







Flink基础介绍-1 概述
一、Flink介绍
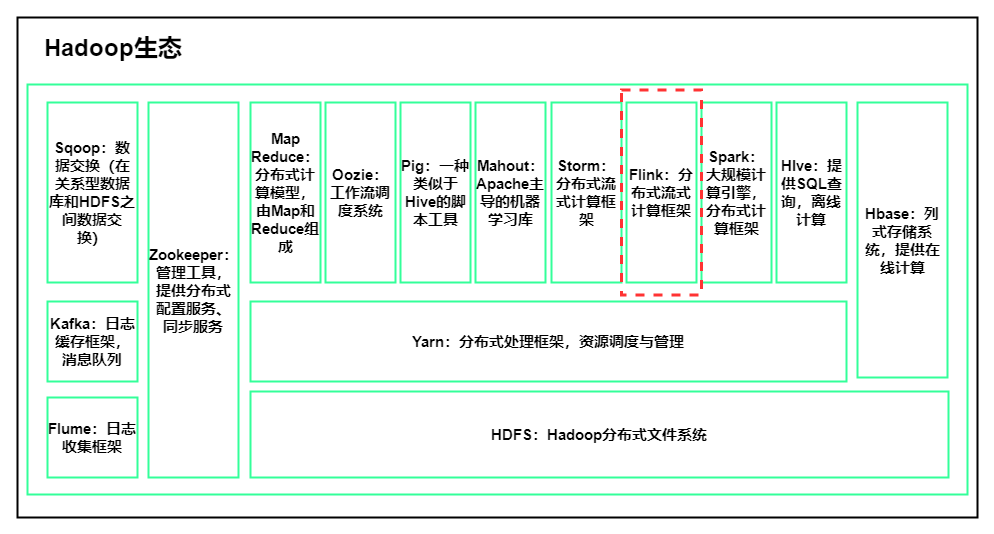
Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架。Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
1.1 批处理计算引擎
(1)第一代
首先第一代的计算引擎,就是 Hadoop 承载的 MapReduce。它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
(2)第二代
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
(3)第三代
接下来就是以 Spark 为代表的第三代计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
(4)第四代
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
1.2 流式计算引擎
第一代实时计算引擎Storm(10年提出,11年问世)对Exactly Once 语义和窗口支持较弱,使用的场景有限且无法支持高吞吐计算;第二代Spark Streaming(13年发布) 采用“微批处理”模拟流计算,在窗口设置很小的场景中有性能瓶颈,Spark本身也在尝试连续执行模式(Continuous Processing),但进展缓慢。
Flink(11年发布,19年普及)是一个低延迟、高吞吐的实时计算引擎,其利用分布式一致性快照实现检查点容错机制,并实现了更好的状态管理,Flink可在毫秒级的延迟下处理上亿次/秒的消息或者事件,同时提供了一个Exactly-once的一致性语义,保证了数据的正确性,使得Flink可以提供金融级的数据处理能力。
1.3 批处理和流处理
批处理的特点是有界、持久、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由 SparkSQL 实现,流处理由 Spark Streaming 实现,这也是大部分框架采用的策略,使用独立的处理器实现批处理和流处理,而 Flink 可以同时实现批处理和流处理。Flink 将批处理(即处理有限的静态数据)视作一种特殊的流处理。
Flink 的核心计算架构是下图中的 Flink Runtime 执行引擎,它是一个分布式系统,能够接受数据流程序并在一台或多台机器上以容错方式执行。
Flink Runtime 执行引擎可以作为 YARN(Yet Another Resource Negotiator)的应用程序在集群上运行,也可以在 Mesos 集群上运行,还可以在单机上运行(这对于调试 Flink 应用程序来说非常有用)。















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









