







 本文介绍如何使用Python爬虫抓取基金数据,详细阐述了从分析网页到提取数据的步骤,包括构造动态参数、处理非HTML或JSON响应、正则表达式过滤等技巧。并提供了代码示例,适合初学者学习。
本文介绍如何使用Python爬虫抓取基金数据,详细阐述了从分析网页到提取数据的步骤,包括构造动态参数、处理非HTML或JSON响应、正则表达式过滤等技巧。并提供了代码示例,适合初学者学习。
相信有很多朋友还是喜欢买基金的,今天刚好有时间就给大家来一个基金的。虽然暴富不可能,但是对于理财方面还是有所帮助的。代码以及视频教程就放在下面了。
【刑不?】掌握这招,工资不会低,爬天天基金...

爬虫常规思路:
1.分析网页
2.对网页发送请求,获取响应
3.提取解析数据
4.保存数据
Python版本:3.6.5
import requests
import time
import csv
import re
分析网页
其实这个网站的网页数据没有太多的反爬,就是网页需要构建一个params的参数,该参数里面包含了网页翻页的数据,时间戳的数据,这些是动态的,需要怎么自己指定一下,如图所示:
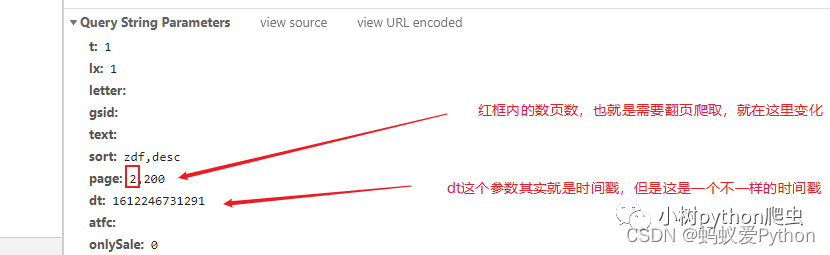
如上分析后,就可以对该链接发送请求了,但是这个网站还有一个和别的地方不一样的,他给你返回的不是html源码,也不是json数据,而是字符数据,如图:

我们可以看到这些不同html和json数据,所以就需要用到正则表达式老进行过滤提取了。经过以上分析,我的大体思路就是,先爬取一页的数据,利用正则提取,能成功爬取到一页的数据后,只用做一个循环遍历,就可以爬取多页的数据了。

代码部分:
构建请求需要的参数
###
###Python学习交流Q群:906715085####
def get_params(self):
"""
构建params参数的方法
:return:
"""
params = {
"t": "1",
"lx": "1",
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5107
5107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









