







插入排序(insertion sort)
插入排序由N-1趟排序组成,对于P = 1到P = N-1趟,插入排序保证从位置0到位置P上的元素为已排序状态。插入排序的平均情形是θ(N^2)
假设不存在重复的元素,有以下定理:
【定理】N个互异的数的数组的平均逆序数是N(N-1)/4
【定理】通过交换相邻元素进行排序的任何算法平均需要Ω(N^2)
void insertionSort(int a[], int n)
{
int i, j, tmp;
for(i = 1; i < n; i++)
{
tmp = a[i];
for(j = i; (j > 0) && (a[j - 1] > tmp); j--)
a[j] = a[j - 1];
a[j] = tmp;
}
}
希尔排序(Shell sort)
希尔排序也叫缩小增量排序(diminishing increment sort),它使用一个序列h1,h2,...,ht,叫做增量序列(increment sequence)。在使用增量h k的一趟排序之后对于每一个i我们有A[i] <= A[i + hk],即所有相隔hk的元素都被排序,此时称文件是hk-排序的。希尔排序的一个重要性质是,一个hk-排序的文件(下一步是h k-1-排序)保持它的hk-排序性。hk-排序的一般做法是,对于h k,h k+1,...,N-1中的每一个位置i,把其上的元素放到i,i-hk,i-2hk...中间的正确位置上。一趟hk-排序的作用就是对h k个独立的子数组进行一次插入排序
【定理】使用希尔增量时,希尔排序的最坏情形运行时间为θ(N^2)
希尔增量的问题在于,这些增量未必互质,因此较小的增量可能影响很小。Hibbard提出一个稍微不同的增量序列,它在实践中(并且在理论上)能给出更好的结果。他的增量是1,3,7,...,2^k-1
【定理】Hibbard增量的希尔排序的最坏情形运行时间为θ(N^3/2)
希尔排序的性能在实践中是完全可以接受的,即使是对于数以万计的N仍是如此。编程的简单特点使得它称为对适度的大量输入数据经常选用的算法
void shellSort(int a[], int n)
{
int i, j, increment;
int tmp;
for(increment = n / 2; increment >= 1; increment /= 2)
for(i = increment; i < n; i++)
{
tmp = a[i];
for(j = i; (j >= increment) && (a[j - increment] > tmp); j -= increment)
a[j] = a[j - increment];
a[j] = tmp;
}
}
堆排序
优先队列可以用O(N log N)的时间进行排序,基于这种想法的算法叫堆排序。尽管它的O运行时间优于希尔排序,但在实践中却慢于Sedgewick增量序列的希尔排序。该算法的主要问题在于它使用了一个附加的数组,因此存储需求增加了一倍。避免使用第二个数组的聪明做法是,因为在每次DeleteMin之后堆缩小了1,所以缩小的单元可以用来存放刚刚删掉的元素
经验指出,堆排序是一个非常稳定的算法:它平均使用的比较只比最坏情形界指出的略少
void swap(int* a, int* b)
{
int t = *a;
*a = *b;
*b = t;
}
void percDown(int a[], int i, int N)
{
int child, tmp;
for(tmp = a[i]; 2*i + 1 < N; i = child)
{
child = 2*i + 1;
if((child + 1 < N) && (a[child] < a[child + 1]))
child++;
if(tmp < a[child])
a[i] = a[child];
else
break;
}
a[i] = tmp;
}
void heapSort(int a[], int N)
{
int i;
for(i = N / 2; i >= 0; i--) // 从N/2开始,只要保证向前所有的节点都大于自己的儿子节点,则堆就成功建立。注意要从N/2向前建立堆
percDown(A, i, N);
for(i = N - 1; i >= 0; i--)
{
swap(&a[0], &a[i]);
percDown(A, 0, i); // 将原来堆的最后一个元素移动到正确的位置
}
}
归并排序的基本操作是合并两个已排序的表,它的最坏情形运行时间是O(N log N)。具体算法是递归地将前半部分数据和后半部分数据各自归并排序,得到排序后的两部分数据,再将它们进行合并。虽然归并排序的运行时间是O(N log N),但它很难用于主存排序,因为合并两个各排序的表需要线性附加内存,同时对数据的频繁移动也带来了附加工作,结果严重放慢了排序速度。合并排序的例程大多数是外部排序
void Msort(int a[], int* tmpArr, int start, int end)
{
if(start < end)
{
int center = (start + end) / 2;
Msort(a, tmpArr, start, center);
Msort(a, tmpArr, center + 1, end);
Merge(a, tmpArr, start, center, end);
}
}
void Merge(int a[], int* tmpArr, int left, int leftEnd, int rightEnd)
{
int right = leftEnd + 1;
int i;
while((left <= leftEnd) && (right <= rightEnd))
{
if(a[left] < a[right])
tmpArr[i++] = a[left++];
else
tmpArr[i++] = a[right++];
}
while(left <= leftEnd)
tmpArr[i++] = a[left++];
while(right <= rightEnd)
tmpArr[i++] = a[right++];
for(i = 0; i <= rightEnd; i++)
a[i] = tmpArr[i];
}
void mergeSort(int a[], int N) // 之所以将Msort和mergeSort写成两个函数是为了避免重复为tmpArr分配空间而耗尽内存
{
int* tmpArr = (int*)malloc(N * sizeof(int));
if(tmpArr == NULL)
{
printf("Not enough space\n");
exit(1);
}
Msort(a, tmpArr, 0, N - 1);
free(tmpArr);
}
快速排序是在实践中最快的已知排序算法,它的平均运行时间是O(N log N)。尽管最坏情形的性能为O(N^2),但稍加努力就可以避免这种情形。将数组S进行快速排序基本的算法由4个步骤组成:
1. 如果S中的元素个数为0或1,返回
2. 取S中的任意元素v,称为枢纽元(pivot)
3. 将S中除pivot外所有的元素分为两个不相交的集合S1和S2, S1中的所有元素都小于pivot,S2中所有的元素都大于pivot
4. 返回quickSort(S1),pivot,quickSort(S2)
直观地看,我们希望把等于pivot的关键字平均分配到S1和S2中
选取pivot:不能选择第一个元素或前两个互异的关键词中的较大者作为pivot,因为输入可能是预排序的或是反序的。常用的安全做法是使用最左端,最右端和中心位置上的三个元素的中值作为pivot
分割策略:第一步是将pivot与最后的元素交换使得pivot离开要被分割的数据段,然后将所有小于pivot的元素向左移动,大于pivot的元素向右移动。如下图所示,i右移,j左移,当i和j停止时i指向一个大的元素而j指向一个小的元素,此时将这两个元素交换,直到i、j交错为止。如果i/j遇到的关键字和pivot相等,则i/j停止。最后,将pivot与i所指向的元素交换
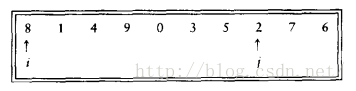
对于很小的数组(N <= 20),快速排序不如插入排序
在实际操作中,选取pivot最好的方法是对a[start],a[end]和a[center]适当地排序,将最小者放到a[start],最大者放到a[end],将pivot放到a[end - 1],这样不仅简化了比较,还可以避免j越界
#define CUTOFF 3
void swap(int* a, int* b)
{
int t = *a;
*a = *b;
*b = t;
}
int median(int a[], int start, int end)
{
int center = (start + end) / 2;
if(a[start] > a[center])
swap(&a[start], &a[center]);
if(a[start] > a[end])
swap(&a[start], &a[end]);
if(a[center] > a[end])
swap(&a[center], &a[end]);
swap(&a[center], &a[end - 1]);
return a[end - 1];
}
void insertionSort(int a[], int start, int end)
{
int i, j;
if(end - start > 0)
{
for(i = start + 1; i <= end; i++)
{
int tmp = a[i];
for(j = i; (j > start) && (a[j - 1] > tmp); j--)
a[j] = a[j - 1];
a[j] = tmp;
}
}
}
void Qsort(int a[], int start, int end)
{
if(start + CUTOFF <= end)
{
int pivot = median(a, start, end);
int i = start;
int j = end - 1;
while(1)
{
while(a[++i] < pivot); // 注意此处不能用 while(i < pivot) i++;
while(a[--j] > pivot);
if(i < j)
swap(&a[i], &a[j]);
else
break;
}
swap(&a[i], &a[end - 1]);
Qsort(a, start, i - 1);
Qsort(a, i + 1, end);
}
else
insertionSort(a, start, end);
}
void quickSort(int a[], int size)
{
Qsort(a, 0, size - 1);
}
快速排序的最坏情形是O(N^2),最好情况和平均情况都是O(N log N)
大型数据结构的中,由于交换两个结构可能是非常昂贵的操作,所以实际的做法是让数组包含指向结构的指针
对于一般的内部排序应用,选用的方法一般是插入排序,希尔排序或快速排序,主要根据输入的大小来决定。如果需要对一些大型文件排序,那么应该选用快速排序(或者希尔排序也可以)
外部排序
当外部存储设备中的数据太多无法一次全部载入内存时,需要进行外部排序
简单算法:一次读入M个记录,在内部将记录排序称为顺串(run),交替写出到两路外设再进行归并排序
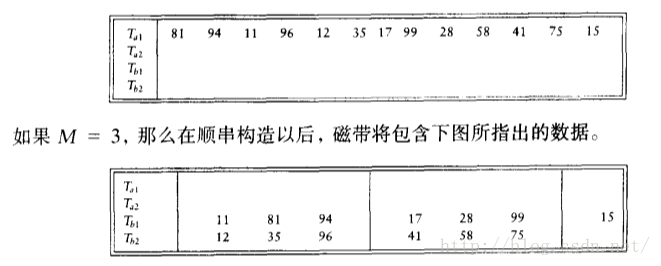
多路合并:类似简单算法,只是写出到多路。找出k个元素中的最小者稍微有些复杂,可以通过优先队列实现。但k路合并需要2k个外设
多相合并:用k+1个外设实现k-路合并。将顺串不均等地分配到外设中。如果顺串个数是斐波那契数Fn,最好的分配方法是分成F n-1和F n-2;否则需要添加哑顺串(dummy run)来进行填补
产生顺串的算法:
替换选择(replacement selection):将M个记录读入内存并放到一个优先队列中,执行一次DeleteMin将最小的记录写出,再从外设中读取一个新的记录;如果它比刚刚写出的大,则加入优先队列,否则存入优先队列但变成死区(dead space),直到优先队列大小为零,则顺串构建完成,再建立新的顺串
有可能替换选择并不比标准算法好,但由于数据常常是几乎排序的,此时替换选择仅仅产生数量很少的长顺串














 54万+
54万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









