










贝塔分布简介及其应用
一、定义
贝塔分布(Beta Distribution)是一个连续的概率分布,它只有两个参数。它最重要的应用是为某项实验的成功概率建模。
Beta分布是一个定义在 [ 0 , 1 ] [0,1] [0,1]区间上的连续概率分布族,它有两个正值参数,称为形状参数,一般用 α \alpha α和 β \beta β表示。在贝叶斯推断中,Beta分布是Bernoulli、二项分布、负二项分布和几何分布的共轭先验分布。Beta分布的概率密度函数形式如下:
f ( x ; α , β ) = c ⋅ x α − 1 ( 1 − x ) β − 1 = x α − 1 ( 1 − x ) β − 1 ∫ 0 1 u α − 1 ( 1 − u ) β − 1 d u = Γ ( α + β ) Γ ( α ) Γ ( β ) x α − 1 ( 1 − x ) β − 1 = 1 B ( α , β ) x α − 1 ( 1 − x ) β − 1 \begin{aligned} f(x;\alpha,\beta)& =\mathrm{c}\cdot x^{\alpha-1}(1-x)^{\beta-1} \\ &=\frac{x^{\alpha-1}(1-x)^{\beta-1}}{\int_0^1u^{\alpha-1}(1-u)^{\beta-1}du} \\ &=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}x^{\alpha-1}(1-x)^{\beta-1} \\ &=\frac1{\mathrm{B}(\alpha,\beta)}x^{\alpha-1}(1-x)^{\beta-1} \end{aligned} f(x;α,β)=c⋅xα−1(1−x)β−1=∫01uα−1(1−u)β−1duxα−1(1−x)β−1=Γ(α)Γ(β)Γ(α+β)xα−1(1−x)β−1=B(α,β)1xα−1(1−x)β−1
这里的 Γ \Gamma Γ表示gamma函数。
Beta分布的均值是: α α + β \frac\alpha{\alpha+\beta} α+βα
方差是: α β ( α + β ) 2 ( α + β + 1 ) \frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)} (α+β)2(α+β+1)αβ
Beta分布的图形:
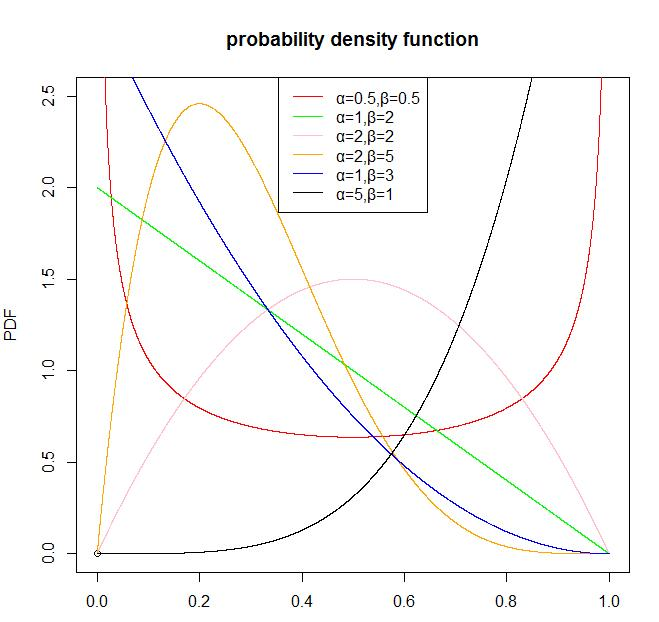
(1)beta分布的概率密度函数:
(2)beta分布的累计概率密度函数:
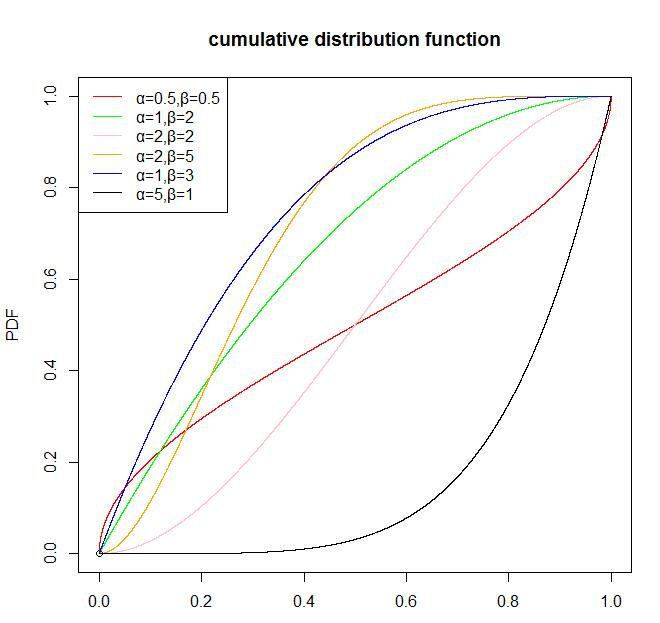
从Beta分布的概率密度函数的图形我们可以看出,Beta分布有很多种形状,但都是在 [ 0 , 1 ] [0, 1] [0,1]区间内,因此Beta分布可以描述各种 [ 0 , 1 ] [0, 1] [0,1]区间内的形状(事件)。因此,它特别适合为某件事发生或者成功的概率建模。同时,当 α = 1 \alpha=1 α=1, β = 1 \beta=1 β=1的时候,它就是一个均匀分布。
二、举例
假设一个概率实验只有两种结果,一个是成功,概率是 X X X,另一个是失败,概率为 1 − X 1-X 1−X。其中, X X X的值我们是不知道的,但是它所有可能的情况也是等概率的。如果我们对 X X X的不确定性用一种方式描述,那么,可以认为 X X X是一个来自于 [ 0 , 1 ] [0, 1] [0,1]区间的均匀分布的样本。这是很合理的,因为 X X X只可能是 [ 0 , 1 ] [0, 1] [0,1]之间的某个值。同时,我们对 X X X也一无所知,认为它是 [ 0 , 1 ] [0, 1] [0,1]之间任何一个可能的值。这些都与 [ 0 , 1 ] [0, 1] [0,1]均匀分布的性质契合。现在,假设我们做了 n n n次独立重复的实验,我们观察到 k k k次成功, n − k n-k n−k次失败。这时候我们就可以使用这些实验结果来修订之前的假设了。换句话说,我们就要计算 X X X的条件概率,其条件是我们观察到的成功次数和失败次数。这里计算的结果就是Beta分布了。在这里,在总共 n n n次实验, k k k次成功的条件下, X X X的条件概率是一个Beta分布,其参数是 k + 1 k+1 k+1和 n − k + 1 n-k+1 n−k+1。
1、为棒球运动员的击球率建模
在棒球运动中,有个叫平均击球率的概念。就是用一个运动员击中棒球的次数除以他总的击球数量。一般情况下,棒球运动员的击球概率在 0.266 0.266 0.266左右。高于这个值就是不错的运动员了。
假设我们要预测一个运动员在某个赛季的击球率,我们可以使用已有的数据计算。但是在赛季刚开始的时候,他击球次数少,因此无法准确预测。比如他只打了一次球,那击球率就是1或者0,这个显然是不对的,我们也不会这么预测。因为我们都有一个先验期望。即根据历史情况,我们认为一个运动员大概的击球率应当是在 0.215 0.215 0.215到 0.360 0.360 0.360之间。因此,当一个运动员在赛季开始就被三振出局,那么我们可以预期这个运动员的击球率可能会略低于平均值,但他不可能是0。
那么,在这个运动员的例子中,关于在赛季开始的击球情况,可以使用二项式分布表示,也就是一系列击球成功和失败的实验(假设之间相互独立)。同时,我们也会给这个数据一个先验期望(即统计中的先验知识),这个先验的分布一般就是Beta分布。这里的Beta分布就是用来修正我们观测到的运动员的击球率的(简单来说就是即便开始这个运动员被三振出局了,我们也只会预测他的击球率可能低于平均水平,但不会是0)。
假设该用户的击球率的分布是一个参数为 θ \theta θ的分布(这里 θ \theta θ既表示一个分布,也是这个分布的参数。因为在概率图模型中,我们经常使用某个分布的参数来代替说明某个模型),也就是说 θ \theta θ是用户击球成功的概率。假设,到目前为止,用户在这个赛季总共打了 n n n次球,击中的次数是 x x x,这是一个二项式分布,即 p ( y ∣ θ ) = Binomial ( x ; n , θ ) p(y \mid \theta)=\operatorname{Binomial}(x ; n, \theta) p(y∣θ)=Binomial(x;n,θ)。我们的目标就是推导 θ \theta θ分布的形式并估算这个参数的值。这就变成了在贝叶斯推断中的求后验概率的问题了:
p ( θ ∣ y , α , β ) = p ( y ∣ θ ) p ( θ ∣ α , β ) p ( y ) p(\theta \mid y, \alpha, \beta)=\frac{p(y \mid \theta) p(\theta \mid \alpha, \beta)}{p(y)} p(θ∣y,α,β)=p(y)p(y∣θ)p(θ∣α,β)
在这里,分母 p ( y ) p(y) p(y)是数据结果,也就是常数。分子第一个项是二项式分布,即 p ( y ∣ θ ) = θ x ( 1 − θ ) ( n − x ) p(y \mid \theta)=\theta^x(1-\theta)^{(n-x)} p(y∣θ)=θx(1−θ)(n−x),分子的第二项是Beta分布的结果了。详细结果后面再说。在这里,最后我们会发现 θ \theta θ也是一个Beta分布。其结果为
Beta ( α + x , β + ( n − x ) ) \operatorname{Beta}(\alpha+x, \beta+(n-x)) Beta(α+x,β+(n−x))
比如,假设所有的运动员击球率在0.27左右,范围一般是0.21到0.35之间。这个可以用参数 α = 81 \alpha=81 α=81和 β = 219 \beta=219 β=219的Beta分布表示,即 B e t a ( 81 , 219 ) Beta(81, 219) Beta(81,219)。为什么参数取这两个值呢?因为这两个参数的Beta分布的均值是0.27,主要的区间是 [ 0.2 , 0.35 ] [0.2, 0.35] [0.2,0.35]。假设某个用户击球300次,成功100次,那么,根据计算的结果,用户的击球率的分布应当是 B e t a ( 181 , 419 ) Beta(181, 419) Beta(181,419),其概率大约是均值0.303,要比平均水平略高。
2、为顺序统计量建模
假设有个机器可以随机产生 [ 0 , 1 ] [0,1] [0,1]之间的随机数,机器运行10次,第7大的数是什么,偏离不超过0.01?
这个问题的数学化表达如下:
(1)
X
1
,
X
2
,
.
.
.
,
X
n
∼
Uniform
(
0
,
1
)
,
i.i.d.
X_1, X_2, ..., X_n \sim \text{Uniform}(0,1), \text{i.i.d.}
X1,X2,...,Xn∼Uniform(0,1),i.i.d.
(2)将这
n
n
n个随机变量排序得到顺序统计量
X
(
1
)
,
X
(
2
)
,
.
.
.
,
X
(
n
)
X_{(1)}, X_{(2)}, ..., X_{(n)}
X(1),X(2),...,X(n)
(3)
X
(
k
)
X_{(k)}
X(k)的分布是什么?
我们可以假设计算 X k X_k Xk落在区间 [ x , x + Δ x ] [x, x+\Delta x] [x,x+Δx]上的概率:
P ( x ≤ X k ≤ ( x + Δ x ) ) = ? P(x \leq X_k \leq (x + \Delta x)) = ? P(x≤Xk≤(x+Δx))=?
我们将区间分成三个部分 [ 0 , x ) , [ x , x + Δ x ] , [ x + Δ x , 1 ] [0, x), [x, x+\Delta x], [x+\Delta x, 1] [0,x),[x,x+Δx],[x+Δx,1]。假设只有1个数落在区间 [ x , x + Δ x ] [x, x+\Delta x] [x,x+Δx]内,那么该事件可以表示:
E = { X 1 ∈ [ x , x + Δ x ] , X i ∈ [ 0 , x ) , X j ∈ ( x + Δ x , 1 ] } E=\left\{X_1 \in[x, x+\Delta x], X_i \in[0, x), X_j \in(x+\Delta x, 1]\right\} E={X1∈[x,x+Δx],Xi∈[0,x),Xj∈(x+Δx,1]}
其中, i = 2 , . . . , k i=2, ..., k i=2,...,k, j = k + 1 , . . . , n j=k+1, ..., n j=k+1,...,n
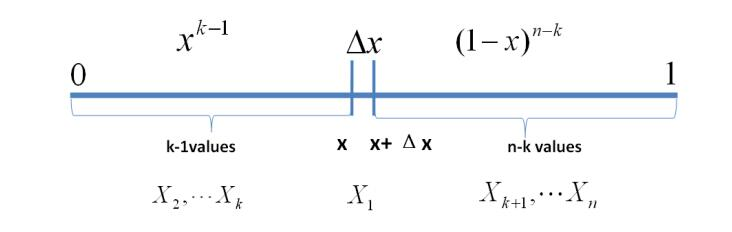
从而有:
P ( E ) = ∏ i = 1 n P ( x i ) = x k − 1 ( 1 − x − Δ x ) n − k Δ x = x k − 1 ( 1 − x ) n − k Δ x + o ( Δ x ) \begin{aligned} P(E) &= \prod_{i=1}^n P(x_i) \\ &= x^{k-1} (1 - x - \Delta x)^{n-k} \Delta x\\ & = x^{k-1} (1 - x)^{n-k} \Delta x + o(\Delta x) \end{aligned} P(E)=i=1∏nP(xi)=xk−1(1−x−Δx)n−kΔx=xk−1(1−x)n−kΔx+o(Δx)
其中 o ( Δ x ) o(\Delta x) o(Δx)表示 Δ x \Delta x Δx的高阶无穷小。根据推断,落在 [ x , x + Δ x ] [x, x+\Delta x] [x,x+Δx]区间的事件超过一个,则对应的事件概率就是 o ( Δ x ) o(\Delta x) o(Δx)。进而我们可以得到 X k X_k Xk的概率密度为:
f ( x ) = lim Δ x → 0 P ( x ≤ X k ≤ x + Δ x ) Δ x = n ! ( k − 1 ) ! ( n − k ) ! x k − 1 ( 1 − x ) n − k = Γ ( n + 1 ) Γ ( k ) Γ ( n − k + 1 ) x k − 1 ( 1 − x ) n − k = Γ ( α + β ) Γ ( α ) Γ ( β ) x α − 1 ( 1 − x ) β − 1 \begin{aligned} f(x)&=\lim _{\Delta x \rightarrow 0} \frac{P\left(x \leq X_k \leq x+\Delta x\right)}{\Delta x} \\ & =\frac{n!}{(k-1)!(n-k)!} x^{k-1}(1-x)^{n-k} \\ & =\frac{\Gamma(n+1)}{\Gamma(k) \Gamma(n-k+1)} x^{k-1}(1-x)^{n-k} \\ & =\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha) \Gamma(\beta)} x^{\alpha-1}(1-x)^{\beta-1} \end{aligned} f(x)=Δx→0limΔxP(x≤Xk≤x+Δx)=(k−1)!(n−k)!n!xk−1(1−x)n−k=Γ(k)Γ(n−k+1)Γ(n+1)xk−1(1−x)n−k=Γ(α)Γ(β)Γ(α+β)xα−1(1−x)β−1
上式即为一般意义上的beta分布。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









