







文章连接
1.spark学习-hadoop安装与启动
2.spark学习-spark安装和启动
服务器信息:
172.18.101.157 spark-master
172.18.101.162 spark-slave1
172.18.132.162 spark-slave2
安装前准备
- spark下载
由于我们的hadoop的版本是2.7.6.所以在选中spark版本的时候,要注意.
要选中pre-built for apache hadoop2.7 and later的版本
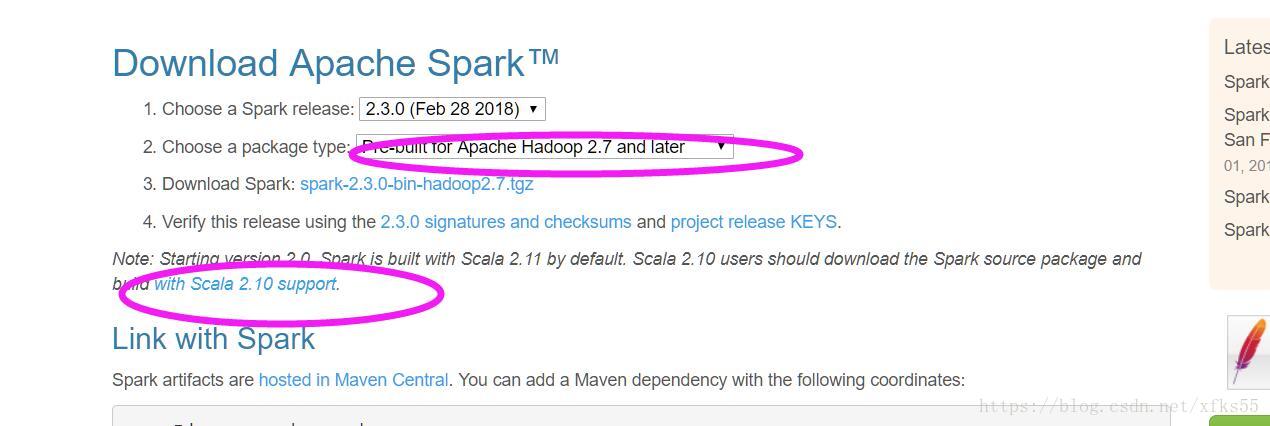
#下载spark
[root@spark-master local]# wget http://mirror.bit.edu.cn/apache/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
#解压
[root@spark-master local]# tar -xvf spark-2.3.0-bin-hadoop2.7.tgz
#重命名文件夹
[root@spark-master local]# tar -xvf spark-2.3.0-bin-hadoop2.7 spark-2.3.0
#配置环境变量
export SPARK_HOME=/usr/local/spark-2.3.0
export PATH=$PATH:$SPARK_HOME/bin
#使环境变量生效
[root@spark-master local]# source /etc/profile- scala的安装
spark需要安装Scala语言的支持,在spark的下载页面,我们看到要求最低的版本是scala2.10
我们这里安装的是scala-2.12.6
#解压
[root@spark-master opt]# tar -xvf scala-2.12.6.tgz
#配置环境变量
[root@spark-master opt]# vim /etc/profile
export SCALA_HOME=/usr/scala-2.12.6
export PATH=$PATH:$SCALA_HOME/bin
#使环境变量生效
[root@spark-master opt]# source /etc/profile
#检查是否配置成功
[root@spark-master opt]# scala -version
Scala code runner version 2.12.6 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.安装完成之后,安装同样的步骤安装到另外两台slave机器上
修改配置文件
需要修改的配置文件有两个
spark-env.sh ,spark-defaults.conf,slaves
spark-env.sh
# 复制模版配置文件
[root@spark-master spark-2.3.0]# cp conf/spark-env.sh.template conf/spark-env.sh
#修改配置文件.
[root@spark-master spark-2.3.0]# vim conf/spark-env.sh
export JAVA_HOME=/opt/jdk1.8.0_144
export SCALA_HOME=/opt/scala-2.12.6
export HADOOP_HOME=/usr/local/hadoop-2.7.6/
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.6/etc/hadoop
#定义管理端口
export SPARK_MASTER_WEBUI_PORT=8088
#定义master域名和端口
export SPARK_MASTER_HOST=spark-master
export SPARK_MASTER_PORT=7077
#定义master的地址slave节点使用
export SPARK_MASTER_IP=spark-master
#定义work节点的管理端口.work节点使用
export SPARK_WORKER_WEBUI_PORT=8088
#每个worker节点能够最大分配给exectors的内存大小
export SPARK_WORKER_MEMORY=4gslaves
#复制模版配置文件
[root@spark-master spark-2.3.0]# cp conf/slaves.template conf/slaves
#修改配置文件.
[root@spark-master spark-2.3.0]# vim conf/slaves
spark-slave1
spark-slave2spark-defaults.conf
[root@spark-master spark-2.3.0]# vim conf/spark-defaults.conf
spark.eventLog.enabled=true
spark.eventLog.compress=true
#保存在本地
#spark.eventLog.dir=file://usr/local/hadoop-2.7.6/logs/userlogs
#spark.history.fs.logDirectory=file://usr/local/hadoop-2.7.6/logs/userlogs
#保存在hdfs上
spark.eventLog.dir=hdfs://spark-master:9000/tmp/logs/root/logs
spark.history.fs.logDirectory=hdfs://spark-master:9000/tmp/logs/root/logs
spark.yarn.historyServer.address=spark-master:18080启动spark
[root@spark-master spark-2.3.0]# sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-2.3.0/logs/spark-root-org.apache.spark.deploy.master.Master-1-spark-master.out
spark-slave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-2.3.0/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-spark-slave1.out
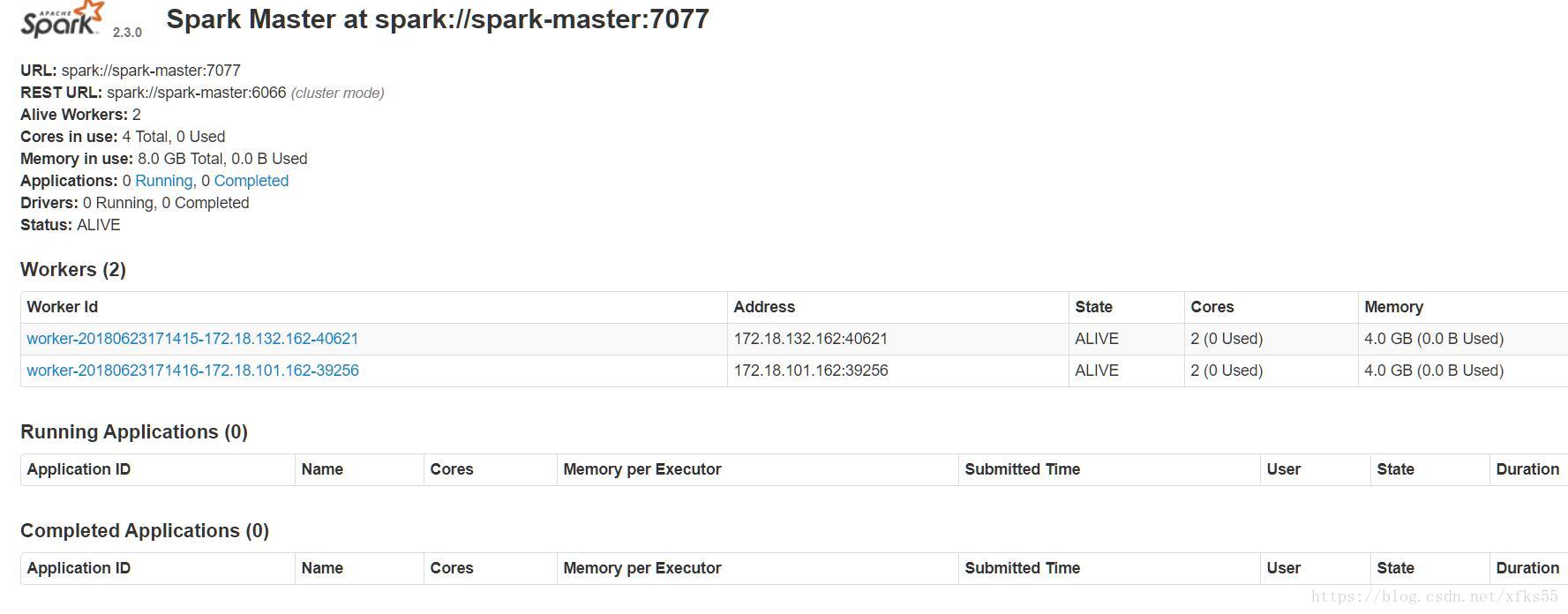
spark-slave2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-2.3.0/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-spark-slave2.out查看web管理界面
http://172.18.101.157:8088/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









