







PowerBI企业运营分析——中国式报表设计
欢迎来到Powerbi小课堂,在竞争激烈的市场环境中,企业运营分析平台成为提升竞争力的核心工具。
通过整合多源数据并实时监控关键指标,该平台能够迅速洞察业务表现,精准捕捉问题与机遇,正如吉客云通过其强大的数据分析和业务管理功能,为企业提供了一站式的解决方案。通过实时监控和数据整合的可视化看板,管理者能够直观掌握运营动态,优化资源分配。同时,深度分析模块能够挖掘潜在趋势,为战略决策提供有力支持。通过非结构化数据管理平台,企业能够实现降本增效,优化业务流程,提升运营效率。帮助企业深入理解市场趋势和用户需求,优化决策,为可持续增长提供支持。
本期课程我们依然将重点放到整合前期分散知识点,帮助您建立清晰的模板搭建思路,本节课程涵盖中国式报表制作,本节课程重点使用计算组制作中国式报表、多维度参数呈现,本期难度上升,一起接受挑战吧。
想要一份这样的可视化看板吗?想学吗?我教你呀!

一、案例背景:
我司作为国内一家大型服装电商企业,业务范围涵盖男装、女装、童装和配饰。目前,我们正全力开发企业运营分析系统,该系统旨在借助技术手段,实现业绩的稳步增长、指标的实时监控、绩效考核的精准实施、客户关系的深度维护与开发,以及企业发展的科学预测。同时,促进数据的高效共享与流程的不断优化,从而提升决策效率与运营效率,优化资源配置结构,加强风险控制能力,为企业的长远发展注入强劲动力。
二、设计思路:
通过财务、产品、客户、盈亏预测精准掌控企业发展方向,建立科学的考核机制,并通过控制变动成本,优化企业盈利。
(1)准备基础数据
(2)数据清洗
(3)建立关系视图
(4)个性美化设计
(5)数据建模(度量值)
(6)制作可视化报告
辅助表建立
公式:
topn标题 =
DATATABLE( "L1列" , STRING , "L1排序" , INTEGER ,
{
{ "TOP1 第1名", 1 } , // 排名
{ "TOP2 第2名", 2 } ,
{ "TOP3 第3名", 3 } ,
{ "TOP4 第4名", 4 } ,
{ "TOP5 第5名", 5 } ,
{ "TOP6 第6名", 6 } ,
{ "TOP7 第7名", 7 } ,
{ "TOP8 第8名", 8 } ,
{ "TOP9 第9名", 9 } ,
{ "TOP10 第10名", 10 }
}
)
公式解析:
此公式的作用给中国式报表制作列标题,
DATATABLE:Power BI/DAX中用于创建静态表的函数。
列定义:
"L1列":文本类型(STRING),存储格式化的排名标题(如"TOP1 第1名")。
"L1排序":整数类型(INTEGER),存储纯数字排名序号(1-10)。
数据行结构:每行用{ }包裹,包含两列的值:
第一值:排名标题字符串(如"TOP1 第1名"),其中:
TOP1:英文缩写(固定前缀)。
:多个空格(用于对齐显示)。
第1名:中文全称。
第二值:对应的数字序号(1到10)。
三、数据建模
公式:
TOPN列标题 = MIN( 'topn标题'[L1排序]) 公式解析:
直接引用辅助表排序列。
公式:
RANKX产品类别-矩阵 = IF ( [指标] = BLANK() , BLANK() , RANKX( ALLSELECTED('维度-产品'[子类别]) , [指标] , , DESC , Dense ))
RANKX产品名称-矩阵 = IF ( [指标] = BLANK() , BLANK() , RANKX( ALLSELECTED('维度-产品'[产品名称] ) , [指标] , , DESC , Dense ))
RANKX客户省份-矩阵 = IF ( [指标] = BLANK() , BLANK() , RANKX( ALLSELECTED('地图辅助表'[NAME1]) , [指标] , , DESC , Dense ))
公式解析:
根据[指标]是否为空值,决定返回空值或计算省份排名
如果[指标]为空值(BLANK()),则返回空值(避免对无数据项排名)。
否则执行RANKX排名计算。
ALLSELECTED的作用:
保留用户通过切片器、筛选器等交互操作选择的省份范围。
示例:若用户筛选“2023年数据”,则排名仅基于2023年各省份的[指标]值。
Dense排名的特点:
并列处理:相同[指标]值的省份获得相同排名。
名次连续性:不跳过名次(对比SKIP模式:1,1,3,4... → Dense模式:1,1,2,3...)。
与普通排名的区别:
普通RANKX(无Dense参数)可能产生名次间隔(如1,1,3)。
此公式确保名次连续,更适合商业报表展示。
公式:
KPI指标-上年-补0 = IF( MAX( '日期表'[年份] ) <> 2018 && [指标-上年] = BLANK() , 0 , [指标-上年] )
公式解析:
在特定条件下将空值(BLANK())替换为0,否则保留上年指标的原值。
"逻辑流程:
检查是否同时满足以下两个条件:
当前上下文中的最大年份不是2018年
上年指标值[指标-上年]为空值(BLANK())
如果条件成立,返回0(补零操作)
否则返回[指标-上年]的原始值
公式:
年增长率 = CALCULATE( CONCATENATEX( VALUES( '维度-产品'[子类别]) , FORMAT( [指标-年增长率] , "0.0%" ), UNICHAR(10) ) ,
FILTER( VALUES( '维度-产品'[子类别]) , [RANKX产品类别-矩阵] = [TOPN列标题] ) )
公式解析:
CALCULATE 函数
作用:在修改后的筛选上下文中计算表达式
此处用途:先通过FILTER限定产品子类别范围,再执行拼接操作
CONCATENATEX 函数
参数详解:
VALUES('维度-产品'[子类别]):获取当前上下文中的唯一子类别列表
FORMAT([指标-年增长率], "0.0%"):将增长率格式化为百分比(保留1位小数)
UNICHAR(10):用换行符(\n)作为分隔符
FILTER 函数
关键条件:
只保留排名等于指定标题值的子类别
数据流分析
A[所有子类别] --> B[[FILTER筛选]]
B--> C{排名=标题值}
C-->|是| D[保留该子类别]
D-->|否| E[排除]
E--> F[[CONCATENATEX拼接]]
F--> G[格式化增长率+换行符]
G--> H[最终文本结果]
典型输出示例
假设:
[TOPN列标题] = 1(筛选第1名的产品)
有2个子类别并列第1名:
手机(增长率:15.2%)
笔记本(增长率:15.2%)
公式:
指标-产品类别 =
CALCULATE( CONCATENATEX( VALUES( '维度-产品'[子类别]) , FORMAT( [指标] , 0 ), UNICHAR(10) ) ,
FILTER( VALUES( '维度-产品'[子类别]) , [RANKX产品类别-矩阵] = [TOPN列标题] ) )
指标-产品名称 =
CALCULATE( CONCATENATEX( VALUES( '维度-产品'[产品名称]) , FORMAT( [指标] , 0 ), UNICHAR(10) ) ,
FILTER( VALUES( '维度-产品'[产品名称]) , [RANKX产品名称-矩阵] = [TOPN列标题] ) )
指标-客户省份 =
CALCULATE( CONCATENATEX( VALUES( '地图辅助表'[NAME1]) , FORMAT( [指标] , 0 ), UNICHAR(10) ) ,
FILTER( VALUES( '地图辅助表'[NAME1]) , [RANKX客户省份-矩阵] = [TOPN列标题] ) )
公式解析:
CALCULATE 函数
作用:在修改后的筛选上下文中计算表达式
此处用途:先通过FILTER限定产品子类别范围,再执行拼接操作
CONCATENATEX 函数
作用:将多行数据按指定格式拼接为单个文本
参数详解:
VALUES('维度-产品'[子类别]):获取当前上下文中的唯一子类别列表
FORMAT([指标], "0"):将指标值格式化为整数(去掉小数)
UNICHAR(10):用换行符(\n)作为分隔符
FILTER 函数
作用:筛选出满足条件的产品子类别
关键条件:
只保留排名(RANKX产品类别-矩阵)等于指定标题值([TOPN列标题])的子类别
数据流分析
A[所有子类别] --> B[[FILTER筛选]]
B--> C{排名=标题值}
C-->|是| D[保留该子类别]
D-->|否| E[排除]
E--> F[[CONCATENATEX拼接]]
F--> G[指标值+换行符]
G--> H[最终文本结果]
典型输出示例
假设:
[TOPN列标题] = 1(筛选第1名的产品)
有3个子类别并列第1名:
手机(指标值:500)
笔记本(指标值:500)
平板(指标值:500)
输出结果:
关键细节说明
排名逻辑依赖:
[RANKX产品类别-矩阵] 需要预先定义,通常类似:
动态标题匹配:
[TOPN列标题] 可能是切片器选择的值(如1/2/3对应第1/2/3名)
换行符显示:
在Power BI表格/矩阵中需开启"自动换行"才能正确显示
在Tooltip中会自动换行
FORMAT函数:
"0" 表示整数格式,如1234.56 → 1235
可改为 "#,##0" 显示千分位分隔符
公式:
指标连接 =
VARZ = SELECTEDVALUE( '卡笛积维度表'[分析维度])
VARB = SWITCH( TRUE() ,
Z = "产品名称" , [指标-产品名称] ,
Z = "产品类别" , [指标-产品类别] ,
Z = "客户省份" , [指标-客户省份] ,
BLANK() )
RETURN
B公式解析:
(1)变量 Z 定义
作用:获取当前筛选上下文中用户选择的维度类型
关键点:
SELECTEDVALUE 返回单个值,如果列中有多个值则返回BLANK()
假设 '卡笛积维度表'[分析维度] 是切片器绑定的列,包含:
"产品名称"、"产品类别"、"客户省份" 等选项
(2)变量 B 定义(SWITCH逻辑)
SWITCH工作逻辑:
检查 Z = "产品名称" → 若成立,返回 [指标-产品名称]
若不成立,检查 Z = "产品类别" → 若成立,返回 [指标-产品类别]
以此类推,若均不匹配则返回 BLANK()
为什么用 SWITCH(TRUE(), ...)?
这是DAX中实现多条件分支的标准模式,比嵌套IF更清晰高效。
(3)最终返回结果
输出变量 B 的计算结果
公式:
上年-产品类别 =
CALCULATE( CONCATENATEX( VALUES( '维度-产品'[子类别]) ,
FORMAT( [KPI指标-上年-补0] , 0 ) , UNICHAR(10) ) ,
FILTER( VALUES( '维度-产品'[子类别]) , [RANKX产品类别-矩阵] = [TOPN列标题] ) )上年-产品名称 =
CALCULATE( CONCATENATEX( VALUES( '维度-产品'[产品名称]) ,
FORMAT( [KPI指标-上年-补0] , 0 ) , UNICHAR(10) ) ,
FILTER( VALUES( '维度-产品'[产品名称]) , [RANKX产品名称-矩阵] = [TOPN列标题] ) )上年-客户省份 =
CALCULATE( CONCATENATEX( VALUES( '地图辅助表'[NAME1]) ,
FORMAT( [KPI指标-上年-补0] , 0 ) , UNICHAR(10) ) ,
FILTER( VALUES( '地图辅助表'[NAME1]) , [RANKX客户省份-矩阵] = [TOPN列标题] ) )
公式解析:
CALCULATE 函数
作用:在修改后的筛选上下文中执行计算
此处用途:先通过FILTER限定省份范围,再执行文本拼接
CONCATENATEX 函数
参数详解:
VALUES('地图辅助表'[NAME1]):获取当前上下文中的唯一省份列表
FORMAT([KPI指标-上年-补0], "0"):将上年指标格式化为整数(去掉小数)
UNICHAR(10):用换行符(\n)分隔不同省份的值
FILTER 函数
关键条件:
只保留排名等于指定标题值的省份(如只显示排名第1的省份)
数据流分析
A[所有省份] --> B[[FILTER筛选]]
B--> C{排名=TOPN标题}
C-->|是| D[保留该省份]
D-->|否| E[排除]
E--> F[[CONCATENATEX拼接]]
F--> G[格式化上年值+换行符]
G--> H[最终文本结果]
关键组件说明
[KPI指标-上年-补0]
这是一个预先定义的度量值,特点:
对最早年份(如2018)返回BLANK()
对其他年份的空值补零
示例行为:
年份 实际上年值 KPI指标-上年-补0
2018 BLANK() BLANK()
2019 BLANK() 0
2020 100 100
[RANKX客户省份-矩阵]
典型定义示例:
按指标值为省份降序排名
使用Dense模式处理并列排名
[TOPN列标题]
通常来自:
切片器选择的值(如用户选择"TOP1")
或矩阵视觉对象的行标题值
典型输出示例
假设:
[TOPN列标题] = 1(筛选第1名)
有2个省份并列第1名:
江苏(上年补零值:120)
广东(上年补零值:120)
公式:
上年 =
VARZ = SELECTEDVALUE( '卡笛积维度表'[分析维度] )
VARB = SWITCH( TRUE() ,
Z = "产品名称" , [上年-产品名称] ,
Z = "产品类别" , [上年-产品类别] ,
Z = "客户省份" , [上年-客户省份] ,
BLANK() )
RETURN
B
公式解析:
(1)变量 Z 定义
作用:捕获用户在报表中选择的分析维度
关键特性:
使用SELECTEDVALUE确保只返回单个值(多选时返回BLANK())
假设 '卡笛积维度表'[分析维度] 是包含以下选项的列:
"产品名称"、"产品类别"、"客户省份"
(2)变量 B 定义(动态路由逻辑)
SWITCH工作机制:
检查 Z = "产品名称" → 返回 [上年-产品名称] 度量值
检查 Z = "产品类别" → 返回 [上年-产品类别] 度量值
检查 Z = "客户省份" → 返回 [上年-客户省份] 度量值
默认返回 BLANK()
(3)最终输出
返回变量B的计算结果
公式:
年增长-产品类别 =
VARB = CALCULATE( CONCATENATEX( VALUES( '维度-产品'[子类别]) , FORMAT( [KPI指标-年增长-补0] , 0 ), UNICHAR(10) ) ,
FILTER( VALUES( '维度-产品'[子类别]) , [RANKX产品类别-矩阵] = [TOPN列标题] ) )
RETURN
B年增长-产品名称 =
VAR B = CALCULATE( CONCATENATEX( VALUES( '维度-产品'[产品名称]) , FORMAT( [KPI指标-年增长-补0] , 0 ), UNICHAR(10) ) ,
FILTER( VALUES( '维度-产品'[产品名称]) , [RANKX产品名称-矩阵] = [TOPN列标题] ) )
RETURN
B年增长-客户省份 =
VAR B = CALCULATE( CONCATENATEX( VALUES( '地图辅助表'[NAME1]) , FORMAT( [KPI指标-年增长-补0] , 0 ), UNICHAR(10) ) ,
FILTER( VALUES( '地图辅助表'[NAME1]) , [RANKX客户省份-矩阵] = [TOPN列标题] ) )
RETURN
B
公式解析:
VAR B =
定义一个变量B,用于存储计算结果。
CALCULATE( CONCATENATEX(...) )
这是主要计算框架,CALCULATE用于修改筛选上下文,CONCATENATEX用于将多个值连接成一个文本字符串。
CONCATENATEX( VALUES('地图辅助表'[NAME1]), FORMAT([KPI指标-年增长-补0], 0), UNICHAR(10) )
VALUES('地图辅助表'[NAME1]):获取'地图辅助表'中[NAME1]列的唯一值(通常是省份名称)
FORMAT([KPI指标-年增长-补0], 0):将[KPI指标-年增长-补0]度量值格式化为整数(0表示无小数位)
UNICHAR(10):作为分隔符,这是换行符的Unicode编码
FILTER( VALUES('地图辅助表'[NAME1]), [RANKX客户省份-矩阵] = [TOPN列标题] )
这是CALCULATE的筛选参数,它限制只处理那些满足条件的省份:
[RANKX客户省份-矩阵]:可能是对省份的某种排名
[TOPN列标题]:可能是当前上下文中的某个参考值
只有当省份的排名等于这个参考值时,才会被包含在结果中
RETURN B
返回变量B的值作为最终结果
公式:
年增长 =
VAR Z = SELECTEDVALUE( '卡笛积维度表'[分析维度] )
VAR B = SWITCH( TRUE() ,
Z = "产品名称" , [年增长-产品名称] ,
Z = "产品类别" , [年增长-产品类别] ,
Z = "客户省份" , [年增长-客户省份] ,
BLANK() )
RETURN
B公式解析:
SELECTEDVALUE 函数
从表 '卡笛积维度表' 的列 [分析维度] 中获取当前筛选上下文中的唯一值(例如用户在报表中选择了"产品名称"作为分析维度)。
如果上下文中有多个值或为空,则返回空值(隐式处理)。
SWITCH(TRUE(), ...) 模式
这是一种动态匹配条件的常用技巧,相当于多个 IF 语句的简洁写法。
根据 Z 的值(即用户选择的维度),返回对应的预定义度量值:
"产品名称" → 调用 [年增长-产品名称]
"产品类别" → 调用 [年增长-产品类别]
"客户省份" → 调用 [年增长-客户省份](即你之前提问的度量值)
如果未匹配任何条件(例如用户未选择维度),返回 BLANK()。
返回值
最终返回变量 B 的结果,即动态匹配后的年增长率值。
公式:
结果-产品类别 =
VAR B = CALCULATE( CONCATENATEX( VALUES( '维度-产品'[子类别]) , '维度-产品'[子类别] , UNICHAR(10) ) , FILTER( VALUES( '维度-产品'[子类别]) , [RANKX产品类别-矩阵] = [TOPN列标题] ) )
RETURN
B结果-产品名称 =
VAR B = CALCULATE( CONCATENATEX( VALUES( '维度-产品'[产品名称]) , '维度-产品'[产品名称] , UNICHAR(10) ) , FILTER( VALUES( '维度-产品'[产品名称]) , [RANKX产品名称-矩阵] = [TOPN列标题] ) )
RETURN
B结果-客户省份 =
VAR B = CALCULATE( CONCATENATEX( VALUES( '地图辅助表'[NAME1]) , '地图辅助表'[NAME1] , UNICHAR(10) ) , FILTER( VALUES( '地图辅助表'[NAME1]) , [RANKX客户省份-矩阵] = [TOPN列标题] ) )
RETURN
B
公式解析:
CONCATENATEX 函数
作用:将一列中的多个值连接成单个文本字符串。
参数:
VALUES('地图辅助表'[NAME1]):获取 '地图辅助表' 中 [NAME1] 列的唯一值(通常是省份名称)。
'地图辅助表'[NAME1]:指定要连接的内容(这里直接连接省份名称本身)。
UNICHAR(10):分隔符为换行符(\n),使每个省份名称单独占一行。
FILTER 函数
作用:筛选出满足条件的省份。
条件:
[RANKX客户省份-矩阵] = [TOPN列标题]
[RANKX客户省份-矩阵]:可能是对省份的某种排名(例如按销售额排名)。
[TOPN列标题]:可能是当前上下文中的动态值(例如用户在报表中选择的排名范围,如“Top 5”)。
只有省份的排名等于 [TOPN列标题] 时,才会被包含在结果中。
CALCULATE 函数
作用:在筛选上下文修改后执行计算。
这里的作用是将 FILTER 的筛选条件应用到 CONCATENATEX 中。
返回值
最终返回变量 B,即满足条件的省份名称列表(每行一个省份)。
公式:
结果 =
VAR Z = SELECTEDVALUE( '卡笛积维度表'[分析维度] )
VAR B = SWITCH( TRUE() ,
Z = "产品名称" , [结果-产品名称] ,
Z = "产品类别" , [结果-产品类别] ,
Z = "客户省份" , [结果-客户省份] ,
BLANK() )
RETURN
B
公式解析:
SELECTEDVALUE 函数
从表 '卡笛积维度表' 的列 [分析维度] 中获取当前筛选上下文中的唯一值(例如用户在报表中选择了"产品名称"作为分析维度)。
如果上下文中有多个值或为空,则返回空值(隐式处理)。
SWITCH(TRUE(), ...) 模式
这是一种动态匹配条件的常用技巧,相当于多个 IF 语句的简洁写法。
根据 Z 的值(即用户选择的维度),返回对应的预定义度量值:
如果 Z = "产品名称" → 调用预定义的度量值 [结果-产品名称]。
如果 Z = "产品类别" → 调用 [结果-产品类别]。
如果 Z = "客户省份" → 调用 [结果-客户省份](即你之前提问的按省份连接文本的度量值)。
默认值:BLANK() 确保未匹配时返回空值,避免错误。
返回值
最终返回变量 B 的结果,即动态匹配后的年增长率值。
计算组建立
打开关系视图界面,选择计算组图形综合,计算项名称输入矩阵 TOPN
公式:
矩阵TOPN = IF([TOPN参数值] >= [TOPN列标题] , SELECTEDMEASURE() , BLANK() )
公式解析:
[TOPN参数值]
通常是一个用户输入的参数(如通过切片器选择"显示Top 5"),表示要显示的最大排名值。
例如:用户选择"Top 3"时,[TOPN参数值] = 3。
[TOPN列标题]
当前行对应的排名值(可能由另一个度量值计算,如 RANKX 生成的排名)。
例如:某省份的销售额排名为2,则 [TOPN列标题] = 2。
条件判断 [TOPN参数值] >= [TOPN列标题]
如果当前行的排名 ≤ 用户指定的Top N值,则显示数据;否则隐藏(返回空值)。
SELECTEDMEASURE()
动态引用当前上下文中正在计算的度量值(如销售额、利润等)。
例如:在矩阵中显示销售额时,实际返回 [销售额] 的值。
BLANK()
隐藏不符合Top N条件的数据(Power BI中空值默认不显示)。
到这里数据建模告一段落,下面进入可视化制作
四、可视化报告制作
1、业绩概览制作
第一步:设置报表页格式选项,选择画布背景,上传我们设计好的素材
第二步:插入一个图像,AI机器人图标,点开操作功能,给此图像添加登录页书签。
第三步:插入一个卡片图,将度量值日历拖入切片器。
第四步:插入七个书签按钮,输入数据中心、产品维度、客户开发、业绩分析、地域分析、业绩考核、表格维度,并给书签按钮添加我们设计好的图标。
第五步:插入一个形状,用于给以上建立视觉对象添加背景。
第六步:插入四个切片器,将年份维度表年份拖入字段中,将卡笛积维度表分析维度拖入字段中,将分析维度-指标表Z分析维度-指标拖入字段中,将以上切片器设置为垂直列表模式,将TOPN-参数表TOPN-参数拖入字段中,将此切片器设置为下拉模式。
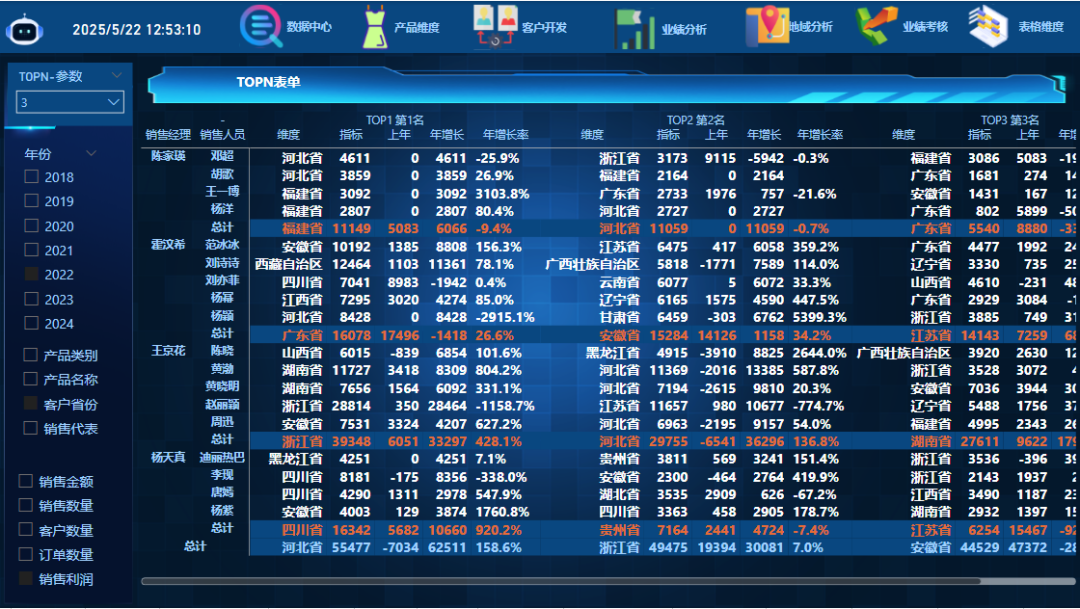
第七步:插入一个矩阵图,行拖入维度-销售人员表销售经理、销售人员字段,列拖入topn标题表L1列字段,值拖入度量值结果(重命名为维度)、指标连接(重命名为指标)、上年、年增长、年增长率,设置视觉对象格式,关闭列小计,将行小计颜色设置为橙色。
第八步:如图美化界面
第九步:打开视图窗口书签功能,为此页面添加一个书签
第十步:数据中心页,点击文本为TOPN的按钮,打开操作功能,类型选择书签,将此页书签添加到按钮。
好的,今天的讲解就到这里。后期课程也会逐渐增加难度,如果在学习过程中需要帮助,欢迎随时联系作者,精彩内容,敬请期待。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











