






目录
写在前面
很多玩过视频生成的宝儿都有过这样的疑问:“为什么可灵、即梦等视频生成模型只能生成大约10秒的视频?”要回答这个问题,我们首先需要了解当前主流的视频生成模型的结构。简而言之:无论多长的视频,都是“嗷”一下直接生成的;而不是一帧一帧逐步生成的。这样做的好处是可以保证内容的一致性,但也受到计算能力的限制,生成视频的长度也将受到限制。
一、朴素的直觉
最简单的想法是,先根据提示词生成一张图片,然后根据前一帧生成下一帧,最后将它们拼接成视频。
这个方法确实是视频生成的一个可行思路,但目前大模型生成视频的技术路径并没有完全采用这种方式。

1.累积误差与画面崩坏
如果每一帧都基于前一帧生成,微小的误差(如物体位置、形状或纹理上的偏差)会随着时间的推移不断累积,最终导致画面出现严重的扭曲,甚至和提示词完全不符。例如,生成一个“行走的人”,如果每一帧对腿部位置的预测稍有偏差,几秒钟后腿部可能会扭曲或者与身体不连贯。
2.时序一致性的挑战
简单的“逐帧生成”难以保证长期的时序逻辑(如物体运动的轨迹、物理规律等)。模型需要理解动作的整体连续性(例如,“挥手”动作是从手臂起始到最高点的一个完整过程),而不仅仅是依赖前一帧的内容。例如,如果前一帧显示“球在空中”,下一帧可能生成“球掉到地上”或“球继续飞行”,两者的逻辑可能并不一致。
3.计算效率低下
逐帧生成高分辨率图片(例如每秒30帧)需要串行计算,时间开销非常大。而现代的视频生成模型(例如扩散模型)通过并行计算多帧图像或优化潜在空间来提升速度,从而避免逐帧计算带来的低效。
4.动态内容与静态背景的矛盾
如果采用简单的逐帧生成,动态物体(如奔跑的狗)和静态背景(如草地)可能难以协调,造成背景抖动或者物体与背景的互动不自然(例如狗的脚陷入地面)。
二、时空联合建模
当前视频生成的主流技术方案—时空联合建模,指的是在时空维度上(即高度×宽度×时间)直接生成视频,并将时间作为一个额外的维度来建模,以保证帧与帧之间的连贯性。简单来说,就是在输入时就确定视频的高度、宽度和时长,无论视频有多长,都可以一次性地端到端生成。目前,VAE+DiT组合是最主流的方式。
可灵和即梦的生成视频模型都没有开源 ,所以我们以开源的CogVideo为例,以下是CogVideo的Comfyui结构:
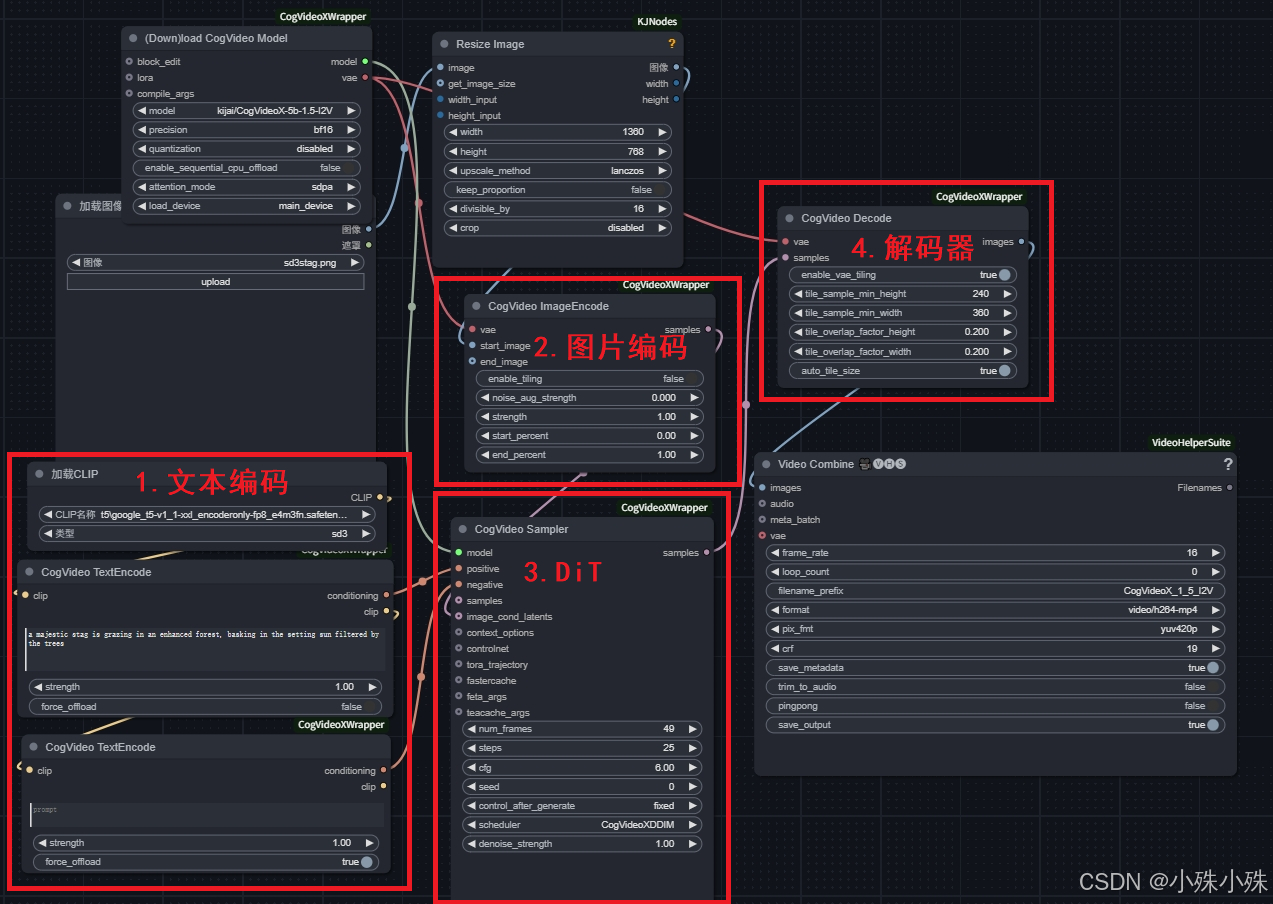
可以看到,整个流程是文本经过文本编码器(例如T5)得到文本潜在表示、引导图经过图像编码器(VAE编码器)的能到图像潜在表示、然后两者作为条件配合采样的噪声送入DiT进行图像生成(去噪)、最后进行图像解码器(VAE解码器)还原成视频。VAE+DiT的组合非常流行,目前大多数视频生成大模型都采用这种结构。

具体来说,视频生成过程可以分为以下几个步骤:
1.文本编码(t5)
输入的文本描述会通过文本编码器(如基于Transformer的编码器)转化为固定维度的文本特征向量。假设文本描述为“在公园里奔跑的小狗”,文本编码器将其转换为一个高维的向量(例如:[BERT/CLIP等模型输出的特征向量])。
2.图像编码(VAE Encoder)
如果输入的文本需要引导视频的具体帧,图像也会被编码,例如通过VAE的编码器。想了解VAE请看:【大模型】通俗解读变分自编码器VAE_vae模型-CSDN博客
3.DiT
在DiT模型中,首先会生成一个包含噪声的张量,通常它的形状为:
其中H是的高度,W是宽度,C是通道数,T是帧数(时间维度)。从潜在空间中的噪声逐步生成高质量的图像或视频。值得注意的是这里的高度和宽度是经过VAE压缩的,不是原图的宽高,如:要生成512x512的视频,VAE的压缩比是8,那这里的宽高就是64x64。
4.图像解码器(VAE Decoder)
解码器将潜在空间中的表示(latent representation)转换为实际的视频数据。上述就是现代视频生成大模型的标准结构,虽然不同厂商的模型在细节上可能有所差异,但整体框架基本类似。
三、为什么是VAE+DiT组合
1.VAE的核心优势
VAE(变分自编码器)的优势在于能够学习数据的潜在空间。然而,在训练过程中,VAE可能会遇到KL散度问题,导致生成的样本在锐利度和细节上不够丰富。
2.DiT的优势
DiT(去噪图像变换模型)能够生成非常高质量的图像,但它通常需要更长的训练时间,而且在处理复杂的视频生成任务时,可能在潜在空间的采样上遇到困难。
3.VAE+DiT的组合
VAE可以帮助DiT避免模式崩溃,并增强样本的多样性,而DiT则可以帮助VAE生成更加细致和高质量的样本。因此,VAE+DiT的结合被认为是一个非常契合且优雅的选择。
四、为什么是10秒的视频

目前,AI生成的视频大多比较短(通常在10秒以内)。这背后有技术限制、计算成本和数据质量等多方面的原因:
1.技术限制:长视频生成的复杂度急剧上升
随着视频长度的增加,保持画面和动作的连贯性变得更加困难。即使采用时空联合建模(如3D扩散模型),模型也很难保证几十秒内物体运动、光照、视角等方面的一致性。例如,生成一个“人从走路到跑步”的10秒视频可能可行,但生成“一个人从起床、洗漱到出门”的1分钟视频,就容易出现动作中断或逻辑错误(如突然穿墙)。
2.计算成本:生成长视频需要大量资源
生成1秒钟30帧的1080p视频,意味着需要处理30张高分辨率的图像;而生成10秒的视频就需要处理300张图像。即使采用潜在空间压缩(如稳定视频扩散),显存的需求仍会大幅增加。例如,Sora生成1分钟视频时需要数千块GPU并行计算,这带来了巨大的成本压力。
3.数据与标注的挑战
高质量的长视频数据较少:互联网上的长视频通常包含剪辑和镜头切换,而AI需要的是一镜到底、连续的画面。现有的数据集(如Kinetics、Something-Something)大多以短片段为主,长视频的训练数据匮乏。
标注难度大:对于长视频的逐帧动作和物体交互进行标注的成本非常高,限制了监督学习的效果。例如,对于一个人奔跑1分钟的视频,如何描述路边景物、天气等信息,都会成为标注中的难点。
视频生成模型目前仍面临许多挑战,但其发展速度非常迅猛,越来越多的模型能够生成更长时间的视频。相信在不久的将来,技术将不断突破,带来更多可能。
关注不迷路(*^▽^*),暴富入口==》 https://bbs.csdn.net/topics/619691583



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











