







现代计算机的基本结构为五个部分:CPU、内存、总线、输入/输出设备。或许你了解了这些概念,但是你知道a=1+1在计算机中是如何执行的呢?
1、硬件结构介绍
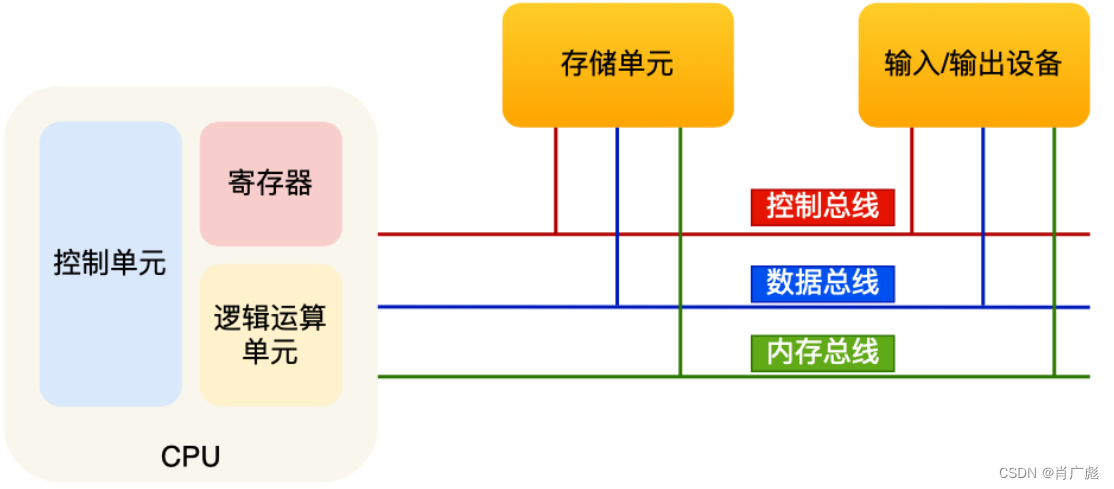
1.1、CPU
中央处理器也就是我们常说的 CPU,32 位和 64 位 CPU 最主要区别在于⼀次能计算多少字节数据:
32 位 CPU ⼀次可以计算 4 个字节;
64 位 CPU ⼀次可以计算 8 个字节;
这⾥的 32 位和 64 位,通常称为 CPU 的位宽,位宽越⼤,可以计算的数值就越⼤,⽐如说 32 位 CPU 能算的最⼤整数是 4294967295 。
CPU 内部还有⼀些组件,常⻅的有寄存器、控制单元和逻辑运算单元等。其中,控制单元负责控制 CPU⼯作,逻辑运算单元负责计算,⽽寄存器可以分为多种类,每种寄存器的功能⼜不尽相同。
有内存为什么还需要寄存器呢?内存离 CPU 太远了,⽽寄存器就在 CPU ⾥,还紧挨着控制单元和逻辑运算单元,⾃然计算时速度会很快。
常⻅的寄存器种类:
- 程序计数器,⽤来存储 CPU要执⾏下⼀条指令「所在的内存地址」,注意不是存储了下⼀条要执⾏的指令,此时指令还在内存中,程序计数器只是存储了下⼀条指令的地址。
- 指令寄存器,⽤来存放程序计数器指向的指令,也就是指令本身,指令被执⾏完成之前,指令都存储在这⾥。
- 通⽤寄存器,⽤来存放需要进⾏运算的数据,⽐如需要进⾏加和运算的两个数据。
1.2、内存
我们的程序和数据都是存储在内存,存储的区域是线性的。
数据存储的单位是⼀个⼆进制位(bit),即 0 或 1。最⼩的存储单位是字节(byte),1 字节等于 8 位。
内存的地址是从 0 开始编号的,然后⾃增排列,最后⼀个地址为内存总字节数 - 1,这种结构好似我们程序⾥的数组,所以内存的读写任何⼀个数据的速度都是⼀样的。
32 位 CPU 最⼤只能操作 4GB 内存,就算你装了 8 GB 内存条,也没⽤。⽽ 64 位 CPU 寻址范围则很⼤,理论最⼤的寻址空间为 2^64 。
1.3、总线
总线是⽤于 CPU 和内存以及其他设备之间的通信,
总线可分为 3 种:
- 地址总线,⽤于指定 CPU 将要操作的内存地址;
- 数据总线,⽤于读写内存的数据;
- 控制总线,⽤于发送和接收信号,⽐如中断、设备复位等信号,CPU 收到信号后⾃然进⾏响应,这时也需要控制总线;
当 CPU 要读写内存数据的时候,⼀般需要通过两个总线:⾸先要通过「地址总线」来指定内存的地址;再通过「数据总线」来传输数据;
1.4、输入/输出设备
输⼊设备向计算机输⼊数据,计算机经过计算后,把数据输出给输出设备。期间,如果输⼊设备是键盘,按下按键时是需要和 CPU 进⾏交互的,这时就需要⽤到控制总线了。
2、程序执行的基本过程
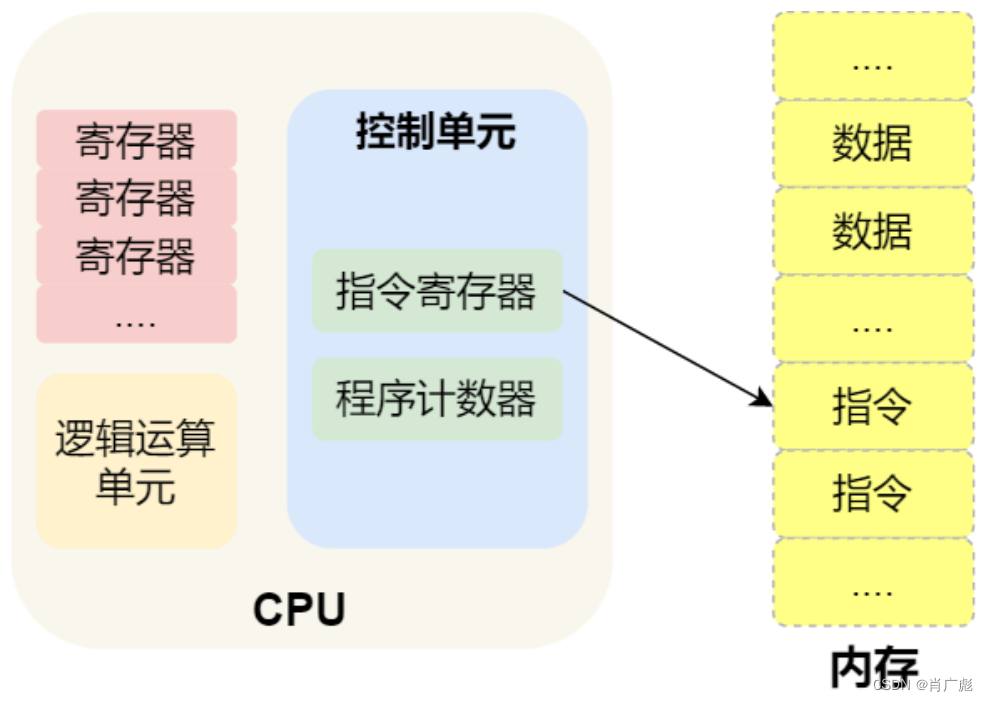
那 CPU 执⾏程序的过程如下:
- 第⼀步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过「数据总 线」将指令数据传给 CPU,CPU收到内存传来的数据后,将这个指令数据存⼊到「指令寄存器」。
- 第⼆步,CPU分析「指令寄存器」中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执⾏;
- 第三步,CPU执⾏完指令后,「程序计数器」的值⾃增,表示指向下⼀条指令。这个⾃增的⼤⼩,由 CPU 的位宽决定,⽐如 32 位的 CPU,指令是 4个字节,需要 4 个内存地址存放,因此「程序计数 器」的值会⾃增 4;
简单总结⼀下就是,⼀个程序执⾏的时候,CPU 会根据程序计数器⾥的内存地址,从内存⾥⾯把需要执⾏的指令读取到指令寄存器⾥⾯执⾏,然后根据指令⻓度⾃增,开始顺序读取下⼀条指令。
CPU 从程序计数器读取指令、到执⾏、再到下⼀条指令,这个过程会不断循环,直到程序执⾏结束,这个不断循环的过程被称为 CPU 的指令周期。
3、a=1+1执行的详细过程
CPU 是不认识 a = 1 + 2 这个字符串,这些字符串只是⽅便我们程序员认识,要想这段程序能跑起来,还需要把整个程序翻译成汇编语⾔的程序,这个过程称为编译成汇编代码。
针对汇编代码,我们还需要⽤汇编器翻译成机器码,这些机器码由 0 和 1 组成的机器语⾔,这⼀条条机器码,就是⼀条条的计算机指令,这个才是 CPU 能够真正认识的东⻄。
下⾯来看看 a = 1 + 2 在 32 位 CPU 的执⾏过程。程序编译过程中,编译器通过分析代码,发现 1 和 2 是数据,于是程序运⾏时,内存会有个专⻔的区域来存放这些数据,这个区域就是「数据段」。如下图,数据 1 和 2 的区域位置:
数据 1 被存放到 0x100 位置;
数据 2 被存放到 0x104 位置;
注意,数据和指令是分开区域存放的,存放指令区域的地⽅称为「正⽂段」。
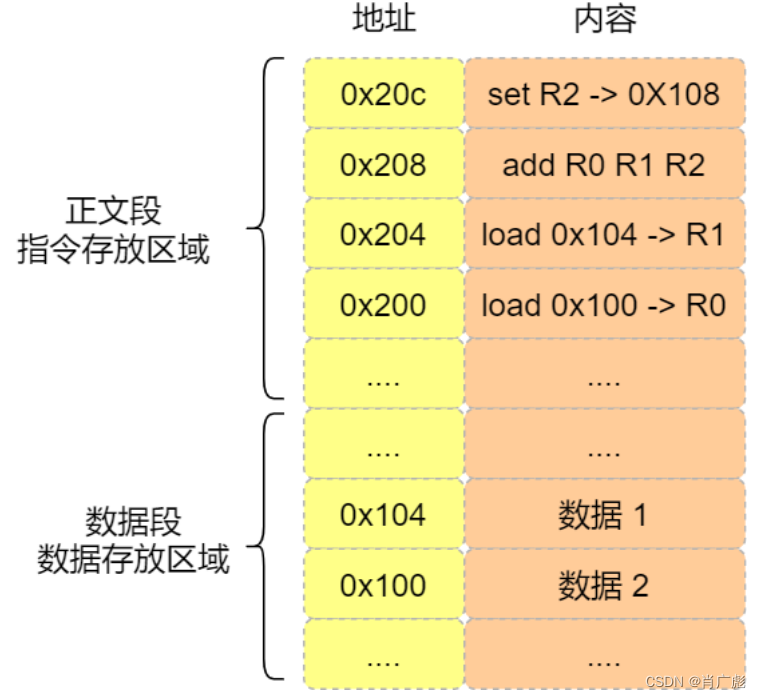
编译器会把 a = 1 + 2 翻译成 4 条指令,存放到正⽂段中。如图,这 4 条指令被存放到了 0x200 ~ 0x20c的区域中:
0x200 的内容是 load 指令将 0x100 地址中的数据 1 装⼊到寄存器 R0 ;
0x204 的内容是 load 指令将0x104 地址中的数据 2 装⼊到寄存器 R1 ;
0x208 的内容是 add 指令将寄存器 R0 和 R1的数据相加,并把结果存放到寄存器 R2 ;
0x20c 的内容是 store 指令将寄存器 R2 中的数据存回数据段中的 0x108地址中,这个地址也就 是变量 a 内存中的地址;
编译完成后,具体执⾏程序的时候,程序计数器会被设置为 0x200 地址,然后依次执⾏这 4 条指令。
上⾯的例⼦中,由于是在 32 位 CPU 执⾏的,因此⼀条指令是占 32 位⼤⼩,所以你会发现每条指令间隔4个字节。如果是 64 位 CPU 执⾏的,⼀条指令是占 64 位⼤⼩,你会发现每条指令间隔8个字节。
⽽数据的⼤⼩是根据你在程序中指定的变量类型,⽐如 int 类型的数据则占 4 个字节, char 类型的数据则占 1 个字节。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









