







概述
什么是容器?
容器是用于盛放元素的
由于盛有许多的元素,容器都是可以迭代遍历的
最常用的容器包括【元组】、【列表】、【字典】、【集合】等
字符串是有序字符集,本质上也是容器
我们在对比和讨论容器的特性时,最常考虑的因素有:
1、是否有序
2、是否可重复
3、如何访问其中的元素
4、是否可以编辑
5、如何遍历
第一节:字符串
字符串操作符
+,用于字符串连接*,用于多次重复
例如:
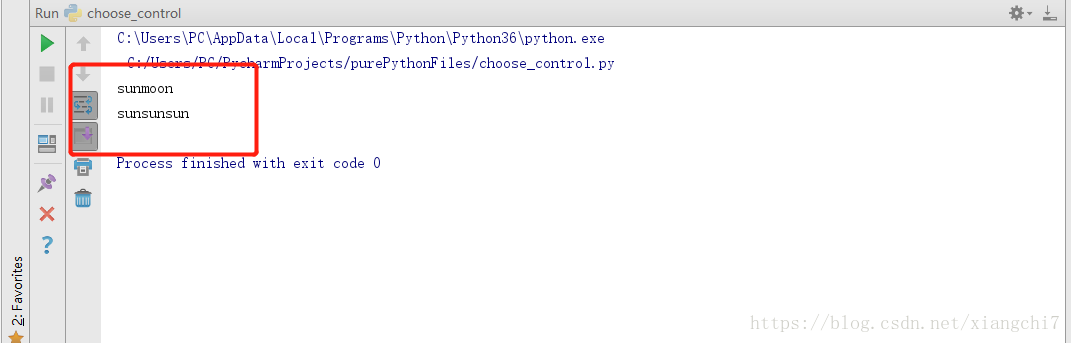
words = "sun"
words2 = "moon"
print(words + words2)
print(words * 3)
执行结果:
字符串长度
如果我们想知道一段字符串到底有多长,可以用len()进行查看,而不是一个一个数
例:
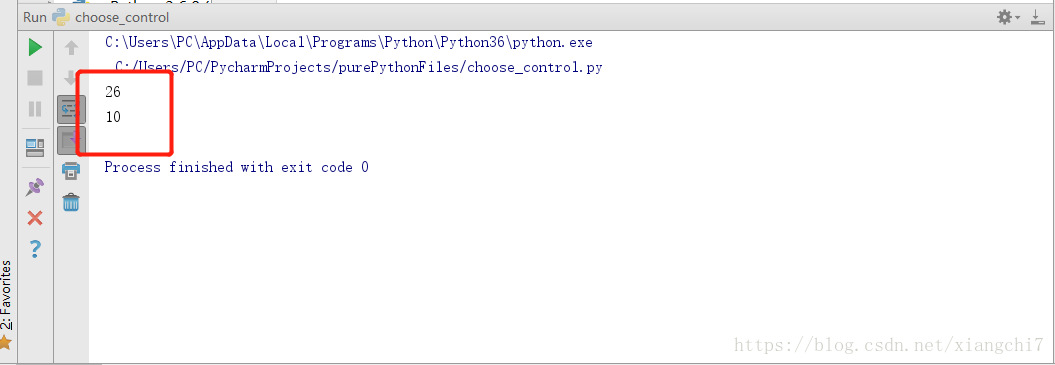
#这里有26个字母,或者更多时,使用len()
words = "abcdefghijklmnopqrstuvwxyz"
print(len(words))
#字符串的长度,包含了空格在内
words2 = "I love you"
print(len(words2))
执行结果:
比较字符串大小
字符串之间的比较,是按当前字符集中序号的顺序排列,前小后大
print("abc" > "def") # False,按当前字符集中序号的顺序排列
print("中国" > "美帝") # False,按当前字符集中序号的顺序排列
字符串截取(切片)
字符串[开始位置:结束位置:步长]
开始结束位置的原则是:含头不含尾,即结束位置的那个字符不会被截取
步长2代表每2个取第一个,3代表每三个取第一个
步长为-N时,代表从后向前截取,仍然是每N个取一个
例如:
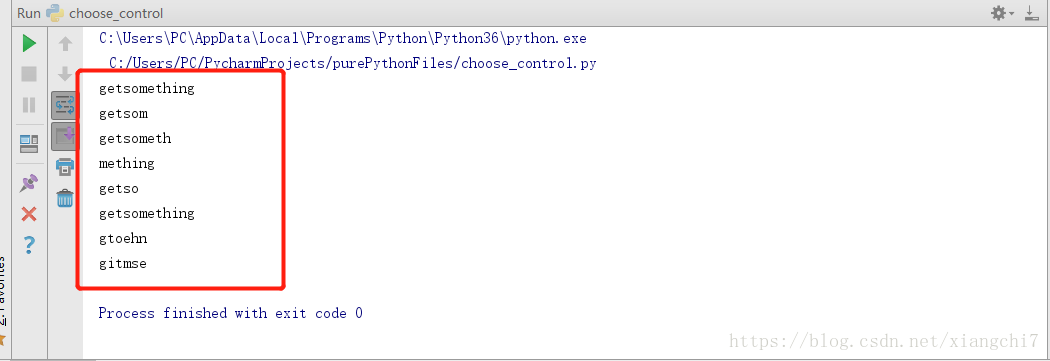
mstr = "getsomething"
# 从0载取到总长度(最后)
print(mstr[0:len(mstr)])
#从0截取到第5位(注意含头不含尾,所以以6做结束)
print(mstr[0:6])
#从0截取到倒数第4位
print(mstr[0:-3])
#从第5位截取到最后
print(mstr[5:])
#从0截取到第4位
print(mstr[:5])
#从头截到尾
print(mstr[:])
#从0截取到最后,步长为2
print(mstr[0::2])
#从头截到尾,步长为-2
print(mstr[::-2])
执行结果:
判断有无子串
- 使用
in关键字可以判断子串是否在大串中 - 使用
find函数返回子串出现的位置,如子串不存在则返回-1 - 使用
index函数同样返回子串位置,但子串不存在就会报错
例如:
mstr = "天下武功唯快不破"
#"武功"是否在mstr里面
print("武功" in mstr) # True
#"武术"是否在mstr里面
print("武术" in mstr) # False
#在mstr里寻找"不破"
print(mstr.find("不破")) # 6
#在mstr里寻找"武术"
print(mstr.find("大破")) # -1
#在mstr里出现""武功的下标是?
print(mstr.index("武功")) # 2
print(mstr.index("武术")) #此方法找不到会报错
字符串的格式化
capitalize(),首字母大写title(),每个单词的首字母大写lower(),全小写upper(),全大写
例如:
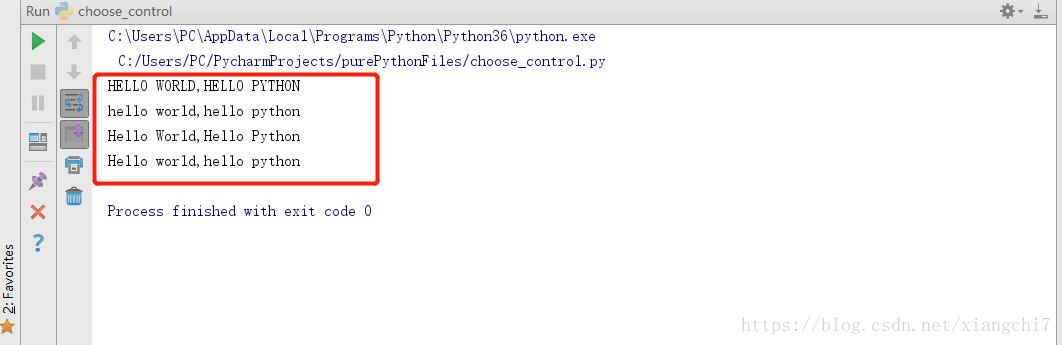
mStr = "hello world,hello python"
#字母全大写
print(mStr.upper())
#字母全小写
print(mStr.lower())
#所有单词首字母大写
print(mStr.title())
#仅开头首字母大写
print(mStr.capitalize())
执行结果:
编码解码
encode(),编码为字节decode(),将字节解码为字符串,注意主语是字节而非字符串
例如:
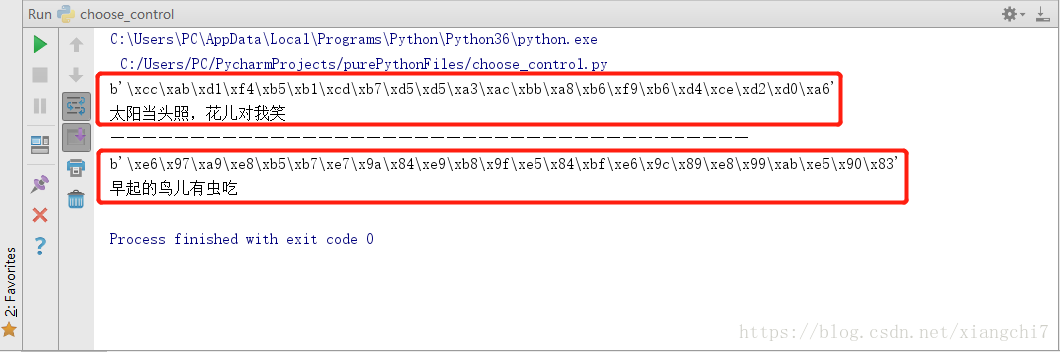
#例1
words = "太阳当头照,花儿对我笑"
#以gbk字符集编码将字符串编码为字节数组
wordBytes = words.encode(encoding="gbk")
print(wordBytes)
#以gbk字符集编码将字节数组解码为字符串
turnBytes = wordBytes.decode(encoding="gbk")
print(turnBytes)
print("——"*20)#此处只为分隔
例2:
words2 = "早起的鸟儿有虫吃"
#以utf-8字符集编码将字符串编码为字节数组
wordBytes2 = words2.encode(encoding="utf-8")
print(wordBytes2)
#以utf-8字符集编码将字节数组解码为字符串
turnBytes2 = wordBytes2.decode(encoding="utf-8")
print(turnBytes2)
执行结果:
搜索与替换
find(),寻找子串位置,没有返回-1index(),寻找子串位置,没有报错count(),统计子串出现次数replace(),替换子串为新的字符串
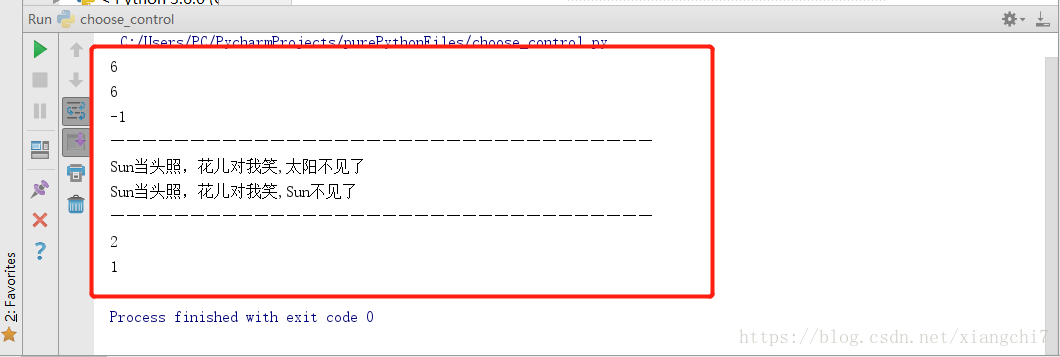
例如:
mStr = "太阳当头照,花儿对我笑,太阳不见了"
#搜索“花儿”的位置
print(mStr.find("花儿"))
#搜索出现“花儿”的下标
print(mStr.index("花儿"))
#搜索“flower”的位置,-1表示子串不存在
print(mStr.find("flower"))
#搜索出现“flower”的下标位置,注意当子串不存在,将会报错,而不是返-1
# print(mStr.index("flower")) # ValueError: substring not found
print("——————————————————————————————————")#此处只为分隔
#将“太阳”替换为Sun,替换1处
print(mStr.replace("太阳", "Sun", 1))
#将全部“太阳”替换为“Sun”
print(mStr.replace("太阳", "Sun")) # fuck world,fuck python 全部hello替换为fuck
print("——————————————————————————————————")#此处只为分隔
#数一数子串“太阳”出现的次数
print(mStr.count("太阳"))
#在0-6位字符中,子串“太阳”出现的次数
print(mStr.count("太阳", 0, 6)) # 1 hello子串出现的次数,范围为0-6位字符
执行结果:
判断头尾与数字
isdigit(),判断是否为数字子串startswith(),判断是否以子串开头endswith(),判断是否以子串结尾
例如:
words = "太阳当头照,花儿对我笑"
words2 = "3145926"
#判断words是不是数字字符串
print(words.isdigit()) # False
#判断words2是不是数字字符串
print(words2.isdigit())  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2485
2485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









