






点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群介绍了 Cursor,一个结合了 AI 技术的代码编辑器,它通过深度学习和语义索引的方式,提升了开发者的工作效率。Cursor 通过与 VS Code 相似的界面和功能,以及自己的 AI 特性,实现了代码的智能化编辑和错误检查。
译文从这开始~~
你可能已经看到新闻:OpenAI 正以高达 30 亿美元的价格收购 Windsurf!与此同时,Cursor 的母公司 Anysphere 也正在以 90 亿美元估值融资 9 亿美元!这对于代码生成类应用来说,可是一笔巨资。
但如果你知道 Cursor 当前的年收入已达到 3 亿美元,而且它据说是增长最快的 SaaS(软件即服务)产品之一,这样的估值看起来就很合理了。
不过我一直在想一个问题:Cursor 或 Windsurf 究竟特别在哪里?它们的内部到底是怎么运作的?它们不就是一个换皮的 VS Code 吗?
什么是 Cursor,它能做什么?
Cursor 是一款以 AI 为核心的代码编辑器,旨在提升开发者的编码效率,能够辅助编写和修改代码。它其实是 Visual Studio Code(VS Code)的一个 “分支”,在其基础上加入了强大的 AI 功能。Cursor 就像是集成在 IDE(集成开发环境)中的智能编程助手,能实时理解你的项目并提供帮助。
那它是怎么做到的呢?主要靠的是对整个代码库进行深度索引,同时学习用户的编程风格。通过将完整的代码库转化为 “向量嵌入”(vector embeddings),它可以更轻松地发现错误、提出改进建议,甚至自动进行重构。
我猜你可能已经用过 Cursor,但下面我们快速回顾一下它的主要功能:
AI 聊天助手(具上下文感知能力)
Cursor 提供了一个聊天侧边栏,你可以像聊天一样与 AI 讨论你的代码。不同于普通的聊天机器人,它能感知你当前打开的文件、光标位置以及整个项目的上下文。你可以问它比如 “这个函数有 bug 吗?” 这样的问题,它会基于真实代码给出回答。
语义代码搜索
Cursor 像是一个聪明的代码搜索引擎。它不仅仅是简单的关键词匹配,而是使用语义搜索来理解你问题的含义,从而找到相关代码。比如你问:“日志配置在哪儿?”Cursor 会找出可能包含配置的代码片段或文件。
在后台,它通过为每个文件计算 “嵌入向量” 来对整个代码仓库建立索引(即将代码语义转化为数字向量),这样就可以有效地回答涉及整个项目的问题。它会找出最相关的代码块,然后把这些内容提供给 AI 进行回答。
智能重构与多文件编辑
Cursor 具备强大的重构能力,支持大范围或逻辑上的代码重构。这些操作可以通过自然语言指令完成。它使用的是一个专门的小型编辑模型,这与回答你问题的主语言模型是不同的。
行内代码补全(Tab 补全)
和 GitHub Copilot 类似,Cursor 在你打字时也会提供行内补全。但不同的是,Cursor 的 AI 更 “聪明”,不仅能预测下一个单词,还能根据语义预测接下来的几行代码,甚至是你可能进行的下一步逻辑操作。
其他提升效率的功能,比如 Cmd/Ctrl+K
还有一些快捷命令功能,比如按 Cmd+K 可以快速生成或编辑代码 —— 你只需要选中一段代码,按下快捷键,然后用自然语言描述你想做的修改(例如 “优化这个循环”),AI 就会自动完成修改。
Cursor 的底层原理
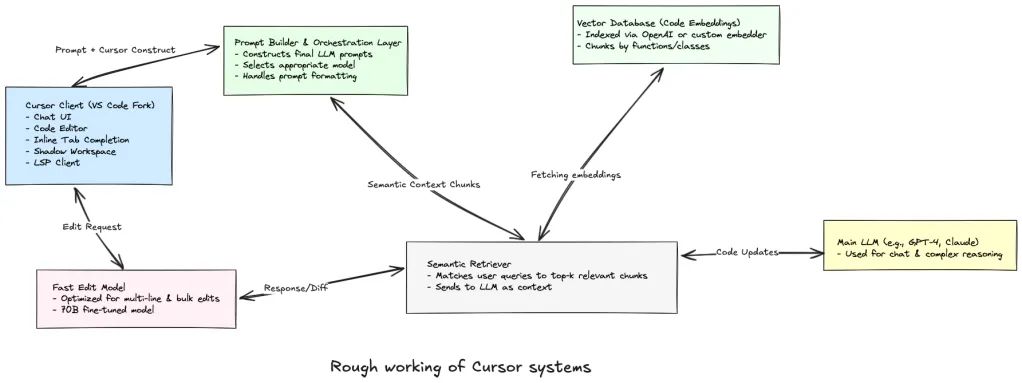
现在我们来深入了解一下支撑这些功能的技术架构。从整体上看,Cursor 由客户端应用(基于 VS Code 的编辑器)和一组后端 AI 服务构成。接下来我们将看看客户端和服务器是如何协作来完成语言模型提示、代码索引和修改应用的。
客户端 VS 原版 VS Code 有什么不同?
Cursor 的桌面应用是在 VS Code 的基础上开发的 “分支版本”,这意味着它复用了 VS Code 的核心编辑器、用户界面以及插件生态系统。这样,Cursor 可以直接拥有 VS Code 提供的大部分 IDE 功能(比如文本编辑、语法高亮、语言服务支持、调试等),然后在此基础上叠加自己的 AI 功能。
Cursor 的客户端包含一些自定义的 UI 元素,比如聊天侧边栏、Composer 面板,以及用于触发 AI 操作的快捷键(如 Tab、Cmd+K)。由于是完整分支而不是普通插件,Cursor 能将 AI 深度整合进开发流程中 —— 例如补全功能直接嵌入编辑器的建议系统,聊天助手也可以直接修改文件。
自定义沙盒环境的构建
Cursor 使用语言服务器(和 VS Code 一样,支持 Python、TypeScript、Go 等语言)来获取实时代码信息,提供 “跳转定义”、“查找引用”、错误提示等功能。Cursor 对这些能力进行了更有创新的利用。特别是它实现了一个叫做 “影子工作区(shadow workspace)” 的概念:这是一个隐藏的后台工作区,AI 可以在其中安全地测试修改,并从语言服务器获取反馈。
比如,当 AI 生成了一段代码,Cursor 会在一个隐藏的编辑器窗口中应用这些更改(不影响你当前的文件),然后让语言服务器检查有没有错误或类型问题。这些诊断结果会反馈给 AI,帮助它优化建议后再展示给你 —— 非常酷!
简而言之,客户端为 AI 提供了一个带有编译器和 linter 的沙盒开发环境,提高代码修改的准确性。(当前是通过一个不可见的 Electron 窗口来镜像你的项目,未来可能使用内核级文件系统代理来进一步加快隔离速度)
除了影子工作区,客户端还负责处理一些细节功能,比如 @ 符号上下文插入(你在提示中引用 @File 或 @Code 时,客户端知道要取出对应的文件或代码片段),以及 AI 修改的 UI 操作(比如点击 “播放” 按钮立即应用建议)。当你在聊天或 Composer 中使用 “立即应用” 功能时,客户端会接收来自 AI 的差异或新代码,并将其应用到项目中,可能还会显示预览或进行安全合并。
LLM 协调(大模型调用协调)
虽然有些轻量处理(比如代码拆分)在本地完成,核心 AI 运算则由 Cursor 的云端后端完成。当你触发一个 AI 功能时,客户端会整理好上下文(你的输入、选中代码等),然后发送请求给 Cursor 后端。
后端负责构建最终的大语言模型(LLM)提示语,调用模型接口并将结果返回给编辑器。即便你配置了自己的 OpenAI API 密钥,请求仍会先经过 Cursor 的后端,这样系统才能添加系统指令、代码上下文以及专属格式,确保模型理解你的需求。
多模型协调:大模型 + 自研模型
Cursor 使用多种 AI 模型:既有像 GPT-4 或 Claude 3.5 这样的顶级大型模型,也有专为特定用途训练的定制模型。
比如在代码聊天或复杂任务时,会调用高质量的大模型(如 GPT-4);而在自动补全、常规代码编辑等场景,则使用自研的轻量模型。Cursor 团队专门训练了一种名为 “Copilot++” 的自定义模型(灵感来自 Codex/Copilot),用来更精准地预测下一个代码操作。
此外还有一个专门为快速应用大规模代码修改设计的模型,称为 “Fast Apply 模型”,它是基于 Cursor 自身数据微调出来的。这个模型以 70B 参数的 Llama 为基础,通过 Fireworks 推理引擎部署,生成速度非常快 —— 超过每秒 1000 个 token,使用的是先进的 speculative decoding(推测解码)技术。
总之,后端有一个 LLM 协调层,会根据任务类型选择合适模型,优化提示语,并利用各种性能技巧(比如并行 token 生成)来实现低延迟响应。
嵌入存储与向量数据库
Cursor 的后端还包含一个向量数据库,用于存储整个项目的代码嵌入(embeddings),还有缓存层和请求路由逻辑。所有通信都经过隐私与性能优化:启用 “隐私模式” 时,后端不会保留你的任何代码或数据;即使关闭隐私模式,Cursor 也只会记录匿名统计数据用于模型优化,而且不会长期保存原始代码。
代码库索引与语义嵌入
代码库扫描
Cursor 能理解整个项目的核心在于其代码索引系统。当你首次打开一个项目时,Cursor 会在后台扫描并索引整个代码库。
具体怎么做:Cursor 会将每个文件拆分成更小的片段,并为每个片段计算一个向量嵌入。这种嵌入是代码语义的数字表达。Cursor 使用 OpenAI 的嵌入模型或自研模型生成这些向量,每段嵌入都带有元信息(例如文件名、行号)。
每段通常包含几百个 token。拆分的目的是既不超过模型 token 限制,又提升搜索精度。Cursor 使用智能拆分策略,不是简单地每 N 行切一次,而是借助像 tree-sitter 这样的工具按函数、类等逻辑结构划分,使每个片段都尽量自成一体,方便 AI 理解。
使用 RAG(检索增强生成)
一旦代码库索引完成,就能实现语义搜索。比如你问:“哪些地方调用了 authenticateUser 函数?”Cursor 会将你的问题转为一个向量,然后在向量数据库中查找最相近的片段,可能包括多个文件中的函数调用、定义、注释等。这些相关代码块会被拉入语言模型的上下文窗口。
这就是 Retrieval-Augmented Generation(RAG)方法:AI 不再局限于你当前编辑的文件,而是可以利用整个项目中的相关内容。
这就是 Cursor 实现 “全项目感知” 的方式。
提示构建与上下文管理
当你和 Cursor 的 AI 交互(无论是聊天还是指令),系统会在后台构建一个完整的提示语。这包括你的问题、相关代码上下文(来自打开文件或语义搜索)、可能的文档或示例,以及对话历史。同时还有系统级提示词,引导模型更好地响应。
Token 限制问题
因为模型有 token 限制,Cursor 会采用多种策略最大化有效信息,比如压缩不重要内容、分块处理长文本。如果你要重构一个 1000 行的文件,Cursor 可能会将其分块逐段处理,再组合成完整结果。
它还会利用 AST(抽象语法树)分析和静态分析结果来丰富上下文。例如你输入中提到一个函数名,系统可能会从语言服务器那里获取定义、类型信息,并一起提供给模型。
之前提到的影子工作区也属于上下文管理的一部分。在迭代编辑中,AI 可能先在后台尝试修改,再编译或检查,获取错误信息并重新调整建议。这个过程对用户是不可见的,但能大幅提高生成代码的质量。
编辑应用方式
Cursor 更倾向于让模型生成 “可应用的代码修改”,而不是普通的文字解释。例如你让它实现一个函数,它可能会直接返回完整的代码块;重构时,则可能返回代码 diff 或修改清单。Cursor 的界面会自动解析这些结果,并应用到项目中。
性能优化与自定义工具
为了保证流畅体验,Cursor 做了大量优化:
1、模型微调
Cursor 对其自身的大型语言模型进行了微调,用于代码编辑(“Fast Apply” 模型)。该模型旨在比通用模型更可靠地处理代码修改和多文件编辑。
2、推测解码(Speculative Decoding)
Cursor 利用 Fireworks 中的一项高级推理技术,即推测解码。在普通的 LLM 生成过程中,模型会依次生成标记,这可能会比较慢。而推测解码则允许一个辅助的 “草稿” 模型提前猜测并并行生成多个标记,然后主模型会迅速进行验证。
3、缓存优化
除了在后端缓存文件数据外,Cursor 可能还会缓存嵌入结果和搜索结果。如果您连续提出两个相似的问题,第二个问题在适当的情况下可以复用第一个问题的向量搜索结果,而无需再次访问数据库。
4、资源管理
运行大型模型和多个编辑器实例可能会占用大量资源。例如,“影子工作区” 功能会使某些资源使用量翻倍(因为会运行一个隐藏的 VSCode 窗口以及语言服务器)。Cursor 通过仅在需要时启动影子工作区并在闲置一段时间后将其关闭来缓解这一问题。
5、MCP 扩展协议
作为一项前瞻性功能,Cursor 支持模型上下文协议(MCP)。这使得外部工具或数据源能够与 Cursor 的人工智能相连接。例如,当您提出问题时,MCP 插件可以让人工智能查询您的数据库或从内部维基获取文档。
总结
Cursor 的工程架构是 AI 大模型与 IDE 实用工具的完美结合。通过代码索引与 RAG 技术,它让 AI 能够 “理解” 整个项目;借助 VS Code 基础设施,它让 AI 可以获得编译器、语言服务器的反馈;通过模型协调与缓存优化,它保证了响应速度和准确率。
正因如此,Cursor 已吸引了超过百万开发者使用!
参考资料
Cursor 官方文档与隐私政策 – 关于代码嵌入与数据处理的详细说明
Fireworks 博客 – Cursor 的关键功能与 LLM 性能数据
开发者访谈 – 介绍 Cursor 如何基于 VS Code 构建全代码感知系统
“语义代码搜索” – 解读 Cursor 的代码拆分、嵌入与 RAG 方法
译者:@飘飘
作者:@Aditya Rohilla
原文:https://adityarohilla.com/2025/05/08/how-cursor-works-internally/
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
“分享、点赞、在看” 支持一波👍

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









