









Python+Selenium+Unittest+Ddt+HTMLReport分布式数据驱动自动化测试框架结构
1、Business:公共业务模块,如登录模块,可以把登录模块进行封装供调用
------login_business.py
from Page_Object.Common_Page.login_page import Login_Page
from HTMLReport import logger
import time
def login(driver, username, password):
"""
登录业务
:param driver:浏览器驱动
:param username:用户名
:param password:密码
:return:None
"""
logger().info(f"使用用户名:{username},密码:{password}进行登陆")
login_page = Login_Page(driver)
login_page.send_username(username)
login_page.send_password(password)
login_page.submit()
time.sleep(2)
----Base_url.py:对应的url地址
2、Common:与业务无关的公共模块,如对Selenium的二次封装,方便后期的调用,还有一些工具类,如在读取数据时需要对读取文件进行封装
3、PageOBject:这个就应该不用多说了,页面元素的封装,这个根据自己公司系统的业务去做分层封装(不做过多解释)
4、report:测试报告
5、TestCase:测试用例层,下面以logincase为例子
---logincase.py
import unittest
from Business.Base_url import url_index
import ddt
from Common.tools.read_txt import read_txt
from HTMLReport import logger
from Page_Object.Common_Page.index_page import Index_Page
from Common.selenium_library import SeleniumBase
from Business.login_business import login
@ddt.ddt
class Test_login(unittest.TestCase):
def setUp(self):
self.driver = SeleniumBase().get_web_driver()
def tearDown(self):
SeleniumBase(self.driver).quit()
@ddt.unpack
@ddt.data(*read_txt('TestData/login_user_password.txt'))
def test_login(self, username, password, assert_type):
se = SeleniumBase(self.driver)
se.get(url_index)
login(self.driver, username, password)
se.add_page_screen_shot()
if assert_type == '1':
logger().info("断言登陆成功")
text = Index_Page(self.driver).login_success()
self.assertIn("测试", text, '登陆成功断言')
elif assert_type == "2":
text = self.driver.find_element_by_id("submit").text
self.assertIn("立即登录", text, '登陆失败断言')
elif assert_type == "3":
text = self.driver.find_element_by_id("submit").text
self.assertIn("立即登录", text, '登陆失败断言')
elif assert_type == "4":
text = self.driver.find_element_by_id("submit").text
self.assertIn("立即登录", text, '登陆失败断言')
else:
logger().info(f"未知断言类型{assert_type}")
self.assertTrue(False, "未知断言类型")
6、TestData:测试数据,对应用例的数据都是在这里去取
7、TestSuite:测试套件,以登录套件为例
---loginsuite.py
import unittest
from TestCase.LoginCase import login_case
def return_suite():
suite=unittest.TestSuite()
loader=unittest.TestLoader()
suite.addTests(loader.loadTestsFromTestCase(login_case.Test_login))
return suite
8、browser.ini:浏览器配置文件
[local]
local_browser = False
wait_time = 10
[browser]
name = chrome
;name = firefox
;name = ie
window_width =
window_height =
[grid]
command_executor = http://127.0.0.1:4444/wd/hub
headless = False
proxy =
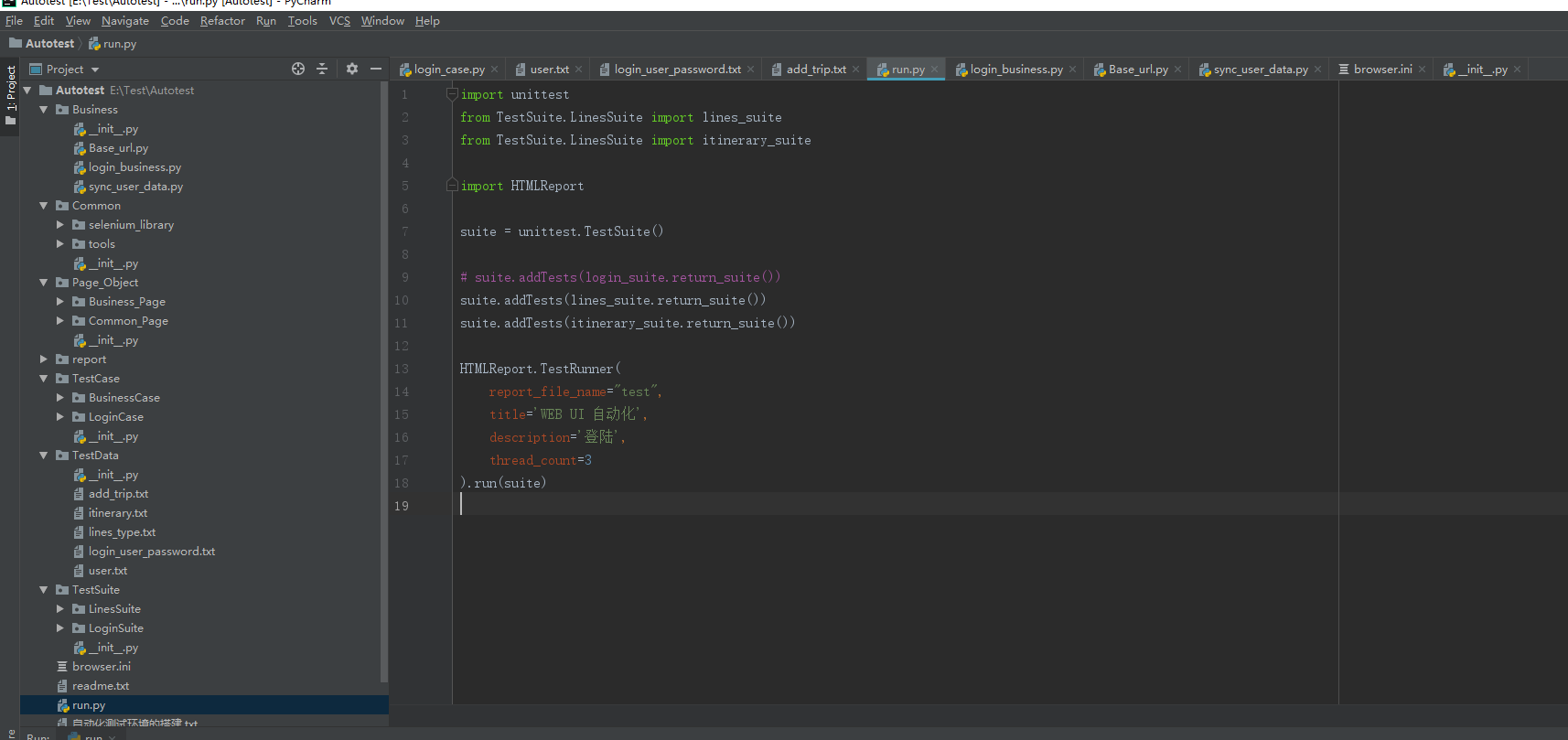
9、run.py:整体运行文件
import unittest
from TestSuite.LinesSuite import lines_suite
from TestSuite.LinesSuite import itinerary_suite
import HTMLReport
suite = unittest.TestSuite()
# suite.addTests(login_suite.return_suite())
suite.addTests(lines_suite.return_suite())
suite.addTests(itinerary_suite.return_suite())
HTMLReport.TestRunner(
report_file_name="test",
title='WEB UI 自动化',
description='登陆',
thread_count=3
).run(suite)
10、整体框架结构图:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









