







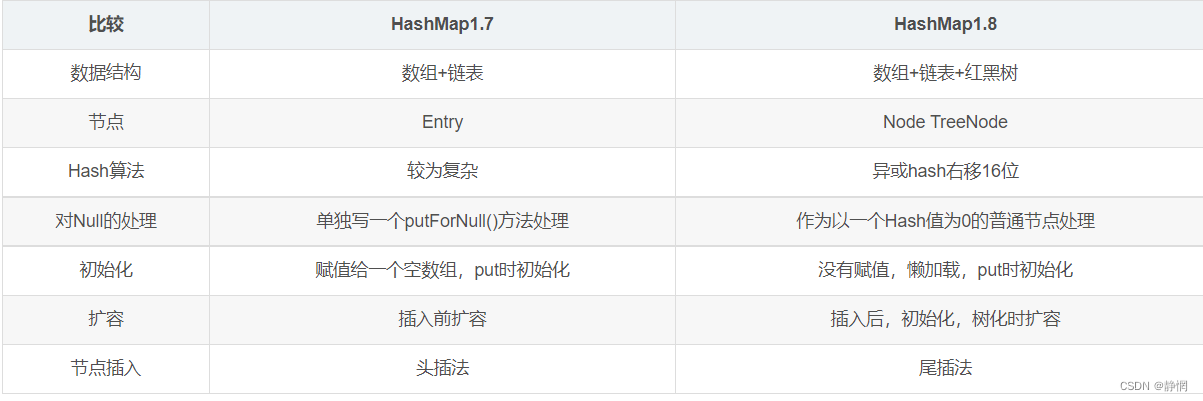
1、结构
- Jdk1.8的底层数据结构是:数组+链表+红黑树
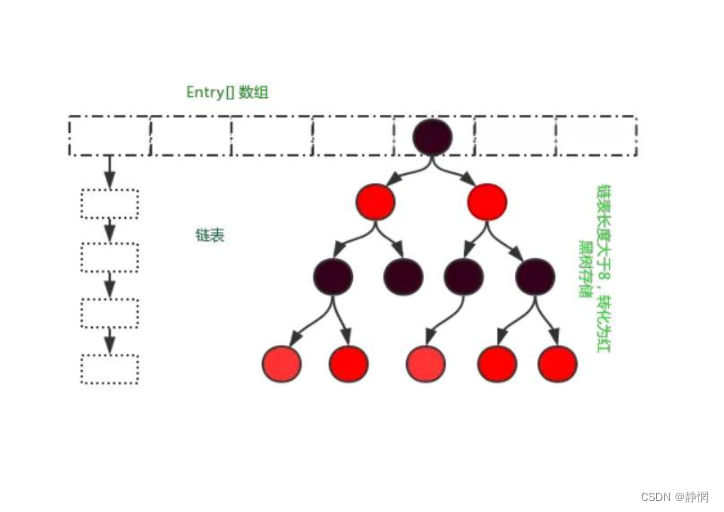
- Jdk1.7的底层数据结构是:数组+链表

区别:
一般情况下,以默认容量16为例,阈值等于(16*0.75=12)就扩容,单条链表能达到长度为8的概率是相当低的,除非 Hash 攻击或者 HashMap 容量过大出现某些链表过长导致性能急剧下降的问题,红黑树主要是为了结果这种问题。
2、节点区别
-
Jdk1.8
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; } static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; }hash是final修饰,也就是说hash值一旦确定,就不会再重新计算hash值了。- 新增了一个
TreeNode节点,为了转换为红黑树。
-
Jdk1.7
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; }hash是可变的,因为有rehash()的操作。
3、Hash算法区别
-
Jdk1.7:
final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }Jdk1.7会先判断这Object是否是String,如果是,则不采用String复写的hashcode方法,是对于一个Hash碰撞安全问题的考虑。
-
Jdk1.8:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }Jdk1.8计算出来的结果只可能是一个,所以hash值设置为final修饰。
4、对Null的处理
-
Jdk1.7:
public V put(K key, V value) { //判断是否是空值 if (key == null) return putForNullKey(value); ... }Jdk1.7中,对null值做了单独的处理,如果是null,HashMap会遍历数组的下标为0的链表,循环找key=null的键,如果找到则替换。如果当前数组下标为0的位置为空,即e==null,那么直接执行添加操作,key=null,插入位置为0。
-
Jdk1.8:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }- 而
Jdk1.8中,由于Hash算法中会将null的hash值计算为0,插入时0&任何数都是0,插入位置为数组的下标为0的位置,所以我们可以认为,1.8中null为键和其他非null是一样的,也有hash值,也能别替换。只是计算结果为0而已。
- 而
5、初始化的区别
- Jdk1.7:
Jdk1.7中,table在声明时就初始化为空表。- 和
Jdk1.8的是一致的,但是我们阅读源码发现Jdk1.8更趋向于一个方法完成一个大的功能,比如putVal,resize,代码阅读性比较差,而Jdk1.7趋向于尽可能的方法拆分,提升阅读性,但是也增加了嵌套关系,结构复杂。
- Jdk1.8:
- 获取比传入参数大的最小的2的N次幂。
区别:
- Jdk1.7:
table是直接赋值给了一个空数组,在第一次put元素时初始化和计算容量。table是单独定义的inflateTable()初始化方法创建的。
- Jdk1.8:
- 的
table没有赋值,属于懒加载,构造方式时已经计算好了新的容量位置(大于等于给定容量的最小2的次幂)。 table是resize()方法创建的。
- 的
6、扩容
- Jdk1.7:
- 头插法: 添加前先判断扩容,当前准备插入的位置不为空并且容量大于等于阈值才进行扩容,是两个条件!
- 扩容后可能会重新计算
hash值。
- Jdk1.8:
- **尾插法:**初始化时,添加节点结束之后和判断树化的时候都会去判断扩容。我们添加节点结束之后只要
size大于阈值,就一定会扩容,是一个条件。 - 由于
hash是final修饰,通过e.hash & oldCap==0来判断新插入的位置是否为原位置。
- **尾插法:**初始化时,添加节点结束之后和判断树化的时候都会去判断扩容。我们添加节点结束之后只要
7、节点的插入
-
Jdk1.7:
- 头插法: 一个一个的添加进新数组。
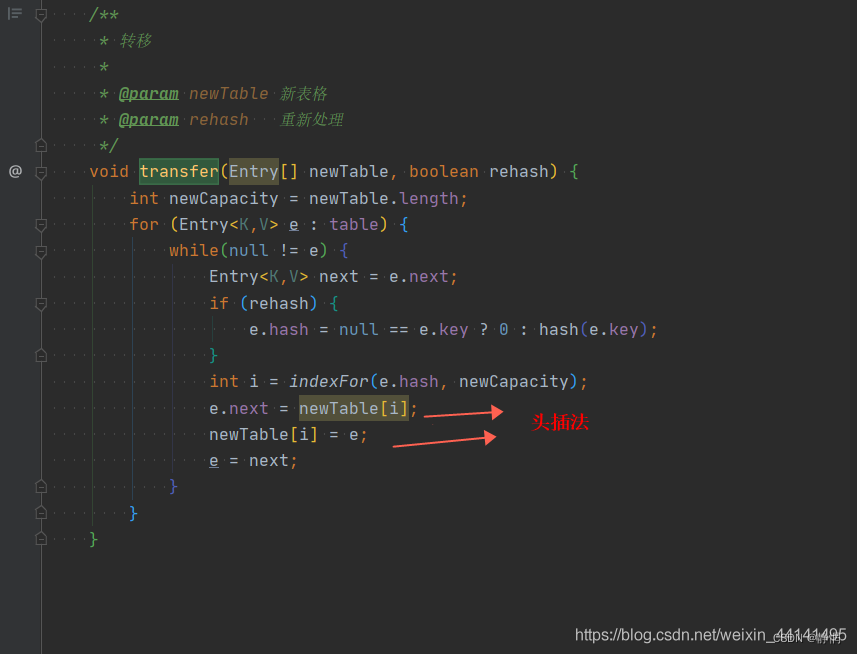
- 新增节点:标记要插入的位置已有的元素,新插入的元素覆盖已有的元素成为新的链表的头,之前标记的已有的元素作为新插入元素的
next属性传入构造器,也就是说原来的已有的链表插入到新的链表头的尾部。
-
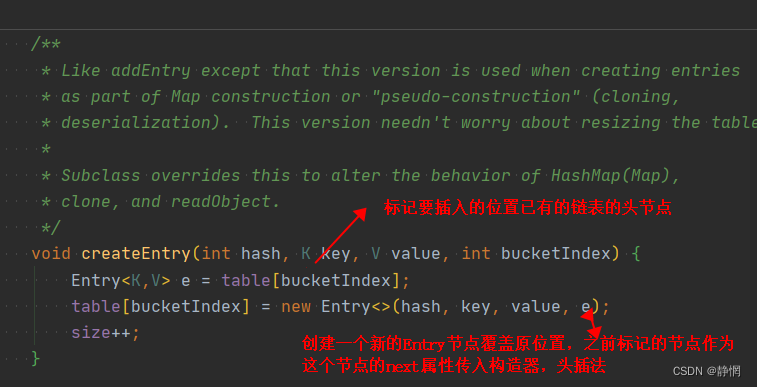
Jdk1.8:
- 尾插法:
Jdk1.8中是先得到要插入的链表,再一口气插入到新的数组,为维护两个链表时,是尾插法。

- 新增节点:尾插法

- 尾插法:















 1861
1861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









