






Hadoop2.x集群的安装主要包括两个核心NameNode(一个主节点),DataNode(多个从节点),NameNode有三个作用:(1)管理HDFS文件系统的无数据信息,如文件的名称、文件大小、建立时间、修改时间、存储位置等;(2)存储HDFS的逻辑关系,也可以理解为文件目录,即文件与块节点的映射关系;(3)存储用户对文件的操作日志。DataNode的作用主要是用于存储文件。
Hadoop的运行模式主要有三种:
• 单机模式。默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。这对调试非常有帮助。
• 伪分布式模式。Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行。
• 完全分布式模式。具有实际意义的Hadoop集群,其规模可从几个节点的小集群到几千个节点的超大集群。
3.1 基础学习:Hadoop2.x完全分布式实验环境安装
所谓“万事开头难”,Hadoop2.x集群实验环境的安装放倒了不少新手,没有安装好实验环境导致后面的内容没法学习,于是乎只有放弃了。在本节中,主要介绍Hadoop2.x的完全分布模式。
3.1.1 硬件环境
至少满足以下配置的普通PC机三台:
处理器:二核1.7G+ 硬盘:40G+ 内存:768M+ 网络:局域网
3.1.2 软件环境
(1) JDK:Java 7+,可以从Oracle官网下载Linux版本,64位。
(2) Hadoop2.x:可以从Hadoop官网http://hadoop.apache.org/core/releases.html
(3) 操作系统:CentOS,64位,下载地址:http://isoredirect.centos.org/centos/6.5/isos/
3.1.3 Linux环境安装
(1) 安装3台搭载CentOS6.5的主机,也可以用虚拟主机,并保证每台主机上有统一的登录名,如hadoop,使用客户端软件(如使用PieTTY 0.3.26、putty登录CentOS)登录到CentOS,相同的目录结构。
1)更改hostname,将每台主机名改成便于管理的名字:vi /etc/sysconfig/network 修改hostname
2)更改hosts,在作为namenode节点的主机上配置IP与主机名的对应关系:vi /etc/hosts,如:
192.168.8.11 master
192.168.8.12 slave12
192.168.8.13 slave13
3)关闭防火墙
service iptables stop
chkconfig iptables off
(2) 安装JDK在每台主机上安装JDK,需把准备好的jdk-7u55-linux-x64.tar.gz放到Linux系统中,当然可以采用wget方法直接下载,也可采用WinSCP上传。说下WinSCP的文件上传吧。
step1:下载安装WinSCP,如果不会下载安装,先百度啦。
step2:打开WinSCP,如图4-1:
图3-1 WinSCP界面
step3:在主机名处输入主机的IP地址,也可输入名(但需要设置hosts),输入用户名及登录密码,单击“登录”按钮,出现如图4-2:
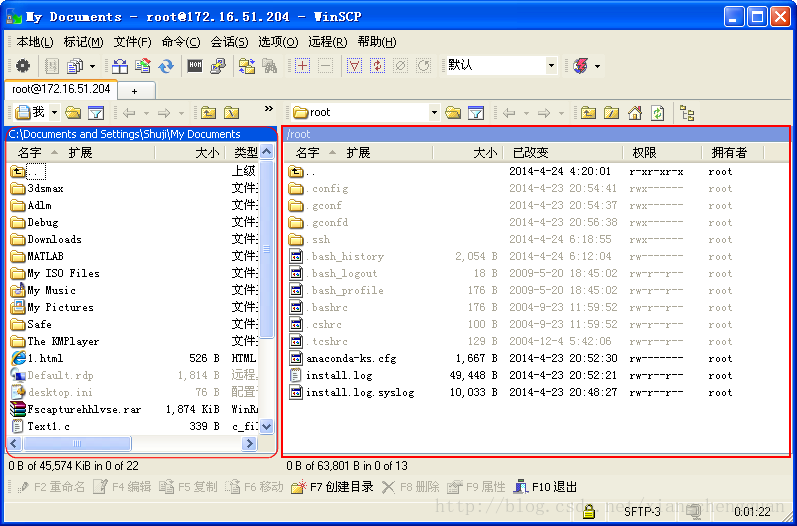
图4-2 WinSCP操作界面
note:左侧圆角框所示为本地Windows系统目录结构,右侧直角框所示为Linux目录结构。
step4:在左侧找到等上传的jdk-7u71-linux-x64.gz,在右侧找到目标位置,这里选择的是/home/hadoop目录,将左侧的jdk-7u71-linux-x64.gz拖至右侧即可。
接下来的工作就是到Linux系统上安装JDK啦,
1)安装JDK
找到/usr目录,并建立一个目录java,命令:
cd /usr
mkdir java
将刚才上传的文件移动到/usr/java下,命令:
mv /home/hadoop/jdk-7u71-linux-x64.gz /usr/java/jdk-7u71-linux-x64.gz
进入目录/usr/java,命令:
cd /usr/java
用ls查看一下目录下的文件,确认/jdk-7u71-linux-x64.gz已经存在后,使用命令:
用tar命令解压安装JDK,命令:
tar -zxvf jdk-7u55-linux-x64.tar.gz
2)配置JAVA环境变量
step2:按下i键进入编辑模式,加入以下内容:
export JAVA_HOME=/usr/java/jdk1.7.0_71
export PATH=.:$JAVA_HOME/bin:$PATH
step3:按ESC键后再输入:wq保存退出。
step4:使用source命令在当前bash环境下读取并执行profile中的命令,如下:
source /home/hadoop/.bash_profile
step5:确认,使用java -version出现以下提示,则说明JDK安装成功。
java version "1.7.0_71"Java(TM) SE Runtime Environment (build 1.7.0_71-b14)
Java HotSpot(TM) 64-Bit Server VM (build 24.71-b01, mixed mode)
并将其分发到各datanode结点上,命令:
scp -rf /usr/java/ root@slave12:/usr/java
scp /home/hadoop/.bash_profile root@slave12:/home/hadoop/.bash_profile
(3)配置主机名称
使用root用户配置主机名,将作为namenode的结点命名为:master,命令:
vi /etc/sysconfig/network
写入:
HOSTNAME=master
其他的datanode,如12结点命名为:slave12,命令:
vi /etc/sysconfig/network
写入:
HOSTNAME=slave12(4)用root用户 配置hosts,是为了在安装HDFS时直接引用主机名,将主机的IP映射为主机名,便于安装HDFS时使用主机名,方便管理。
vi /etc/hosts
加入:
192.168.8.11 master
192.168.8.12 slave12
192.168.8.13 slave13
其他的datanode 也要如此配置。
(5) 设置ssh登录(很关键)
cd /home/hadoop
ssh-keygen -t rsa
一路回车,生成id_rsa.pub等文件。
chmod 0700 .ssh
用命令ls -a查看,存在.ssh文件夹。
在其他datanode结点上, 进入ssh目录,cd .ssh,做相同的工作,如下:
将namenode结点的id_rsa.pub拷贝到各datanode节点的相同目录下,执行touch /root/.ssh/authorized_keys (如果已经存在这个文件, 跳过这条),chmod 600 ~/.ssh/authorized_keys (# 注意: 必须将~/.ssh/authorized_keys的权限改为600, 该文件用于保存ssh客户端生成的公钥,可以修改服务器的ssh服务端配置文件/etc/ssh/sshd_config来指定其他文件名),cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys (将id_rsa.pub的内容追加到 authorized_keys 中, 注意不要用 > ,否则会清空原有的内容,使其他人无法使用原有的密钥登录)
在namenode上验证: ssh slaver12,出现下面提示表示成功:
Last login:Thu Apr 23 06:11:34 from 192.168.1.11
(6)Hadoop集群的HDFS文件系统主要通过心跳机制来判断各DataNode的在线情况,所以需要设置在NameNode节点与DataNode节点上设置时钟同步。分别在各主机上配置时间同步,命令:
crontab -e
插入内容:
0 1 * * * /usr/sbin/ntpdate us.pool.ntp.org #us.pool.ntp.org是时钟同步网址,0 1 * * * 之间均有空格
(7)关闭NameNode节点与各DataNode节点的防火墙,切换到root用户下,执行命令:
service iptables stop
3.1.4 安装Hadoop2.x
将下载的hadoop-2.5.1.tar.gz上传至namenode节点主机的/home/hadoop目录下,也可直接用wget命令下载到此目录下。wget http://apache.claz.org/hadoop/core/hadoop-2.5.2/hadoop-2.5.2.tar.gz
(1)进入目录/home/hadoop目录下,解压hadoop-2.5.2.tar.gz。命令:
tag -xvf hadoop-2.5.2.tar.gz
(2)在目录/home/hadoop目录下建立文件夹mydata,命令:
mkdir mydata
(3)在文件hadoop-env.sh中配置Hadoop2.x运行时的JDK环境变量,命令:
vi /home/hadoop/hadoop-2.5.1/etc/hadoop/hadoop-env.sh
文件打开后,将:export JAVA_HOME=${JAVA_HOME}修改为:export JAVA_HOME=/usr/java/jdk1.7.0_71,也就是JAVA_HOME的路径。
(4)在文件yarn-env.sh中配置yarn所需的JDK环境变量,命令:
vi /home/hadoop/hadoop-2.5.1/etc/hadoop/yarn-env.sh
文件打开后,找到#export JAVA_HOME=/home/y/libexec/jdk1.6.0,将其改了:export JAVA_HOME=/usr/java/jdk1.7.0_71,并去除注释符号#。
(5)在文件core-site.xml中配置核心组件,命令:
vi /home/hadooop/hadoop-2.5.1/etc/hadoop/core-site.xml
完整配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/mydata</value>
</property>
</configuration>(6)在文件hdfs-site.xml中配置文件系统,命令:
vi /home/hadoop/hadoop-2.5.1/etc/hadoop/hdfs-site.xml
完整配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value><!--1代表一个副本-->
</property>
</configuration>(7)在文件yarn-site.xml中配置文件系统,命令:
vi /home/hadoop/hadoop-2.5.1/etc/hadoop/yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>(8)复制mapred-site.xml.template为mapred-site.xml,并在文件mapred-site.xml中配置计算框架,命令:
cp /home/hadoop/hadoop-2.5.1/etc/hadoop/mapred-site.xml.template /home/hadoop/hadoop-2.5.1/etc/hadoop/mapred-site.xml
vi /home/hadoop/hadoop-2.5.1/etc/hadoop/mapred-site.xml
完整配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> (9)在文件slaves中配置DataNode节点,命令:
vi /home/hadoop/hadoop-2.5.1/etc/hadoop/slaves
在slaves中填写DataNode节点名称,一行填写一个DataNode名称,如:
slave12
slave13
(10)分发Hadoop-2.5.1文件夹至各DataNode节点主机,命令:
scp -r /home/hadoop/hadoop-2.5.1 hadoop@slave12:/home/hadoop/hadoop-2.5.1
scp -r /home/hadoop/hadoop-2.5.1 hadoop@slave13:/home/hadoop/hadoop-2.5.1(11)在NameNode节点与各DataNode节点主机上的文件/home/hadoop/.bash_profile文件中配置Hadoop集群启动的系统环境变量,命令:
vi /home/hadoop/.bash_profile
在文件的最后一行加入以下内容:
export HADOOP_HOME=/home/hadoop/hadoop-2.5.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH(12)在NameNode节点主机上执行格式化HDFS文件系统的命令:
hdfs namenode -formatcd /home/hadoop/hadoop-2.5.1
sbin/start-all.sh还可以通过Web UI方式查看进程是否启动成功。在浏览器地址栏中输入Http://master:50070即可查看,当然需要在本机上的hosts文件中加入:
192.168.8.11 master
192.168.8.12 slave12
192.168.8.13 slave13
成功时再现图4-3所示界面。
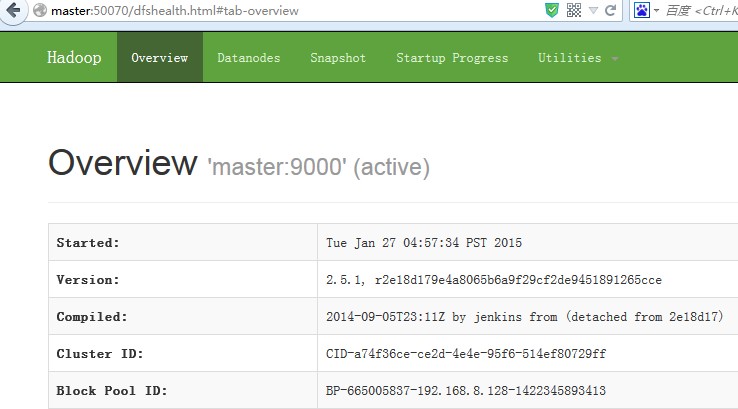
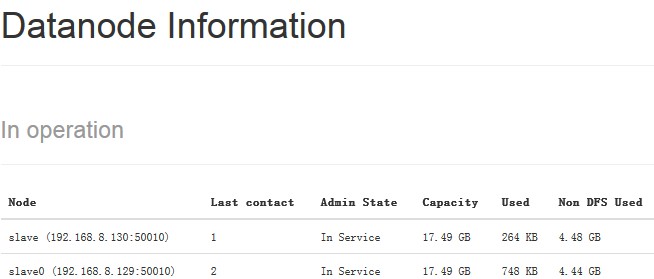
图4-3 web ui提示界面
3.1.5 我的第一个Hadoop运算——PI
进入hadoop-2.5.1目录下的示例文件夹,命令:
cd /home/hadoop/hadoop-2.5.1/share/hadoop/mapreduce执行命令:
hadoop jar hadoop-mapreduce-examples-2.5.1.jar pi 10 10

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









