









一、Hbase来源
- hbase是一个开源的、分布式的、多版本的、可扩展的、非关系型的数据库。
- hbase是big table的开源的java版本,建立在hdfs基础之上,提供高可靠性、高性能的、列式存储、可伸缩、近实时读写的nosql的数据库系统
- 数据量越来越大,传统的关系型数据库不能满足存储和查询的需求。而hive虽然能够满足存储的要求,但是hive的本质也是利用底层的mr程序,所以读写速度不快。而且hive不能满足非结构化的、半结构化的存储,hive的主要作用是做分析和统计,hive用于存储是无意义的。
二、Hbase介绍
2.1 Hbase定义
- Hbase是一个数据库—可以提供数据的实时随机读写
- Hbase与mysql、oralce、db2、sqlserver等关系型数据库不同,它是一个NoSQL数据库(非关系型数据库)
2.2Hbase的特性
- HBase的表模型与关系型数据库的表模型不同。
- HBase的表没有固定的字段定义。
- HBase的表中每行存储的都是一些key-value对。
- HBase的表中有列簇的划分,用户可以指定将哪些kv插入哪个列簇。
- HBase的表在物理存储上,是按照列簇来分割的,不同列簇的数据一定存储在不同的文件中
- HBase的表中的每一行都固定有一个行键,而且每一行的行键在表中不能重复
- HBase中的数据,包含行键,包含key,包含value,都是byte[ ]类型,HBase不负责为用
户维护数据类型 - HBase对事务的支持很差
2.3Hbase应用场景
- 服务器从app端采集数据
- 通过日志采集工具做数据采集
- 经过etl
- 数据分析后的结果可以存储到hbase中
三、Hbase表模型
3.1 Hbase表模型的要点
- 一个表,有表名
- 一个表可以分为多个列簇(不同列簇的数据会存储在不同文件中)
- 表中的每一行有一个“行键rowkey”,而且行键在表中不能重复
- 表中的每一对kv数据称作一个cell
- hbase可以对数据存储多个历史版本(历史版本数量可配置)
- 整张表由于数据量过大,会被横向切分成若干个region(用rowkey范围标识),不同region的数据也存储在不同文件中。
- hbase会对插入的数据按顺序存储。
7.1 要点一:首先会按照行键排序
7.2 要点二:同一行里面的kv会按照列簇排序,再按照k排序
3.2 Hbase的表中能存储数据类型
- hbase中支持byte[]
- 此处debyte[]包括了: rowkey,key,value,列簇名,表名
- Hbase基于hadoop:Hbase的存储依赖于HDFS
3.3Hbase的表结构图示
mysql中数据存储结构
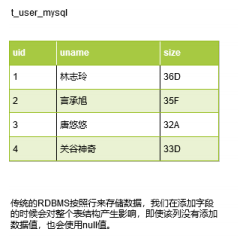
hbase数据存储结构

四、Hbase工作机制
4.1图示

4.2组件说明
- Client : hbase客户端,
1.包含访问hbase的接口。比如,linux shell,java api。
2.除此之外,它会维护缓存来加速访问hbase的速度。比如region的位置信息。 - Zookeeper :
1.监控Hmaster的状态,保证有且仅有一个活跃的Hmaster。达到高可用。
2.它可以存储所有region的寻址入口。如:root表在哪一台服务器上。
3.实时监控HregionServer的状态,感知HRegionServer的上下线信息,并实时通知给Hmaster。
4.存储hbase的部分元数据。 - HMaster :
1.为HRegionServer分配Region(新建表等)。
2.负责HRegionServer的负载均衡。
3.负责Region的重新分配(HRegionServer宕机之后的Region分配,HRegion裂变:当Region过大之后的拆分)。
4.Hdfs上的垃圾回收。
5.处理schema的更新请求 - HRegionServer :
1.维护HMaster分配给的Region(管理本机的Region)。
2.处理client对这些region的读写请求,并和HDFS进行交互。
3.负责切分在运行过程中组件变大的Region。 - HLog : 对HBase的操作进行记录,使用WAL写数据,优先写入log(put操作:先写日志再写memstore,这样可以防止数据丢失,即使丢失也可以回滚)。
- HRegion : HBase中分布式存储和负载均衡的最小单元,它是表或者表的一部分。
- Store :相当于一个列簇
- Memstore :内存缓冲区,用于将数据批量刷新到hdfs中,默认大小为128M
- HStoreFile : 不过是一个逻辑概念。HBase中的数据是以HFile存储在Hdfs上。
4.3组件之间的关系
- hmaster:hregionserver=1:*
- hregionserver:hregion=1:*
- hregionserver:hlog=1:1
- hregion:hstore=1:*
- store:memstore=1:1
- store:storefile=1:*
- storefile:hfile=1:1
4.4小结
-
rowkey:行键,和mysql的主键同理,不允许重复。
-
columnfamily: 列簇,列的集合之意。
-
column:列
-
timestamp:时间戳,默认显示最新的时间戳,可用于控制k对应的多个版本值,默认查最新的
数据 -
version:版本号,表示记录数据的版本
-
cell:单元格,kv就是cell
-
模式:无
-
数据类型:只存储byte[]
-
多版本:每个值都可以有多个版本
-
列式存储:一个列簇存储到一个目录
-
稀疏存储:如果一个kv为null,不占用存储空间














 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









