










【论文题目】
advPattern: Physical-World Attacks on Deep Person Re-Identification via Adversarially Transformable Patterns
Abstract
本文首次尝试对深度reID实施鲁棒的物理世界攻击。提出了一种新颖的攻击算法,称为advPattern,用于在衣服上生成对抗模式,它通过学习不同相机之间图像对的变化来拉近来自同一相机的图像特征,同时将来自不同相机的特征推得更远。通过穿着本文设计的"隐形斗篷",敌手可以逃避人员搜索,或者假冒目标人员来欺骗物理世界中的深度身份识别模型。
使用Market1501和本文建立的PRCS数据集评估本文的可变换模式在对手服装上的有效性。实验结果表明,在逃避攻击下,reID模型匹配对手的rank-1准确率从87.9%下降到27.1%。此外,在模拟攻击下,敌手可以以47.1%的1级准确率和67.9 %的mAP模拟目标人物。结果表明,深度reID系统容易受到我们的物理攻击。
3 System Model
在这一部分中,我们首先介绍了威胁模型,然后介绍了我们的设计目标。
3.1 Threat Model
工作主要集中在对基于DNN的reID系统的物理可实现的攻击上,该系统可以实时捕获行人,并在非重叠的摄像机中自动搜索感兴趣的人。
通过将探测图像(probe image, 查询的图像)提取的特征与从其他相机实时采集的一组不断更新的画廊图像(gallery image)的特征进行比较,reID系统从图库中输出被认为与查询图像最相似的图像。
假设攻击者对训练好的深度reID模型具有白盒访问权限,因此他具有模型结构和参数的知识,并且只在推理阶段对reID模型实施攻击。不允许对手操纵数字查询图像或从相机收集的图库图像。 此外,对手在攻击reID系统时不得改变自己的物理外观,以免引起人类监督者的怀疑。这些合理的假设使得在reID系统上成功实现物质世界攻击具有一定的挑战性。
3.2 Design Objectives
提出两种攻击情境,逃避攻击(Evading Attack)和冒充攻击(Impersonation Attack)。
逃避攻击:躲避攻击是一种无针对性的攻击:reID模型被愚弄,将对手比作一个除自己之外的任何人,看起来好像对手穿着隐形斗篷。形式上,一个reID模型
f
θ
(
⋅
,
⋅
)
f_\theta(\cdot,\cdot)
fθ(⋅,⋅)输出一对图像的相似度分数,其中
θ
\theta
θ是模型参数。给定对手的探测图像
p
a
d
v
p_{adv}
padv,对手的画廊图像
g
a
d
v
g_{adv}
gadv,尝试找到一个贴到对手衣服上的图案
δ
\delta
δ,通过下面的优化问题,使得reID模型错误识别:
max
D
(
δ
)
,
s
.
t
.
R
a
n
k
(
f
θ
(
p
a
d
v
+
δ
,
g
a
d
v
+
δ
)
)
>
K
(1)
\max D(\delta), s.t. Rank(f_\theta(p_{adv+\delta},g_{adv+\delta}))>K\tag{1}
maxD(δ),s.t.Rank(fθ(padv+δ,gadv+δ))>K(1)
其中
D
(
⋅
)
D(\cdot)
D(⋅)用于测量生成的图案的真实性。与以往的工作旨在生成视觉上不明显的扰动不同,本文尝试为摄像头传感生成可见图案,同时使生成的图案与衣服上的自然装饰图案无法区分。只有当图像对
(
p
a
d
v
+
δ
,
g
a
d
v
+
δ
)
(p_{adv+\delta},g_{adv+\delta})
(padv+δ,gadv+δ)排在top-K结果后面时,对抗模式才能成功构建,这意味着reID系统无法实现对手的跨相机图像匹配。
冒充攻击:是一种目标攻击(targetted attack),可以看作是逃避攻击的一种扩展:对手试图欺骗身份识别模型,使其将自己识别成目标身份。
给定目标身份图像
I
t
I_t
It,形式上冒充攻击是优化下面的优化过程:
max
D
(
δ
)
,
s
.
t
.
{
R
a
n
k
(
f
θ
(
p
a
d
v
+
δ
,
g
a
d
v
+
δ
)
)
>
K
R
a
n
k
(
f
θ
(
p
a
d
v
+
δ
,
I
t
)
)
<
K
(2)
\max D(\delta), s.t. \begin{equation} \left\{ \begin{aligned} Rank(f_\theta(p_{adv+\delta},g_{adv+\delta}))>K \\ Rank(f_\theta(p_{adv+\delta}, I_t)) < K \end{aligned} \right. \end{equation}\tag{2}
maxD(δ),s.t.{Rank(fθ(padv+δ,gadv+δ))>KRank(fθ(padv+δ,It))<K(2)
4 Adversarial Pattern Generation
4.1 Transformable Patterns across Camera Views
对于逃避攻击,给定由对手构建的生成集 X = ( x 1 , x 2 , ⋯ , x m ) X=(x_1,x_2,\cdots,x_m) X=(x1,x2,⋯,xm),包含了从 m m m个不同的摄像机捕捉的对手图片。对于每张 X X X中图像 x i x_i xi,计算对抗图像 x i ′ = o ( x i , T i ( δ ) ) x_i'=o(x_i,T_i(\delta)) xi′=o(xi,Ti(δ))。这表示将变换后的 x i x_i xi对应区域 T i ( ⋅ ) T_i(\cdot) Ti(⋅)与生成的图案 δ δ δ进行叠加。这里 T i ( δ ) T_i(\delta) Ti(δ)是对 δ \delta δ的透视变换操作。
通过优化下面的问题生成可转移的对抗性图案
δ
\delta
δ:
argmin
δ
∑
i
=
1
m
∑
j
=
1
m
f
θ
(
x
i
′
,
x
j
′
)
,
s
.
t
.
i
≠
j
(3)
{\underset{\delta}{\operatorname{arg min}}}\sum_{i=1}^m\sum_{j=1}^m f_\theta(x_i',x_j'),s.t. i\neq j\tag{3}
δargmini=1∑mj=1∑mfθ(xi′,xj′),s.t.i=j(3)
迭代地最小化来自不同摄像机的对手图像的相似度分数,以通过生成的对抗模式逐渐进一步提取来自不同摄像机的对手图像的特征。
对于冒充攻击,给定目标行人图像
I
t
I_t
It,优化下面问题:
argmin
δ
∑
i
=
1
m
∑
j
=
1
m
f
θ
(
x
i
′
,
x
j
′
)
−
α
(
f
θ
(
x
i
′
,
I
t
)
+
f
θ
(
x
j
′
,
I
t
)
)
,
s
.
t
.
i
≠
j
(4)
{\underset{\delta}{\operatorname{arg min}}}\sum_{i=1}^m\sum_{j=1}^m f_\theta(x_i',x_j')-\alpha(f_\theta(x_i',I_t)+f_\theta(x_j',I_t)),s.t. i\neq j\tag{4}
δargmini=1∑mj=1∑mfθ(xi′,xj′)−α(fθ(xi′,It)+fθ(xj′,It)),s.t.i=j(4)
其中
α
\alpha
α控制不同项的强度。通过在Eq.4中加入第二项,额外最大化敌手图像与目标人物图像的相似性分数,以生成一个更强大的对抗模式来拉近敌手图像与目标人物图像的提取特征。
4.2 Scalable Patterns in Varying Positions
对抗模式应该能够在任何位置实施成功的攻击,这意味着攻击应该与位置无关。为了实现这一目标,本文进一步改进了对抗模式在不同位置上的可扩展性。
由于无法精确捕捉视角变换的分布,因此采用多位置采样策略增加生成集的体量,以近似生成可扩展对抗性图案的图像分布。对抗者的扩展生成集 X C X^C XC是通过收集从各个摄像机视角拍摄的不同距离和角度的对抗者图像,并对原始收集的图像进行平移和缩放等图像变换合成实例构建的。
对于逃避攻击,从
X
C
X^C
XC中给定三元组
t
r
i
k
=
<
x
k
o
,
x
k
+
,
x
k
−
>
tri_k=<x_k^o,x_k^+,x_k^->
trik=<xko,xk+,xk−>,其中
x
k
o
x_k^o
xko和
x
k
+
x_k^+
xk+是同一摄像机下的行人图像,和
x
k
−
x_k^-
xk−是不同摄像机下的行人图像。对于
t
r
i
k
tri_k
trik中的每个图像
x
k
x_k
xk,计算对抗图像
x
k
′
x_k'
xk′为
o
(
x
k
,
T
k
(
δ
)
)
o(x_k,T_k(\delta))
o(xk,Tk(δ))。每次迭代时随机选择一个三元组来求解下列优化问题:
argmin
δ
E
t
r
i
k
∼
X
C
f
θ
(
(
x
k
o
)
′
,
(
x
k
−
)
′
)
−
β
f
θ
(
(
x
k
o
)
′
,
(
x
k
+
)
′
)
(5)
{\underset{\delta}{\operatorname{arg min}}} \mathbb{E}_{tri_k\sim X^C} f_\theta((x_k^o)',(x_k^-)')-\beta f_\theta((x_k^o)',(x_k^+)')\tag{5}
δargminEtrik∼XCfθ((xko)′,(xk−)′)−βfθ((xko)′,(xk+)′)(5)
其中
β
\beta
β是权衡不同项的超参数。式中:目标式Eq.5是最小化
x
k
o
x_k^o
xko与
x
k
−
x_k^-
xk−的相似度得分,以区分跨摄像机视角的行人图像,而最大化
x
k
o
x_k^o
xko与
x
k
+
x_k^+
xk+的相似度得分,以保持同一摄像机视角下行人图像的相似性。
在优化过程中,生成模式从增广生成集
X
C
X^C
XC中学习可伸缩性,以拉近从同一相机中提取的人物图像特征,同时将来自不同相机的特征推得更远,如图4所示。
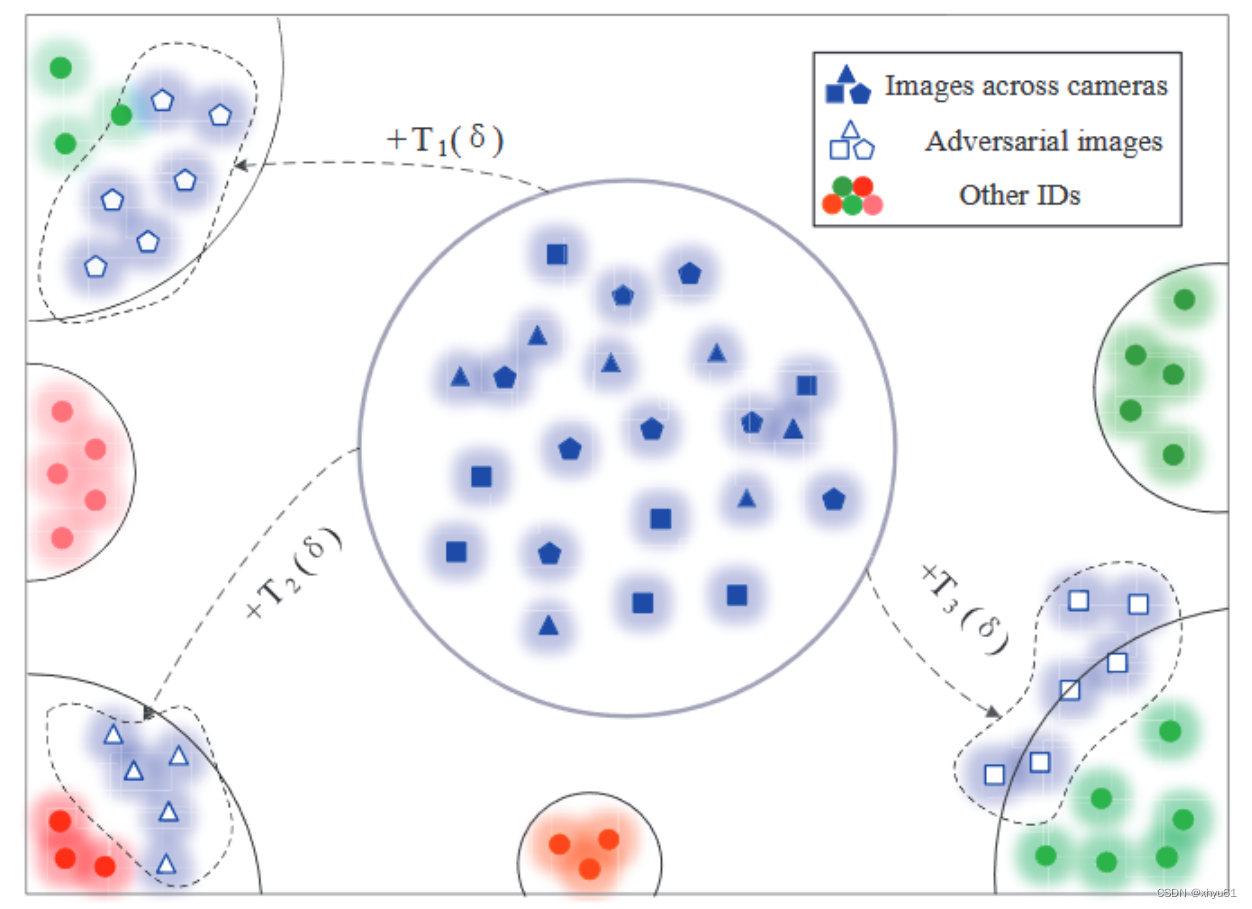
图4:可扩展对抗模式如何工作的说明。通过添加生成的对抗模式,将来自同一相机视图的对抗图像在特征空间中聚集在一起。同时,来自不同摄像头的对抗图像的距离变得更远。
对于冒充攻击,给定目标的图像集合
I
t
I^t
It,每个迭代选择一个四元组
q
u
a
d
k
=
<
x
k
o
,
x
k
+
,
x
k
−
,
t
k
>
quad_k=<x_k^o,x_k^+,x_k^-,t_k>
quadk=<xko,xk+,xk−,tk>,由
t
r
i
k
tri_k
trik和从
I
t
I^t
It中选择的
t
k
t_k
tk组成。迭代地优化下面的问题:
argmax
δ
E
q
u
a
d
k
∼
{
X
C
,
I
t
}
f
θ
(
(
x
k
o
)
′
,
t
k
)
+
λ
1
f
θ
(
(
x
k
o
)
′
,
(
x
k
+
)
′
)
−
λ
2
f
θ
(
(
x
k
o
)
′
,
(
x
k
−
)
′
)
(6)
{\underset{\delta}{\operatorname{arg max}}}\mathbb{E}_{quad_k\sim \{X^C,I^t\}}f_\theta((x_k^o)',t_k)+\lambda_1 f_\theta((x_k^o)',(x_k^+)')-\lambda_2 f_\theta((x_k^o)',(x_k^-)')\tag{6}
δargmaxEquadk∼{XC,It}fθ((xko)′,tk)+λ1fθ((xko)′,(xk+)′)−λ2fθ((xko)′,(xk−)′)(6)
其中
λ
1
\lambda_1
λ1和
λ
2
\lambda_2
λ2是控制不同目标的强度的超参数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









