







1、概念:
HDFS : Hadoop DIstributed File Sysytem 分布式分拣储存系统
MapReduce : 并行计算框架
2、HDFS 与MapReduce 结构
HDFS: 主从结构:
主节点,只有一个: namenode
从节点可有多个:datenode
namenode负责: 接受用户请求操作请阿牛
维护文件系统的目录结构
管理文件与block之间的关系,block与datenode之间的关系
datenode 负责:
储存文件
· 把文件分成block储存在磁盘上
为保证数据的安全,文件会有多个副本
MapReduce:主从结构:
主节点:只有一个:JobTracker
从节点,可有多个:TaskTracker
JobTracker 负责:接受客户提交的计算任务
把计算任务分给TaskTracker执行
· 监控TaskTracker的执行任务
TaskTracker负责:
执行JobTracker的分配的计算任务
3、Hadoop 的特点:
3-1)、扩容能力:使用reliably储存和处理千兆字节的数据(PB)
3-2)、成本低:可以运行在普通的计算机上
3-3)、高效率:能运算分配到不同的额计算机上
3-4)、可靠性:hadoop维护数据的多副本,任务失败之后自动重新部署,计算任务。
4、 1.* hadoop 结构
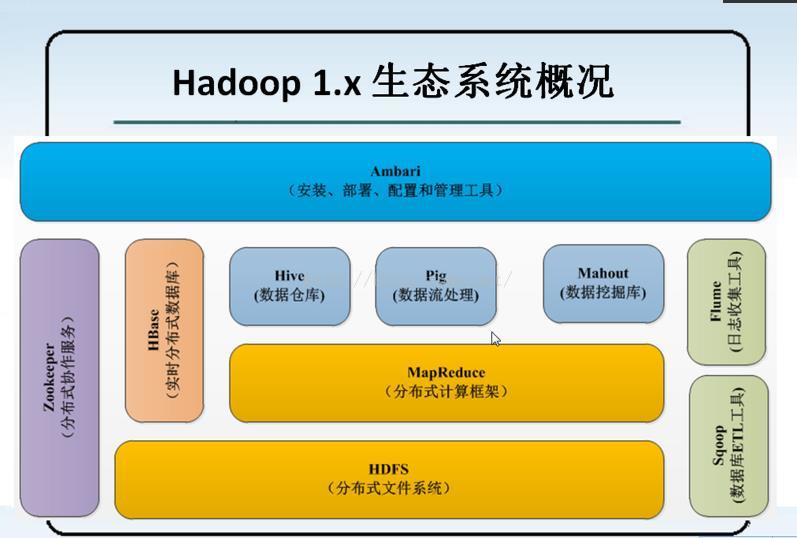
HBase : 是实时分布式从数据库:
1)、把数据库放在HDFS文件中,有多台电脑同时进行运行,效率非常高。
2)、18亿条数据,根据条件查询数据,用时1.6S 。
3)、就是一个实时的分布式的数据库,原因在于HDFS的分布式。
ETL : (E)提起 ----- > (T) 转换 ---- > (L) 加载
在数据库中提取数据,并进行一系列的对数据的清理筛选,将合格的数据进行转换一定格式的数据进行储存,将格式化的数据储存到HDFS上,以供计算框架进行计算与筛选以及挖掘。
TSV 格式:每行数据的每列之间以【制表符\t】进行分割。
CSV 格式 : 每行数据的每列之间以【逗号】进行分割。
Sqoop : 数据库ETL 工具 :
强关系型数据库的数据与HDFS(HDFS文件、Hbase中的表、Hive 中的表) 上的数据进行相互导入
Flume : 日志收集工具,主要处理日志的信息
hadoop 1* 的组成

NameNode : 数据元服务器
JobTracker : 任务调度员
DateNode : 块储存
TaskTracker : 执行任务
分布式的系统与框架的结构来说,一般分为两大块:
第一部分:管理层,用于管理应用层的
第二部分:应用层(工作的)
HDFS 分布式系统:
NameNode : 属于管理层,用于管理数据的属性,属性包含:路径,权限,文件名字,文件的块先和
SeccondaryNameNode : 也属于管理者,辅助NameNode进行管理
DateNode : 属于应用层,用户进行数据的储存,被NameNode 进行管理,要定时的向NameNode 进行工作汇报,执行NameNode分配分发的任务。
MapRecude 分布式系统 :
JobTracker : 属于管理层,管理集群资源和对任务进行资源的调度,监控人去的执行。
TaskTracker : 属于应用层,执行JobTracker 分配分发的任务,并向JobTracker汇报工作情况。
5、 2.* 的hadoop 的结构如下:

hadoop 1.* 的版本与 hadoop 2.* 的版本相比,只是多了一个Yarn框架,主要负责集群管理的任务。
Yarn : 对每台机器的资源管理,对每台机器的服务,每个人应用进行调度,以及资源的,包括CPU,内存,银盘的调度。
各个节点的理解:

NameNode 主节点 : 储存文件的元数据,例如文件的路径,权限,以及每个文件快的列表以及所在快的DateNode .
DateNode : 在本地文件系统中储存文件快的数据,以及块的校验和
Secondary NameNode : 用来监控HDFS状态的辅助后台程序,每个一段时间获取HDFS元数据的额快照。
JobTracker : 负责接受用户提交的作业,负责启动,跟踪任务执行。‘
TaskTracker : 负责执行由JobTracker 分配的任务,管理各个任务在每个节点上的执行情况。
NameNode : 储存文件的元数据:
1)、文件的额名字
2)、文件的目录结构
3)、文件的属性(权限、副本数、生成的时间)
4)、文件 -- > Block ----- > DateNode 上
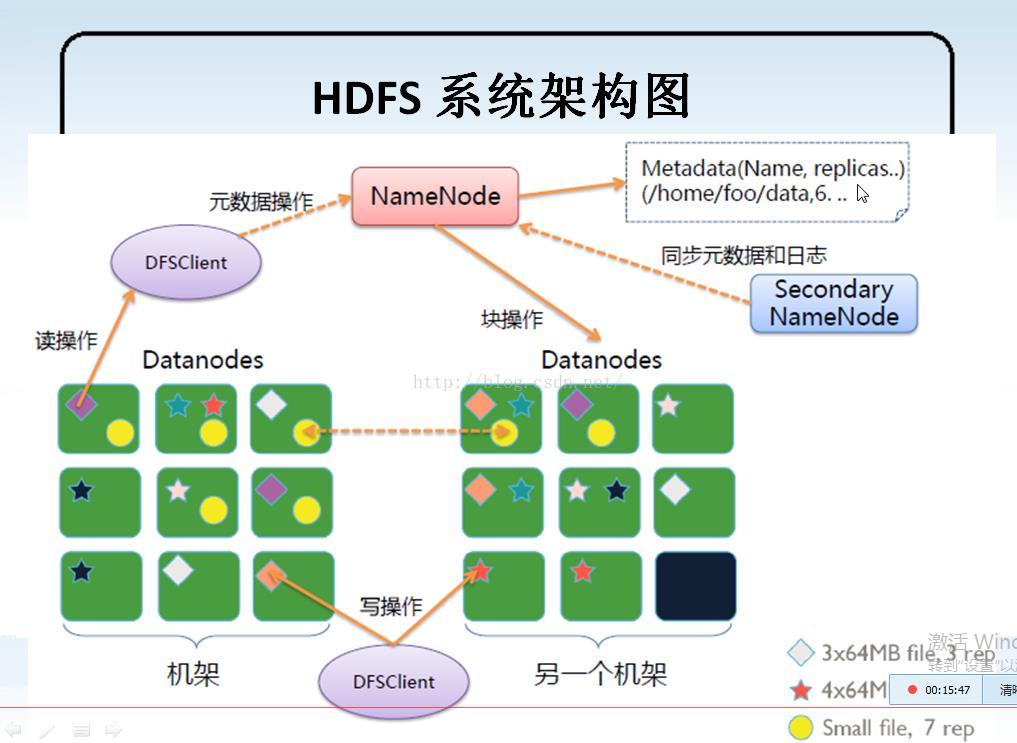
6、 HDFS 的结构图:
1)、理解一图:
2)、理解二图:
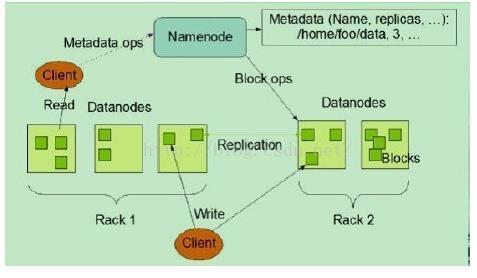
1)NameNode、DataNode和Client
NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、
集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,
这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,
同时周期性地将所有存在的Block信息发送给NameNode。
Client就是需要获取分布式文件系统文件的应用程序。
2)文件写入
Client向NameNode发起文件写入的请求。
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
3)文件读取
Client向NameNode发起文件读取的请求。
NameNode返回文件存储的DataNode的信息。
Client读取文件信息。
通信方式介绍:
在hadoop系统中,master/slaves/client的对应关系是:
master---namenode;
slaves---datanode;
client---dfsclient;
那究竟是通过什么样的方式进行通信的呢,在这里从大体介绍一下:
简单地讲:
client和namenode之间是通过rpc通信;
datanode和namenode之间是通过rpc通信;
client和datanode之间是通过简单的socket通信。
随便拔一下DFSClient的代码,可以看到它有一个成员变量public final ClientProtocolnamenode;
而再拔一下DataNode的代码,可以看到它也有一个成员变量public DatanodeProtocolnamenode
7、MapReduce 结构图 :
1)、MapReduce 系统的架构图:
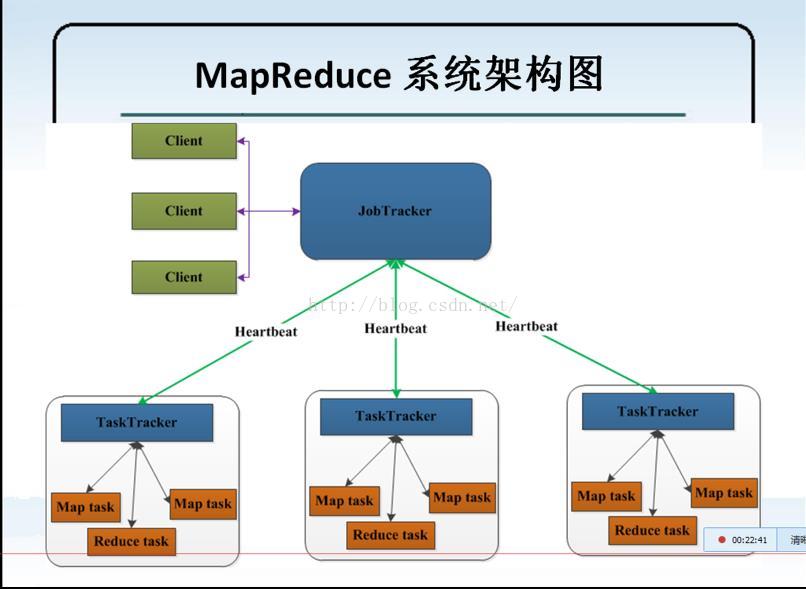
HearBeat : 心跳的意思
实现的思路:客户端请求时贤惠发送到JobTracker 中,再有JobTracker 通过心跳的方式,每个一段时间通信一次,
分配到TaskTrackker 中,同事TaskTracker 也会心跳的方式去请求JobTracker ,也会返回结果。
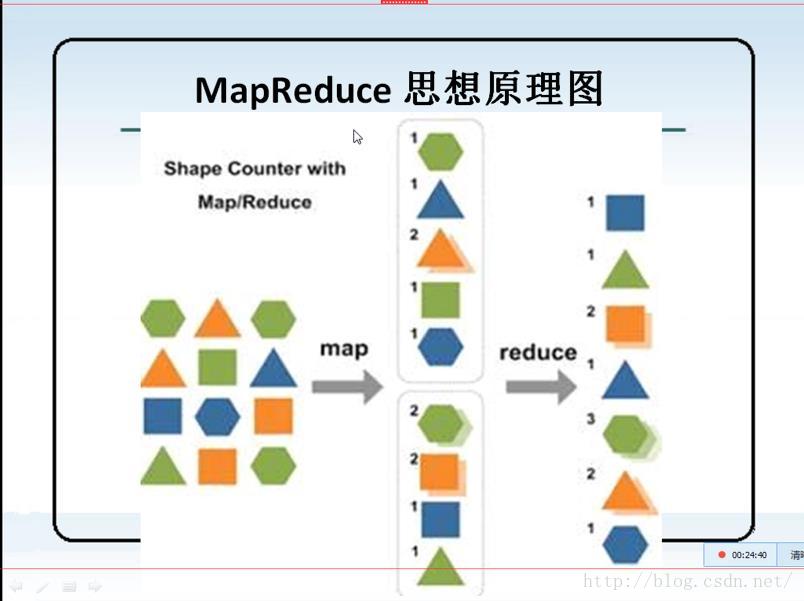
2、MapRecude 思想原理图
8、hadoop 的启动顺序与关闭顺序
1)、启动顺序
HDFS: namenode -- > datanode ---> Secondarynamenode
MapReduce : JobTracker --- > TaskTracker
2)、关闭顺序
MapReduce : JobTracker ---> TaskTracker
HDFS: namenode --> datenode -- > secondarynamenode
9、读文件的流程
首先客户端会请求文件下心痛,文件系统会去找namenode上的checksum节点,在全中查找最近的datenode获取block
的数据。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











