






awk 的基础认识及用法
1.原理:
(1)awk程序启动执行BEGIN{}
(2)流式的处理文本
(3)执行END{}
2.语法:
awk [选项参数] ‘script’ var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
3.基本用法:
行:叫作记录 { print $0}
列:叫作域,字段(从左向右123456…域), { print $1 ,$2}
打印变量不能加$符号,直接打印。
{ print ARTC} { print FS}
打印普通用户:
[root@bogon test]# awk -F: ‘{if ($3>=1000) print $0}’ passwd
4.参数:
-F : 指定文本分割符 默认空格或tab
指定单个分隔符:-F:
指定多个分隔符:-F ‘[ %]+’
-v : 定义变量
-f : 指定awk的命令文本,当awk的匹配规则比较复杂时,可将其写入到文件,通过-f参数引用文件。
[root@bogon test]# cat test.awk
BEGIN{
var1=“UID:”;
var2=“USERNAME:”;
}
{
print var2,$1,var1,$3
}
END{
print “---------结束-----------”
}
[root@bogon test]# awk -F: -f test.awk passwd

格式化输出printf:
d格式:用来输出十进制整数。有以下几种用法:
%d:按整型数据的实际长度输出。
%md:m为指定的输出字段的宽度。如果数据的位数小于m,则左端补以空格,若大于m,则按实际位数输出s格式:用来输出一个串。有几中用法
%s:例如:printf("%s", “CHINA”)输出"CHINA"字符串(不包括双引号)
%ms:输出的字符串占m列,如果字符串本身长度大于m,则突破获m的限制,将字符串全部输出。若串长小于m,则左补空格。
%-ms:如果串长小于m,则在m列范围内,字符串向左靠,右补空格。
%m.ns:输出占m列,但只取字符串中左端n个字符。这n个字符输出在m列的右侧,左补空格。
%-m.ns:其中m、n含义同上,n个字符输出在m列范围的左侧,右补空格。如果n>m,则自动取n值,即保证n个字符正常输出。
5. 内置参数:
(1)VRGC:统计参数个数
命令:0 -F: ‘ ’ :1 其余,2,3
[root@localhost ~]# awk -F: '{print ARGC}' /etc/passwd

(2)VRGV:参数数组
[root@localhost ~]# awk -F: '/^root/{print ARGV[0]}' /etc/passwd
awk
[root@localhost ~]# awk -F: '/^root/{print ARGV[1]}' /etc/passwd
/etc/passwd

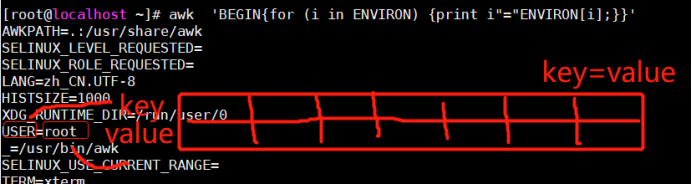
(3)ENVIRON:外部环境变量的列表
[root@localhost ~]# awk -F: '/^root/{print ENVIRON[0]}' /etc/passwd
[root@localhost ~]# awk 'BEGIN{for (i in ENVIRON) {print i"="ENVIRON[i];}}'
(4) FILENAME:输出文件名
[root@localhost ~]# awk -F: '/^root/{print FILENAME}' /etc/passwd

(5)FNR:输入记录所在的行数 行就是记录 (recond:记录)
[root@bogon test]# awk -F: '/root/{print FNR}' passwd
NR:输出的记录所在行数
[root@bogon test]# awk 'BEGIN{FS=":"} /root/{print NR}' passwd
[root@bogon test]# awk -F: 'NR==1 {print $1}' passwd #第一行的第一列

(6)OFS: 输出字段分割符,默认是空格 (field: 域 字段)
[root@bogon test]# awk 'BEGIN{FS=":"} /^root/{print OFS}' passwd 理解
[root@bogon test]# awk 'BEGIN{FS=":";OFS=","} /^root/{print $1,$2}' passwd

FS: 定义分割符,默认是空格或者制表符
[root@bogon test]# awk 'BEGIN{FS=":"} /root/{print $1,FS}' passwd
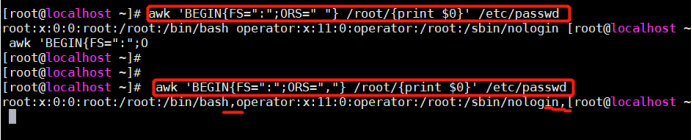
 (7)ORS: 输出记录分割符,默认是换行,若修改将会把修改值添加到行后,默认值不变。
(7)ORS: 输出记录分割符,默认是换行,若修改将会把修改值添加到行后,默认值不变。
[root@bogon test]# awk 'BEGIN{FS=":";ORS=" "} /root/{print $0}' passwd
[root@bogon test]# awk 'BEGIN{FS=":";ORS=","} /root/{print $0}' passwd
[root@bogon test]# awk 'BEGIN{FS=":";ORS=";"} /root/{print $0}' passwd
RS: 输入记录换行符,默认是\n
[root@bogon test]# awk 'BEGIN{FS=":";RS=" "} /root/{print $0}' passwd
(8)OFMT: 输出格式
[root@bogon test]# awk 'BEGIN{FS=":"} /root/{print OFMT}' passwd

(9)RT:记录终止符 -v:定义变量 (termination:终止)
[root@bogon test]# awk -v RS='[0-9]+' '{s+=RT}END{print s}' file

(10)RSTART: 查看match函数第一个匹配到的索引
RLENGTH:查看match函数第一个匹配长度
[root@bogon test]# awk ‘match(
0
,
/
[
a
−
z
]
+
0,/[a-z]+
0,/[a−z]+/){print RSTART,RLENGTH}’ file

(11)IGNORECASE: 匹配正则要不要区分大小写,区分0(默认),不区分1.
[root@bogon test]# awk -F: ‘BEGIN{IGNORECASE=1}/root/{print }’ file

(12)SUBSEP 字符用于分隔多个标在数组中的元素(模拟的二维数组的索引),默认是空格
awk中没有二维数组,所以只能使用一维数组来模拟,下面的例子模拟了一个二维数组,并打印每个数组的下标和值。
awk ’
BEGIN {
for (i = 1; i <= 2; i++)
for (j = 1; j <= 3; j++)
array[i,j] = i * j * 10
for (x in array)
print x, array[x]
}’
awk ’
BEGIN {
SUBSEP = “:”
for (i = 1; i <= 2; i++)
for (j = 1; j <= 3; j++)
array[i,j] = i * j * 10
for (x in array)
print x, array[x]
}’

(13)ARGIND: 当前文件的ARGV索引正在处理中
ARGV,ARGC
实例:对比两个文件中,存在于b而不存在于a的记录。
[root@bogon test]# vim a
[root@bogon test]# vim b
[root@bogon test]# awk ‘ARGIND==1 {a[$0]} ARGIND>1&&!($0 in a) {print $0}’ a b
代码解释:
ARGIND1{a[$0]}
#ARGIND1 判断是否正在处理第一个文件,本例为文件a
{a[$0]} 初始化(或叫做定义)a[$0]
ARGIND>1&&!($0 in a){print $0}
#ARGIND>1 判断是否在处理第二个或第n个文件,本例只有一个文件b
#并且判断a[$0]是否未定义,然后打印$0
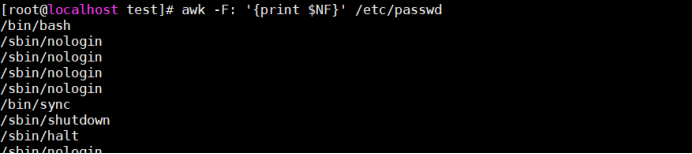
(14) NF:域的总个数
打印最后一个域:
[root@bogon test]# awk -F: ‘{print $NF}’ passwd
[root@bogon test]# awk -F: ‘{print $(NF-1)}’ passwd

6.格式化输出:printf
{printf %s \n $1}
{printf %-20s \n $1}
{printf %20s \n $1}
{printf %20s,%d \n $1,$3}
{printf %20s,%-5d \n $1,$3}
{printf "username: "%20s,"UOD: "%-5d \n $1,$3}
7.自定义变量:
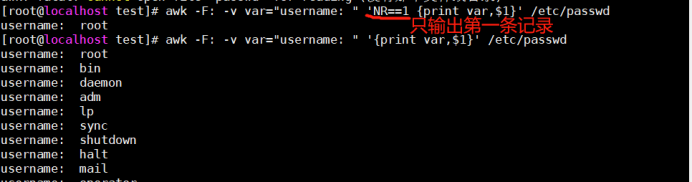
[root@bogon test]# awk -v var=“hello world” ‘{print var}’ passwd

[root@bogon test]# awk -F: -v var="username: " ‘NR1 {print var,$1}’ passwd
[root@bogon test]# awk -F: 'BEGIN{var="username: "} NR1 {print var,$1}’ passwd
[root@bogon test]# awk -F: -v var=“username:” -v var1=“user1” -v var=“user2” ‘NR1 {print var,$1}’ passwd
[root@bogon test]# awk -F: 'BEGIN{var="username: ";var1=“user1”;var2=“user2”} NR1 {print var,$1}’ passwd
8.正则匹配:

9.统计:
动作action要用花括号括起来 (indexes:索引 pv:访问量 string:字符串)

实例:统计apache服务访问量的top10
“淘宝 —> 商品”—IP —Top1000 ---->华北:800,东北:100,华南:80,西北:20 —》定点推广。
[root@bogon httpd]# awk '/^[0-9]/{print $1}' access_log |sort |uniq -c |sort -rn |head -2
[root@bogon httpd]# awk '{array[$1]++} END{for (i in array) print "IP:",i,"访问量:",array[i]}' access_log |sort -rn -k4 |head -2
“实例数组索引唯一性的特征来去重,然后对data++。输出的索引值将是IP,array[IP]是统计个数”
统计文本的单词数量:(将单词放到数组的索引中)
第一步:取单词 awk -F “[: /]” ‘{print $1}’ /etc/passwd
第二步:

第三步:排列取前三

只取单词:
awk -F "[: \/]" '{for (i=1; i<=NF;i++) if ($i~"[a-zA-Z]+") array[$1]++} END{for (i in array) print array[i],i}' /etc/passwd |sort -k1 -rn |head -3
[root@bogon test]# awk -F "[: \/]" '{for(i=1;i<=NF;i++) count[$i]++} END{for (i in count) {print i,count[i]}}' passwd
if双重判断:&& || !
[root@bogon test]# awk ‘{ if (NR <15 && $NF~“bash”) print $0}’ passwd

替换函数 gsub
[root@bogon test]# awk -F: ‘{gsub(/root/,“admin”) ;print $0}’ passwd


取数字:
echo gjgdg79hjhhjhb787bfht$@E78jhkhugi |awk -F “[1]+” ‘{for (i=1;++){printf $i}{print “%s\n”,""}}’



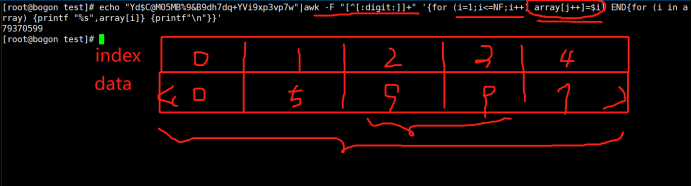

倒着打印:
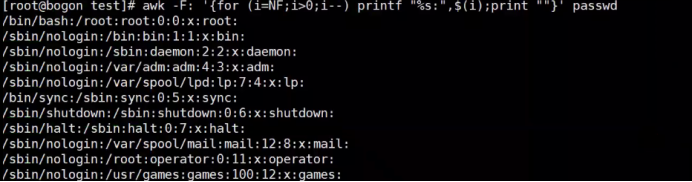 练习:
练习:

:digit: ↩︎














 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









