







专栏目录
- 1-MySQL原理-设计架构
- 2-MySQL原理-InnoDB架构与内存管理
- 3-MySQL原理-InnoDB架构与数据一致性
- 4-MySQL原理-SQL执行原理
- 5-MySQL原理-存储引擎与索引结构
- 6-MySQL原理-索引匹配原则
- 7-MySQL原理-事务底层实现
- 8-MySQL原理-MySQL回表与解决方案
- 9-MySQL原理-执行计划最全详解
- 10-MySQL原理-索引失效索引匹配最全详解
自适应哈希索引(ahi)
Adaptive Hash index属性使得InnoDB更像是内存数据库。该属性通过innodb_adapitve_hash_index开启,也可以通过—skip-innodb_adaptive_hash_index参数关闭
Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,建立哈希索引可以带来速度的提升
经常访问的二级索引数据会自动被生成到hash索引里面去(最近连续被访问三次的数据),自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。
哈希(hash)是一种非常快的等值查找方法,在一般情况下这种查找的时间复杂度为O(1),即一般仅需要一次查找就能定位数据。
而B+树的查找次数,取决于B+树的高度,在生产环境中,B+树的高度一般3-4层,故需要3-4次的查询。
innodb会监控对表上个索引页的查询。如果观察到建立哈希索引可以带来速度提升,则自动建立哈希索引,称之为自适应哈希索引(Adaptive Hash Index,AHI)。
AHI有一个要求,就是对这个页的连续访问模式必须是一样的。
例如对于(a,b)访问模式情况:
where a = xxx
where a = xxx and b = xxx
特点
1、无序,没有树高
2、降低对二级索引树的频繁访问资源,索引树高<=4,访问索引:访问树、根节点、叶子节点
3、自适应
缺陷
1、hash自适应索引会占用innodb buffer pool;
2、自适应hash索引只适合搜索等值的查询,如select * from table where index_col=‘xxx’,而对于其他查找类型,如范围查找,是不能使用的;
3、极端情况下,自适应hash索引才有比较大的意义,可以降低逻辑读。
异步IO(AIO)
异步IO对应的是同步IO。
异步IO的优点是:
- 减少IO的等待时间,例如3次IO,只需要等1个IO时间
- 合并IO操作,减少随机IO
例如我们要查询3个页,(space,page_no)分别是(8,6),(8,7),(10,9)
- 如果使用同步IO,我们需要发送3次IO请求,然后等待3次IO时间,明显这是比较耗时的。
- 如果使用异步IO,我们一次性发送3个IO请求,然后等待IO结果。AIO发现前两个IO是连续的,所以可以合并为从8,7开始取16*2KB数据,把3个IO合并为2个,然后只需要1次IO操作时间。
刷新邻近页
在刷新脏页的时候,把相邻的脏页一起刷新。(减少随机IO)相邻是指两个页在磁盘中属于同一个区。底层就是减少随机IO的次数。
SQL语句执行流程
逻辑架构图
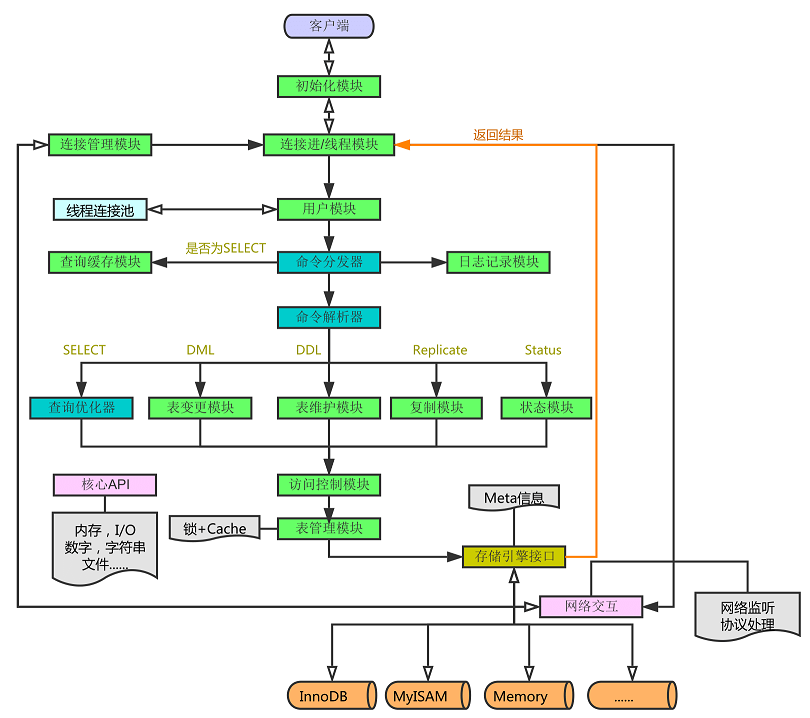
整个架构分为两层,上层是MySQLD的被称为的‘SQL Layer’,下层是各种各样对上提供接口的存储引擎,被称为‘Storage Engine Layer’。
查询执行流程
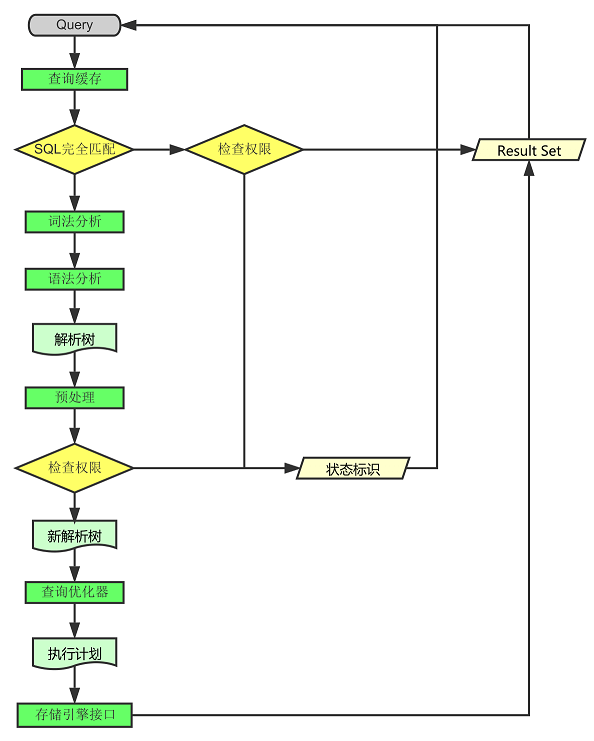
组件
查询缓存(MySQL 8.0 版本后移除)
查询缓存主要用来缓存我们所执行的 SELECT 语句以及该语句的结果集。
连接建立后,执行查询语句的时候,会先查询缓存,MySQL 会先校验这个 sql 是否执行过,以 Key-Value 的形式缓存在内存中,Key 是查询语句,Value 是结果集。如果缓存 key 被命中,就会直接返回给客户端,如果没有命中,就会执行后续的操作,完成后也会把结果缓存起来,方便下一次调用。当然在真正执行缓存查询的时候还是会校验用户的权限,是否有该表的查询条件。
MySQL 查询不建议使用缓存,因为查询缓存失效在实际业务场景中可能会非常频繁,假如你对一个表更新的话,这个表上的所有的查询缓存都会被清空。对于不经常更新的数据来说,使用缓存还是可以的。
所以,一般在大多数情况下我们都是不推荐去使用查询缓存的。
MySQL 8.0 版本后删除了缓存的功能,官方也是认为该功能在实际的应用场景比较少,所以干脆直接删掉了。
分析器
MySQL 没有命中缓存,那么就会进入分析器,分析器主要是用来分析 SQL 语句是来干嘛的,分析器也会分为几步:
第一步,词法分析,一条 SQL 语句有多个字符串组成,首先要提取关键字,比如 select,提出查询的表,提出字段名,提出查询条件等等。做完这些操作后,就会进入第二步。
第二步,语法分析,主要就是判断你输入的 sql 是否正确,是否符合 MySQL 的语法。
完成这 2 步之后,MySQL 就准备开始执行了,但是如何执行,怎么执行是最好的结果呢?这个时候就需要优化器上场了。
优化器
优化器的作用就是它认为的最优的执行方案去执行(有时候可能也不是最优),比如多个索引的时候该如何选择索引,多表查询的时候如何选择关联顺序等。
可以说,经过了优化器之后可以说这个语句具体该如何执行就已经定下来。
执行器
当选择了执行方案后,MySQL 就准备开始执行了,首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会去调用引擎的接口,返回接口执行的结果。
流程
1.连接
1.1客户端发起一条Query请求,监听客户端的‘连接管理模块’接收请求
1.2将请求转发到‘连接进/线程模块
1.3调用‘用户模块’来进行授权检查
1.4通过检查后,‘连接进/线程模块’从‘线程连接池’中取出空闲的被缓存的连接线程和客户端请求对接,如果失败则创建一个新的连接请求
2.处理
2.1先查询缓存,检查Query语句是否完全匹配,接着再检查是否具有权限,都成功则直接取数据返回
2.2上一步有失败则转交给‘命令解析器’,经过词法分析,语法分析后生成解析树
2.3接下来是预处理阶段,处理解析器无法解决的语义,检查权限等,生成新的解析树
2.4再转交给对应的模块处理
2.5如果是SELECT查询还会经由‘查询优化器’做大量的优化,生成执行计划
2.6模块收到请求后,通过‘访问控制模块’检查所连接的用户是否有访问目标表和目标字段的权限
2.7有则调用‘表管理模块’,先是查看table cache中是否存在,有则直接对应的表和获取锁,否则重新打开表文件
2.8根据表的meta数据,获取表的存储引擎类型等信息,通过接口调用对应的存储引擎处理
2.9上述过程中产生数据变化的时候,若打开日志功能,则会记录到相应二进制日志文件中
3.结果
3.1Query请求完成后,将结果集返回给‘连接进/线程模块
3.2返回的也可以是相应的状态标识,如成功或失败等
3.3连接进/线程模块’进行后续的清理工作,并继续等待请求或断开与客户端的连接
所有文章都是以专栏系列编写,建议系统性学习,更容易成为架构师!
博主每天早晚坚持写博客给与读者价值提升,为了让更多人受益,请多多关照,如果觉得文章质量有帮助到你,请关注我的博客,收藏此文,持续提升,奥利给!
另外我不打算靠运营方式拿到博客专家的认证,纯纯的科技与狠活来征服读者,就看读者的感恩之心了,祝你好运连连。

















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











