







做的商城版小程序需要退款功能,今天研究了下退款功能的实现
已经有支付demo文件
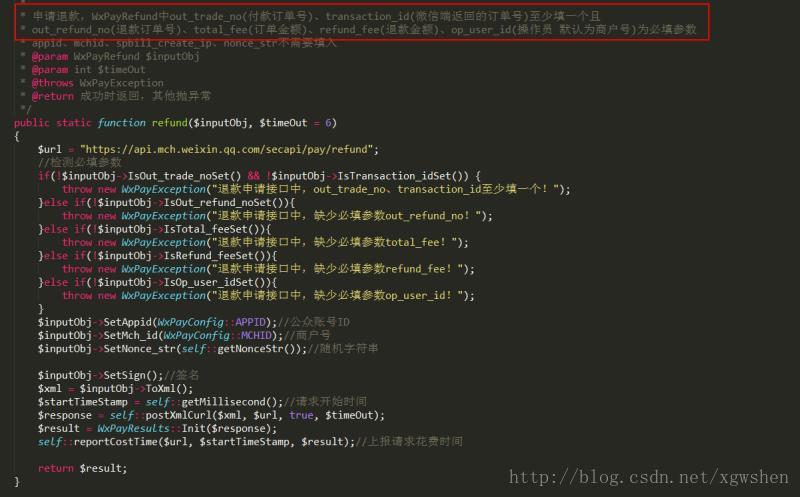
看到WxPayApi.php代码中退款的必填项:
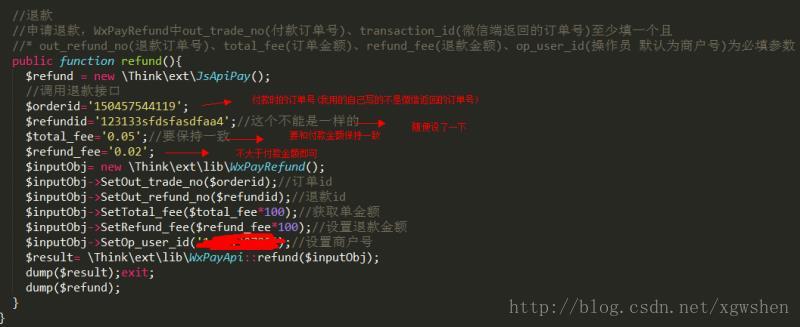
根据接口文档里的必填项写了一个接口,我用的是tp3.2框架,首先把这些文件放到框架的\ThinkPHP\Library\Think文件下面,文件名改为.class.php后缀,接口文件里的命名空间和应用路径做相应修改.以便引用;
在控制器里写了一个refund方法:
支付功能已经做过了,下单付款后
 本文介绍了在开发商城版微信小程序时如何实现退款功能。通过研究WxPayApi.php代码,确定退款必填项,并在ThinkPHP 3.2框架下创建退款接口。在实现过程中遇到了curl错误58,原因是证书文件路径设置为服务器的绝对路径。经过调整,成功发送退款请求,手机微信也接收到退款通知。同时,文章提到了在退款过程中可能出现的错误情况,如支付订单号、金额填写错误以及重复请求。
本文介绍了在开发商城版微信小程序时如何实现退款功能。通过研究WxPayApi.php代码,确定退款必填项,并在ThinkPHP 3.2框架下创建退款接口。在实现过程中遇到了curl错误58,原因是证书文件路径设置为服务器的绝对路径。经过调整,成功发送退款请求,手机微信也接收到退款通知。同时,文章提到了在退款过程中可能出现的错误情况,如支付订单号、金额填写错误以及重复请求。
已经有支付demo文件
看到WxPayApi.php代码中退款的必填项:
根据接口文档里的必填项写了一个接口,我用的是tp3.2框架,首先把这些文件放到框架的\ThinkPHP\Library\Think文件下面,文件名改为.class.php后缀,接口文件里的命名空间和应用路径做相应修改.以便引用;
在控制器里写了一个refund方法:
支付功能已经做过了,下单付款后
 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















