







概念
在单链表中有了next指针,这就使得我们要查找的下一结点的时间复杂度为O(1)。可是如果我们要查找的是上一结点的话,那么最坏的时间复杂度就是O(n),因此我们每次都要从头遍历开始查找。
为了克服单向性这一缺点,设计出了双向链表(double linked list)是在单链表的每个结点中,在设置一个指向其前驱结点的指针域。 所以在双链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
//线性表的双向链表的存储结构
typedef struct DulNode
{
ElemType data;
struct DulNode *prior; //直接前驱指针
struct DulNode *next; //直接后驱指针
}DulNode,*DuLinkList;
既然单链表也可以有循环链表,那么双链表也可以是循环链表。
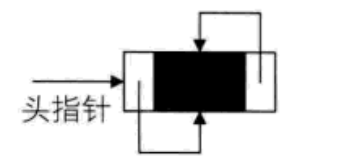
双向链表的循环带头结点的空链表如下图。
非空的循环的带头结点的双向链表如下图
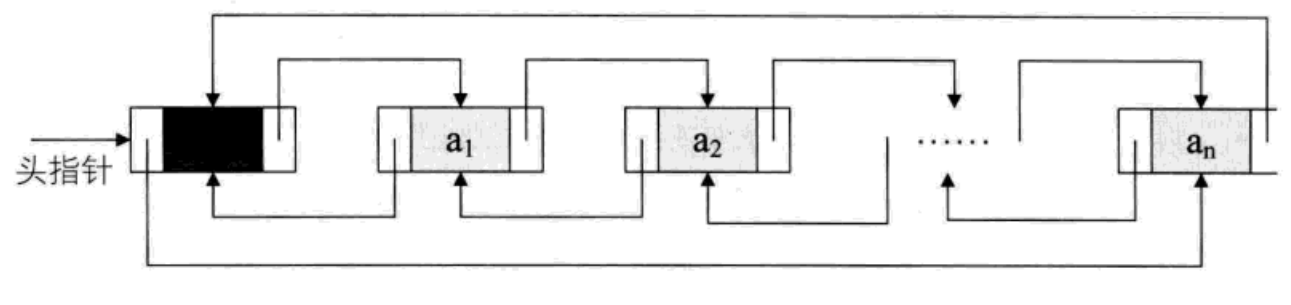
由于这是双向链表,那么对于链表中每一个结点p,它的后继的前驱是谁?当然还是他自己,它的前驱的后继自然也自己。
p->next->prior = p = p=->prior->next
双向链表是单链表中扩展出来的结构,所以它的很多操作是和单链表相同的,比如求长度,查找元素,获得元素的位置等。这些操作都只要涉及一个方向的指针即可。
插入元素
插入的操作,其实并不复杂,不过顺序很重要。
假设存储元素e的结点为s,要实现将结点s插入到结点p和p->next之间需要下面几步:
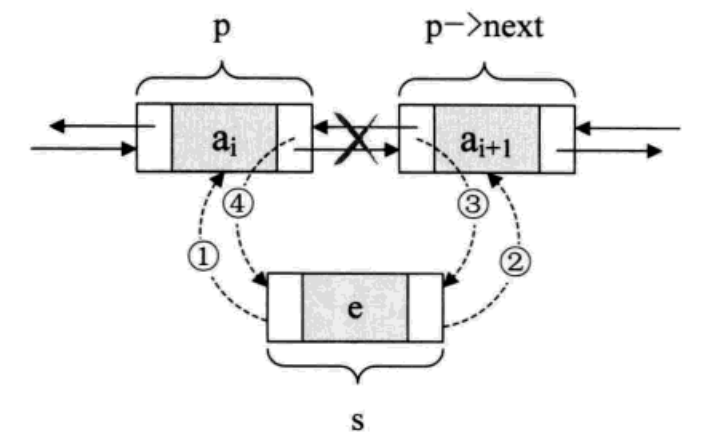
s->prior = p; //把p赋值给s的前驱
s->next = p->next; //把p->next赋值非s的后继
p->next->prior =s; //把s赋值给p->next的前驱
p->next =s; //把s赋值非p的后继
关键在于他们的顺序,由于第二步和第三步都用到了p->next。如果第四步先执行,则会使p->next提前变成了s,使得插入的工作完不成。所以我们不妨把上面的图的基础上理解,顺序是先搞定s的前驱和后继,在搞定后结点的前驱,最后解决前结点的后继。
删除操作
如果插入操作理解了,那么删除操作,就很简单。
若要删除结点p,只需要下面的两个步骤:
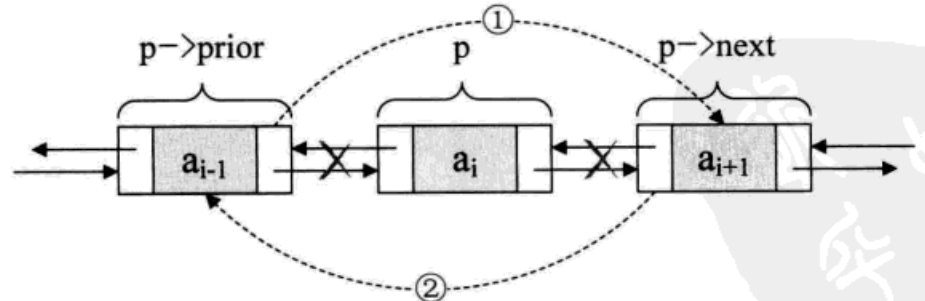
p->prior->next=p->next; //把p->next赋值给p->prior的后继
p->next->prior=p->prior; //把p->prior赋值给p-》next的后继
free(p); //释放结点
总结
双向链表相对于单链表来说,要更复杂一些,毕竟它多了一个prior指针,对于插入和删除时,需要注意。另外他由于每个结点都需要记录两份指针,所以在空间上占用多一点,不过,由于它良好的对称性。使得对某个结点的前后结点的操作,带来了方便,可以有效提高算法的时间性能,说简单点,就是用空间来换取时间。















 1941
1941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









