







前边几节讲了proc的实现和管理,还有一个重要的功能没有提到,那就是proc目录项的查找。
在查找的过程中,用户程序把proc看作是普通文件系统里的文件;也就是说当查找目录项时,do_lookup会调用real_lookup函数执行与文件系统相关的查找,real_lookup则会调用proc根节点inode的 proc_root_inode_operations中的proc_root_lookup函数,其定义为:
static const struct inode_operations proc_root_inode_operations = {
.lookup = proc_root_lookup,
.getattr = proc_root_getattr,
};
proc_root_lookup函数从/proc开始查找。该函数的实现比较简单,只要由两个函数执行不同类型的查找过程,其流程图如下:
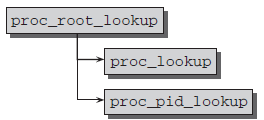
proc_lookup:查找proc中的非进程文件目录项
proc_pid_lookup:查找进程相关的文件目录项
其函数定义为:
static struct dentry *proc_root_lookup(struct inode * dir,
struct dentry * dentry, struct nameidata *nd)
{
if (!proc_lookup(dir, dentry, nd)) {
return NULL;
}
return proc_pid_lookup(dir, dentry, nd);
}
proc_lookup实现
proc的实现比较简单,在这里就接合代码说明,不再画流程图。
struct dentry *proc_lookup(struct inode * dir, struct dentry *dentry, struct nameidata *nd)
{
struct inode *inode = NULL;
struct proc_dir_entry * de;
int error = -ENOENT;
/* 大内核锁 */
lock_kernel();
spin_lock(&proc_subdir_lock);
/* 获得与inode *dir对应的proc_dir_entry */
de = PDE(dir);
if (de) {
/* 遍历 de链表,查找与denty匹配的 proc_dir_entry */
for (de = de->subdir; de ; de = de->next) {
/* 如果名字长度不同,接着进行下一个查找 */
if (de->namelen != dentry->d_name.len)
continue;
/* 如果匹配成功,进行设置 */
if (!memcmp(dentry->d_name.name, de->name, de->namelen)) {
unsigned int ino;
/* ??没弄明白shadow_proc函数的作用,知道的请告知?? */
if (de->shadow_proc)
de = de->shadow_proc(current, de);
ino = de->low_ino;
/* 增加de的计数atomic_inc(&de->count); */
de_get(de);
spin_unlock(&proc_subdir_lock);
error = -EINVAL;
/* 获取与de的inode */
inode = proc_get_inode(dir->i_sb, ino, de);
spin_lock(&proc_subdir_lock);
break;
}
}
}
/* 释放锁资源 */
spin_unlock(&proc_subdir_lock);
unlock_kernel();
if (inode) {
/* 设置dentry的d_op */
dentry->d_op = &proc_dentry_operations;
/* 将dentry加到hash链表上 */
d_add(dentry, inode);
return NULL;
}
de_put(de);
return ERR_PTR(error);
}
proc_pid_lookup实现
不论是设计之初还是现在,proc文件系统的主要任务便是输出系统进程的详细信息。
proc_pid_lookup函数的目标便是产生一个inode以便进行与PID相关的进一步操作,这是因为/proc/pid的inode包含了所有与进程相关的信息的文件。该函数针对两类进程(当前进程和其它进程)进行不同的操作,这也把函数分成截然不同的两个步骤。该函数的执行流程图如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1312
1312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









