点缓存 |
| 复杂查询 | <1500ms | 云端异步回调 |
2. 多模态融合
def execute_command(voice_cmd, gesture):
if voice_cmd.confidence < 0.7:
return gesture.get_command() # 降级到手势
elif "导航到" in voice_cmd.text:
return combine_with_hud(voice_cmd) # 结合AR显示六、问题精要
基础问题
Q:如何解决车载环境下的噪声问题?
A:三重降噪方案:
-
硬件级:麦克风阵列波束成形(Beamforming)
-
算法层:深度学习降噪模型(如RNNoise)
-
系统级:主动发送抗噪参考信号(ANC)
进阶问题
Q:设计支持方言的语音系统?
A:关键步骤:
-
数据采集:收集目标方言的1000+小时语料
-
模型微调:基于Wav2Vec2的迁移学习
-
边缘部署:量化模型至<50MB内存占用
-
动态更新:OTA方言包增量推送
系统设计
Q:实现跨ECU的语音控制空调
A:通信流程:
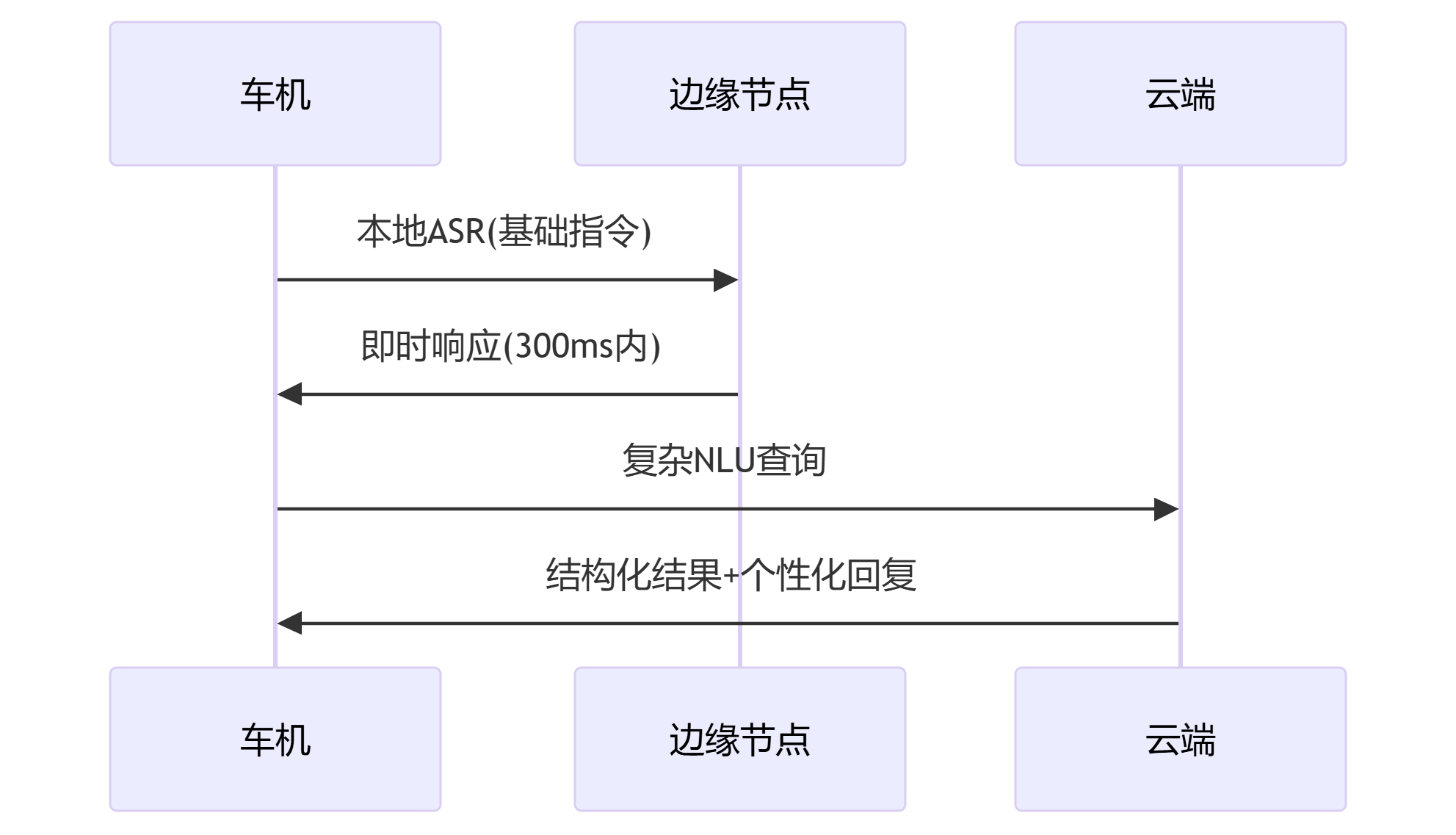
七、行业实践案例
1. 特斯拉语音方案
-
本地神经网络:基于Transformer的微型ASR
-
车辆控制API:开放300+车载指令集
-
上下文感知:结合座位传感器识别声源
2. 宝马Natural Interaction
-
5G云协同:德国本地服务器<80ms延迟
-
多模态融合:语音+手势+视线追踪
-
个性化引擎:根据用户习惯优化识别策略
八、未来演进方向
-
情感识别:
-
基于声纹的情绪检测
-
自适应应答语气调整
-
-
全车分布式:
-
每个座位独立语音区
-
声场波束定向控制
-
-
AR语音交互:
-
虚拟助手3D投影
-
语音驱动HUD导航标记
-
建议候选人准备:
-
展示对车载噪声特点的理解
-
了解AEC-Q标准对语音硬件的要求
-
熟悉主流ASR框架(Kaldi/Rasa等)
-
准备 latency budget 计算案例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









